---
title: Kaplan-Meier 法による生存時間分析
description: Kaplan-Meier 法で生存曲線を推定し、RMST で群間を比較するチュートリアルです。サンプルデータを使ってブラウザだけで実行できます。インストールやコーディングは不要です。
priority: 0.6
---
# チュートリアル: Kaplan-Meier 法による生存時間分析 {#tutorial-kaplan-meier-survival-curves-with-heart-failure-data}
MIDAS に組み込まれた心不全患者のサンプルデータを使い、Kaplan-Meier 法による生存時間分析を一通り体験するチュートリアルです。インストールやコーディングは不要で、ブラウザだけで実行できます。[サンプルデータを MIDAS で開く](../shared/files/tutorial-kaplan-meier-data.mds)
心不全と診断された299人の患者について、追跡期間中の生存状況を記録したデータがあります。このチュートリアルでは、Kaplan-Meier 法で生存曲線を推定し、患者背景(貧血の有無、高血圧の有無)で群分けした生存曲線を RMST(制限平均生存時間)で比較します。
1. サンプルデータを読み込み、データの構造を確認します
2. 生存時間データの特徴(打ち切り)を説明します
3. 全体の生存曲線を推定します
4. 貧血の有無で群分けし、生存曲線を比較します
5. RMST の結果を読みます
6. 他の群変数でも比較します
## データを読み込む {#load-the-data}
ランチャー画面の Sample Data セクションから **Heart Failure** をクリックしてください。プロジェクトが作成され、データが読み込まれます。
[この状態を MIDAS で開く](../shared/files/tutorial-kaplan-meier-data.mds)
このデータは、Faisalabad Institute of Cardiology(パキスタン)で2015年に収集された心不全患者の臨床記録です([Chicco & Jurman, 2020](#ref-chicco-jurman-2020))。
