Crosstab(クロス集計)
Crosstab は、カテゴリ変数を行と列に配置して集計するピボットテーブル機能です。データの傾向や関係性を素早く把握できます。
基本的な使い方
Crosstab を開く
メニューバーから Analysis > Crosstab Analysis... を選択すると、新しい Crosstab タブが開きます。
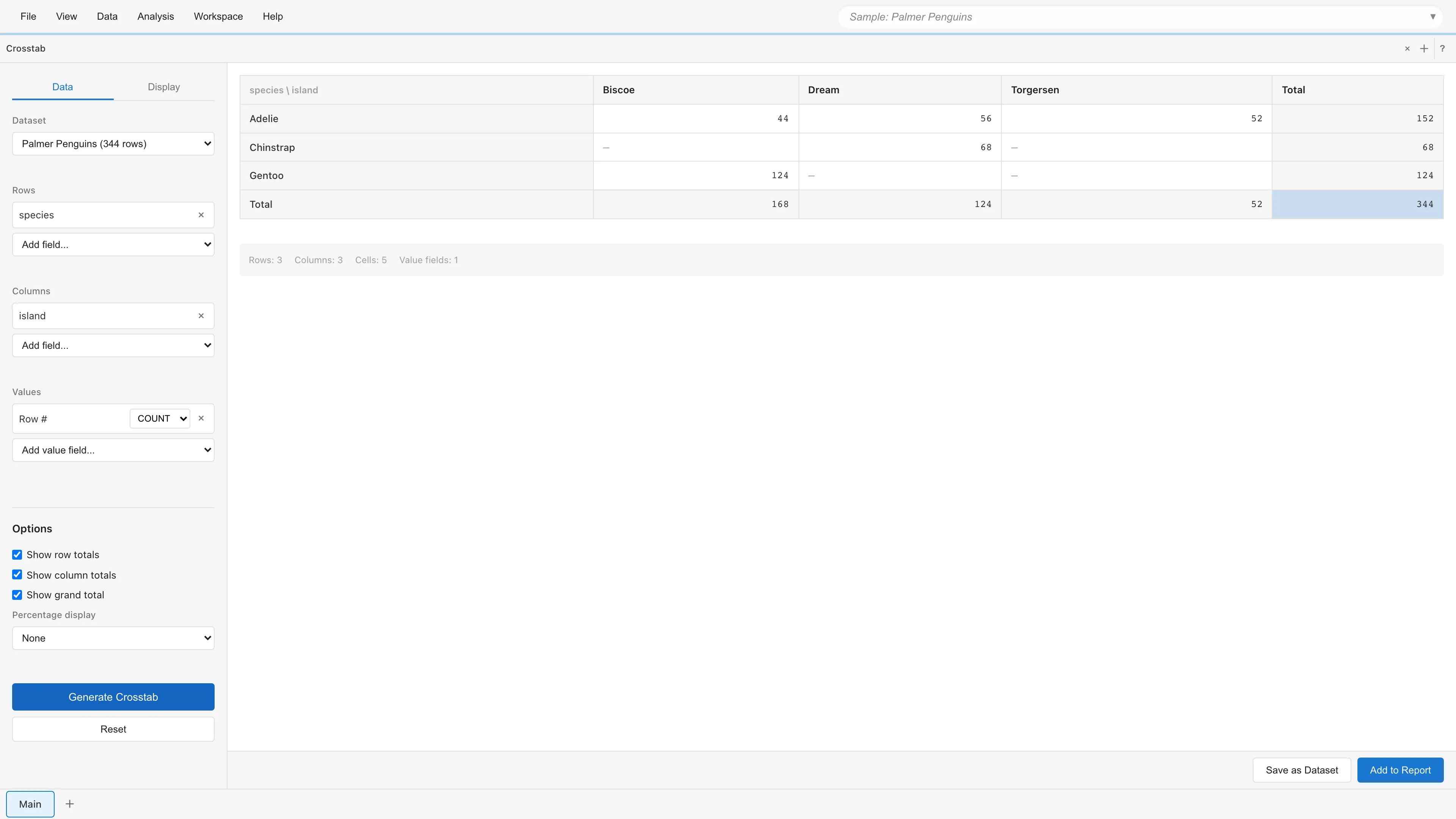
クロス集計の作成
左側の設定パネルでフィールドを指定します。
Rows には行に配置するカテゴリ変数を選択します。複数選択すると階層的な行ヘッダーになります。
Columns には列に配置するカテゴリ変数を選択します。こちらも複数選択可能です。
Values には集計する数値フィールドを選択します。集計関数(SUM、AVG、COUNT、MIN、MAX)を指定できます。
設定が完了したら、Generate Crosstab ボタンをクリックします。右側のプレビューエリアにクロス集計表が表示されます。
結果の保存
Save as Dataset ボタンをクリックすると、クロス集計の結果を新しいデータセットとして保存できます。
Add to Report ボタンをクリックすると、現在の表示状態をレポートに追加できます。
集計関数
Values フィールドでは以下の集計関数を選択できます。