## データの構造を確認する {#examine-the-data-structure}
Data Table タブを開くと、299行13列のデータが表示されます。
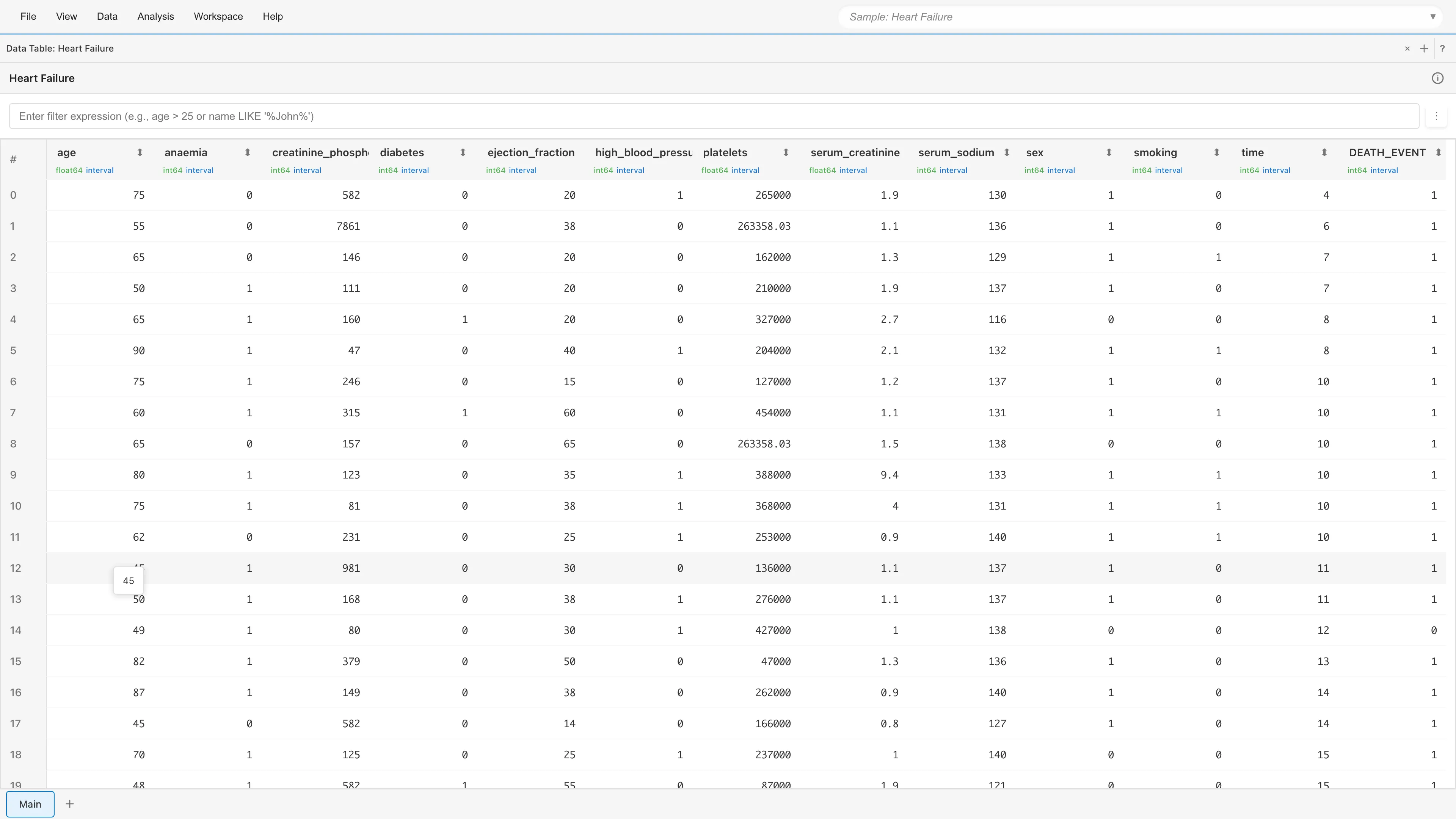
生存分析に使う主な列は次の3種類です。
### 時間変数とイベント変数 {#time-and-event-variables}
| 列名 | 内容 |
|------|------|
| `time` | 追跡期間(日数)です。診断から最後の観察(死亡または打ち切り)までの日数を記録しています |
| `DEATH_EVENT` | 追跡期間中に死亡したかどうかです。1 = 死亡、0 = 生存([打ち切り](#what-is-censoring)) |
### 患者背景(群分けに使用) {#patient-characteristics-used-for-grouping}
| 列名 | 内容 |
|------|------|
| `age` | 年齢(歳) |
| `anaemia` | 貧血の有無(0: なし、1: あり) |
| `diabetes` | 糖尿病の有無(0: なし、1: あり) |
| `high_blood_pressure` | 高血圧の有無(0: なし、1: あり) |
| `sex` | 性別(0: 女性、1: 男性) |
| `smoking` | 喫煙の有無(0: なし、1: あり) |
### 検査値 {#laboratory-values}
残りの5列(`creatinine_phosphokinase`, `ejection_fraction`, `platelets`, `serum_creatinine`, `serum_sodium`)は血液検査の結果です。このチュートリアルでは使いませんが、Cox 回帰で共変量として使えます。
## 打ち切りとは {#what-is-censoring}
299人の患者のうち、追跡期間中に死亡した患者(`DEATH_EVENT = 1`)と、追跡終了時にまだ生存していた患者(`DEATH_EVENT = 0`)がいます。後者を **打ち切り(censoring)** と呼びます。
打ち切られた患者の生存時間は `time` 日以上であることは確定していますが、その先いつイベントが起きるかは分かりません。
打ち切りを単純に除外すると、長期間生存していた打ち切り患者の情報が失われ、死亡した患者のデータだけから生存時間を推定することになります。結果として生存時間を過小推定します。Kaplan-Meier 法は「少なくともここまで生存していた」という不完全な情報もリスク集合の計算に反映させて生存曲線を推定します。
この推定が妥当であるためには、打ち切りの発生がイベントの起きやすさと無関係である(非情報的打ち切り)必要があります。打ち切りの数理的な扱いは[生存分析の基礎](concepts-survival#time-to-event-data-and-censoring)を参照してください。
## 全体の生存曲線を推定する {#estimate-the-overall-survival-curve}
メニューバーから **Analysis > Survival Analysis > Kaplan-Meier...** を選択します。Kaplan-Meier タブが開きます。
### 変数を設定する {#set-variables}
- **Time Variable**: `time` を選択します
- **Event Variable**: `DEATH_EVENT` を選択します
**Group Variable (Optional)** は空のままにします。
**Run Analysis** をクリックします。
[この状態を MIDAS で開く](../shared/files/tutorial-kaplan-meier-overall.mds)
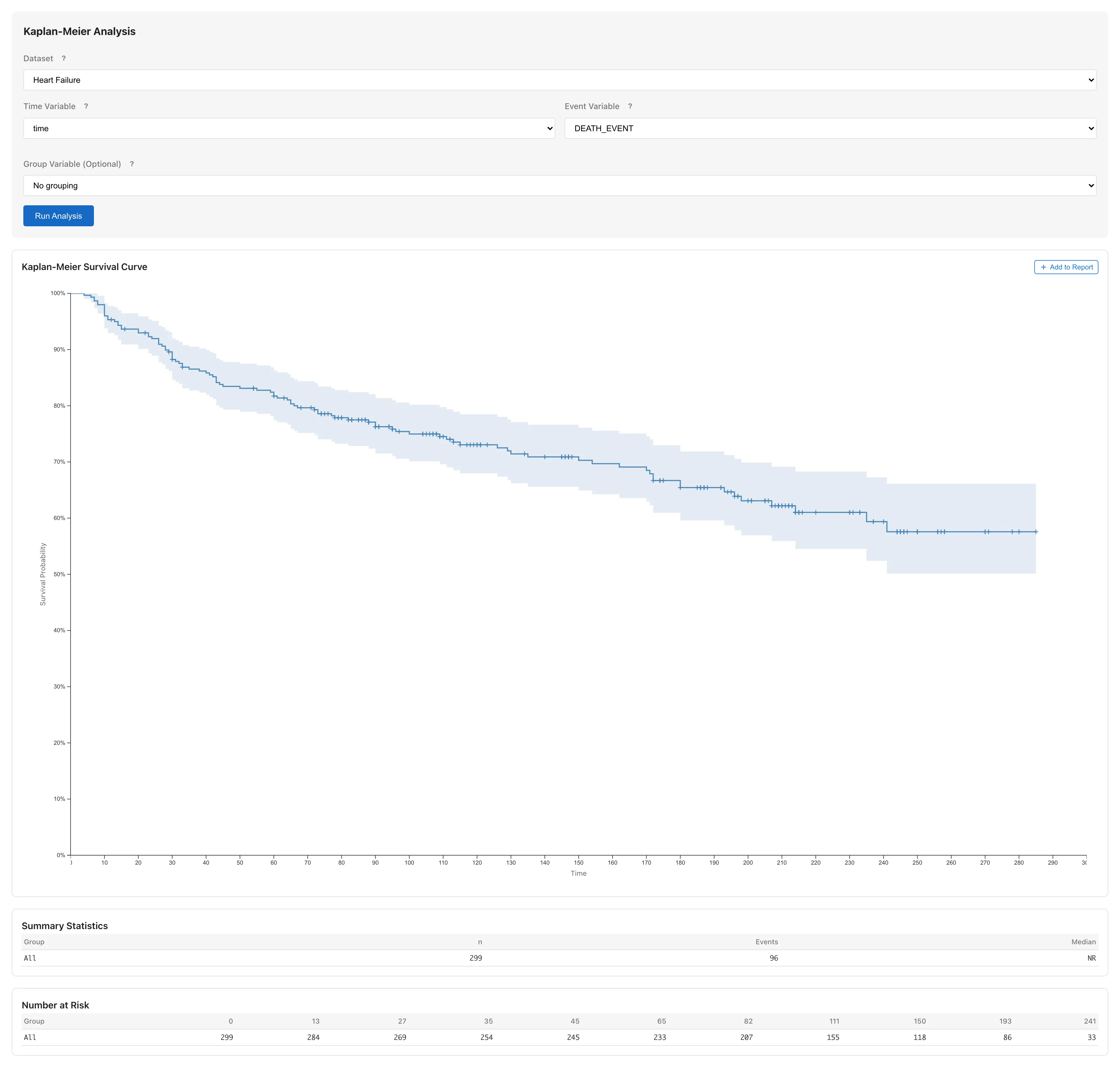
### 生存曲線を読む {#read-the-survival-curve}
横軸が追跡期間(日数)、縦軸が生存確率 $S(t)$ です。Kaplan-Meier 法は分布の形状を仮定せず、各イベント時刻での生存確率を直接推定するため、曲線は階段状のステップ関数になります。ステップが下がる位置が死亡の発生時点、曲線上の + マークが打ち切りの発生時点です。曲線の周囲の帯は、各時点の生存確率 $S(t)$ の推定値に対する95%信頼区間です(各時点で個別に構成した区間であり、曲線全体を同時に覆う帯ではありません)。
### Summary Statistics を確認する {#check-summary-statistics}
| 項目 | 意味 |
|------|------|
| n | 対象者数(299人) |
| Events | 死亡数 |
| Median | 生存時間の中央値 |
| 95% CI | 中央値の信頼区間 |
Median は、生存曲線が $S(t) = 0.5$ の水平線と交わる時点です。対象者の半数がイベントを経験するまでの時間を表し、生存時間の代表値として広く使われます。観測期間内に $S(t)$ が 0.5 を下回らなかった場合、中央値は NR (Not Reached) と表示されます。
## 貧血の有無で生存曲線を比較する {#compare-survival-curves-by-anaemia-status}
次に、貧血(anaemia)の有無によって生存曲線が異なるかを調べます。
### Group Variable を設定する {#set-the-group-variable}
**Group Variable (Optional)** のドロップダウンで `anaemia` を選択し、**Run Analysis** をクリックします。
[この状態を MIDAS で開く](../shared/files/tutorial-kaplan-meier-anaemia.mds)
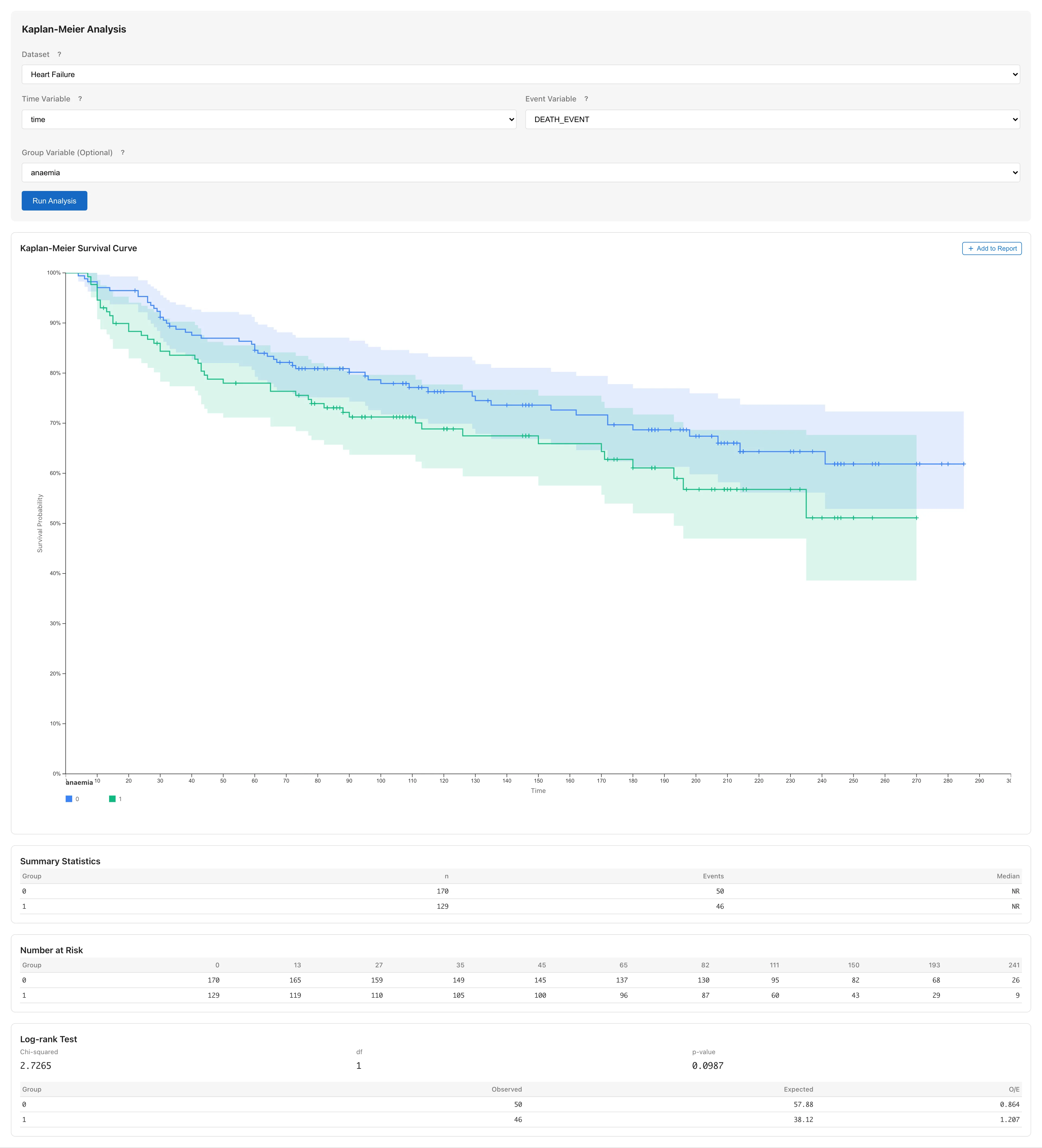
2本の生存曲線が表示されます。`anaemia = 0`(貧血なし)と `anaemia = 1`(貧血あり)のグループです。
### 曲線の見方 {#read-the-curves}
各時点での2本の曲線の間隔は、その時点における群間の推定生存確率の差です。各曲線の信頼帯はそれぞれの群の生存関数の推定精度を表すもので、帯の重なりから群間の差を判断することはできません。各群の信頼帯はその群の生存確率の不確実性を個別に示すもので、差の信頼区間とは構成が異なるためです。群間比較には RMST を使います。
### RMST の結果を読む {#interpret-the-rmst}
曲線の下に RMST(Restricted Mean Survival Time; 制限平均生存時間)の結果が群ごとに表示されます。

RMST は Kaplan-Meier 曲線の 0 から制約時点 $\tau$ までの面積で、「$\tau$ までの平均生存時間」を推定します。比例ハザード仮定を必要としないため、生存曲線が交差するような状況でも解釈が可能です([詳細](survival-analysis#rmst))。
| 列 | 説明 |
|----|------|
| Group | 群名 |
| RMST | 制限平均生存時間の推定値です。KM 曲線の $\tau$ までの面積として算出されます |
| SE | 標準誤差です。Greenwood 分散に基づいて算出されます |
| 95% CI | RMST の95%信頼区間です |
群が2つ以上ある場合、RMST テーブルの下に **RMST Difference** テーブルが表示されます。各ペアについて、RMST の差・SE・信頼区間が表示されます。RMST の差(点推定値)と信頼区間の幅から、群間の平均生存時間の差の大きさとその不確実性を読み取ります。たとえば差の推定値が 15 日、95% CI が [3, 27] であれば、$\tau$ までの平均生存時間の差は約 15 日と推定され、3 日から 27 日の範囲が推定の不確実性を表します。3群以上の場合、テーブルの見出しは **RMST Difference (Unadjusted)** に変わり、各ペアの信頼区間は多重性の調整を行っていません。
### Number at Risk テーブル {#number-at-risk-table}
生存曲線の下に Number at Risk テーブルが表示されます。各時点でリスク集合に残っている(死亡も打ち切りもされていない)患者の人数です。
時間の経過とともに数が減っていくのは、死亡と打ち切りの両方で患者がリスク集合から離脱するためです。リスク集合の人数が少ない時点では推定の不確実性が大きくなり、信頼区間の帯が広がります。
## 他の群変数で比較する {#compare-by-other-variables}
同様の手順で、高血圧(`high_blood_pressure`)や喫煙(`smoking`)でも群分けして比較できます。
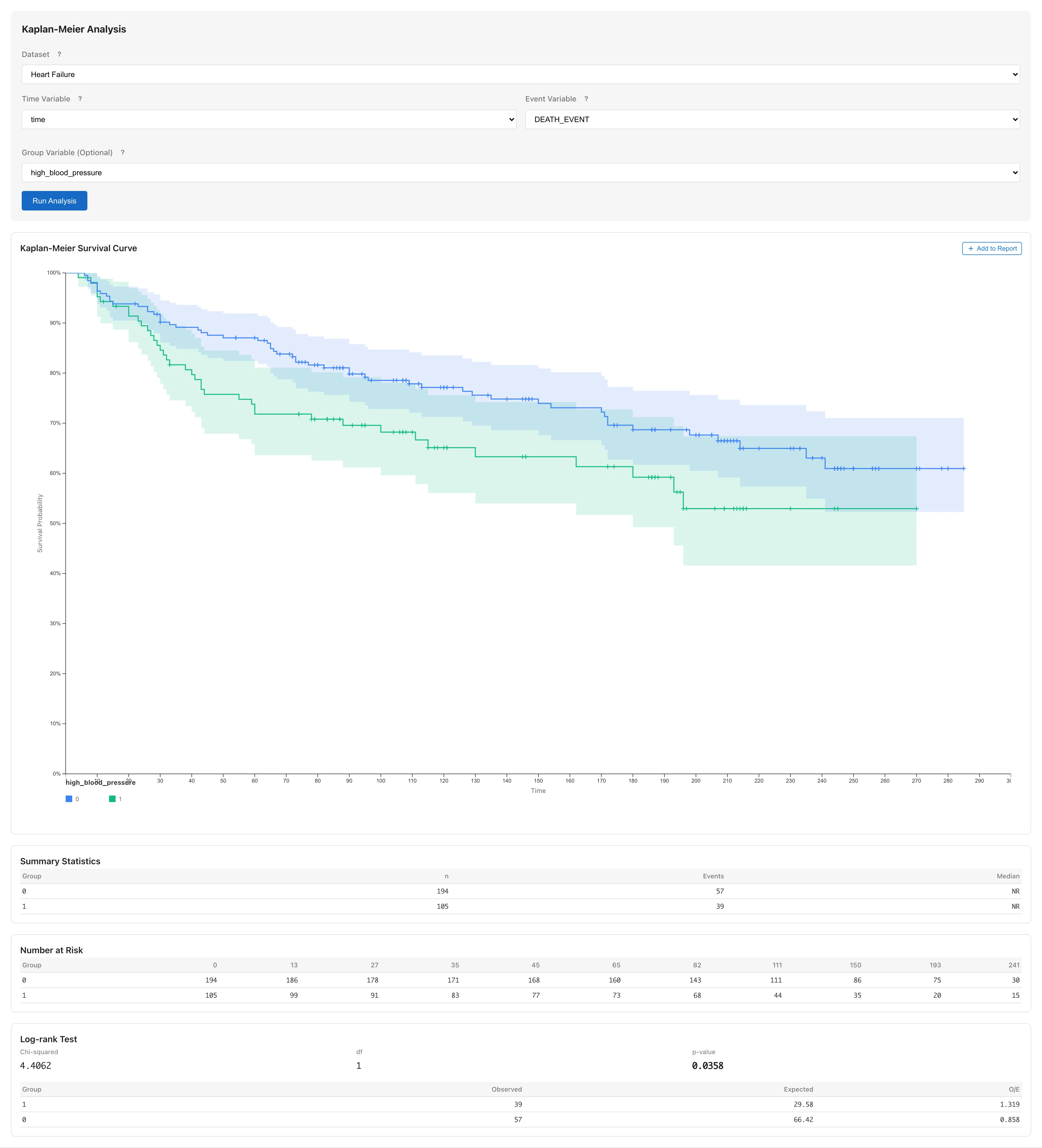
群変数を変えるたびに RMST を算出できますが、複数の群変数を試す作業は仮説の生成です。探索で見つけた知見は探索的分析として報告します。
Kaplan-Meier 法は一度に1つの群変数しか扱えません。複数の要因を同時に考慮したい場合は Cox 比例ハザードモデルを使います。たとえば「貧血の有無が生存に与える影響を、年齢の違いを考慮した上で評価したい」といった分析が可能です。Cox 回帰の使い方は[生存分析](survival-analysis#cox-regression)を参照してください。
## 結果をレポートに追加する {#add-results-to-a-report}
生存曲線を論文やプレゼンテーション用に保存するには、**Add to Report** ボタンをクリックします。表示されるダイアログで既存のレポートを選択するか新しいレポートを作成すると、生存曲線がそのレポートに追加されます。
レポートの使い方は[レポート](report)を参照してください。
## 振り返り {#summary}
- **生存時間データの構造**: 時間変数(追跡期間)とイベント変数(死亡/打ち切り)の2つが必要です
- **打ち切り**: 追跡終了時に生存していた患者も、「少なくともここまで生存」という情報として分析に含まれます
- **生存曲線の推定**: Kaplan-Meier 法は分布を仮定せず、観測データから直接生存曲線を推定します
- **群間比較**: Group Variable を設定すると、群ごとの生存曲線が描かれ、RMST の群間差で比較できます
生存分析の数理的な背景は[生存分析の基礎](concepts-survival)で説明しています。
## 参考文献 {#references}
- Chicco, D., & Jurman, G. (2020). Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. *BMC Medical Informatics and Decision Making*, 20, 16. https://doi.org/10.1186/s12911-020-1023-5
- Kaplan, E. L., & Meier, P. (1958). Nonparametric estimation from incomplete observations. *Journal of the American Statistical Association*, 53(282), 457-481. https://www.jstor.org/stable/2281868