- SUM(合計)
- AVG(平均)
- COUNT(件数)
- MIN(最小値)
- MAX(最大値)
表示オプション
合計の表示
Options セクションで合計の表示を制御できます。
Show row totals をオンにすると、各行の合計が右端に表示されます。
Show column totals をオンにすると、各列の合計が下端に表示されます。
Show grand total をオンにすると、全体の総計が表示されます。
パーセンテージ表示
Percentage display で数値をパーセンテージとして表示できます。
- None - パーセンテージを表示しません
- Row % - 行合計に対する割合を表示します
- Column % - 列合計に対する割合を表示します
- Total % - 総計に対する割合を表示します
なお、AVG、MIN、MAX 集計ではパーセンテージ計算は利用できません。
ソート
Display でソート方法を設定できます。
行のソート
- Original Order - データの元の順序を維持します
- Label (A-Z) - ラベルの昇順でソートします
- Label (Z-A) - ラベルの降順でソートします
- Value - 集計値でソートします
列のソート
行と同様のソートオプションが利用できます。
Value ソートでは、どの列/行の値を基準にするか、昇順(Low to High)か降順(High to Low)かを指定できます。
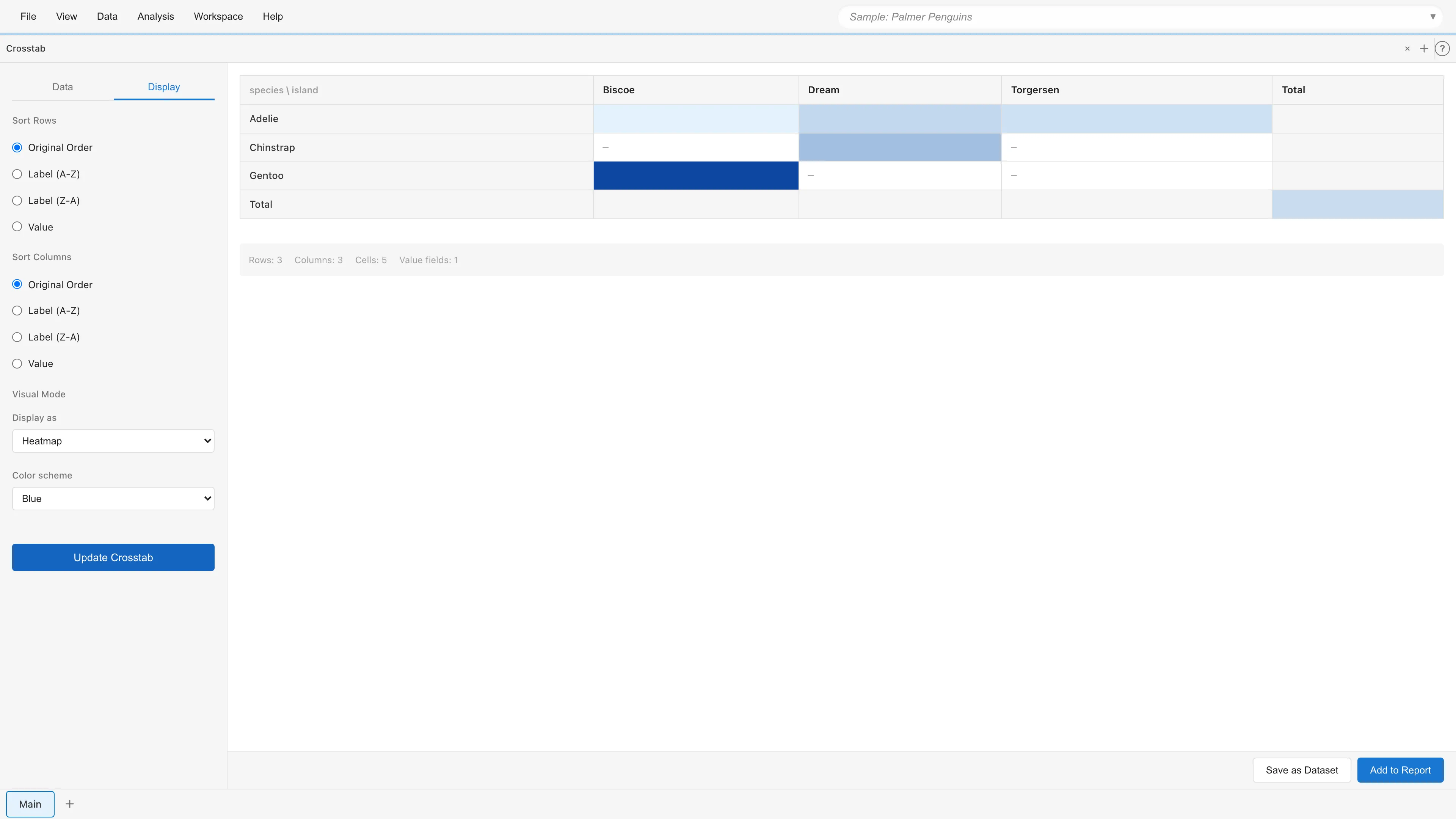
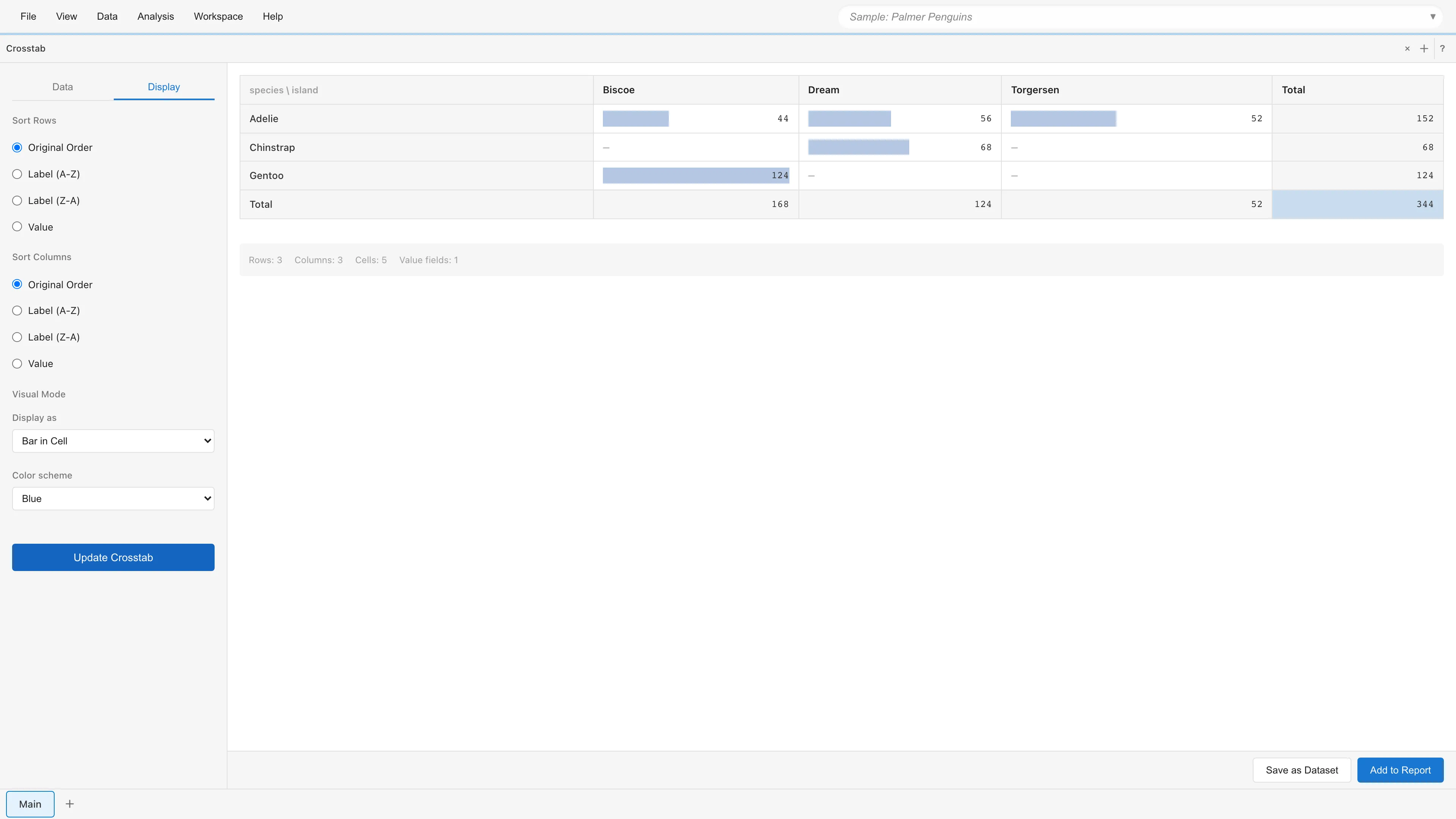
ビジュアルモード
Display の Visual Mode で表示スタイルを変更できます。値フィールドが1つの場合のみ利用可能です。
- Table - 標準的な表形式で表示します
- Heatmap - セルの背景色で値の大小を表現します
- Text + Heatmap - 数値とヒートマップを同時に表示します
- Bar in Cell - セル内に棒グラフを表示します
カラースキーム
ヒートマップモードではカラースキームを選択できます。
- Blue - 青のグラデーション
- Red - 赤のグラデーション
- Green - 緑のグラデーション
- Diverging - 赤から白を経て青へのグラデーション
セルの操作
セルの選択
セルをクリックすると、そのセルに該当する元データの行が選択状態になります。選択した行は他のビューでもハイライト表示されます。
ドリルダウン
セルをダブルクリックすると、そのセルに該当するデータだけを抽出した Filtered Data タブが開きます。
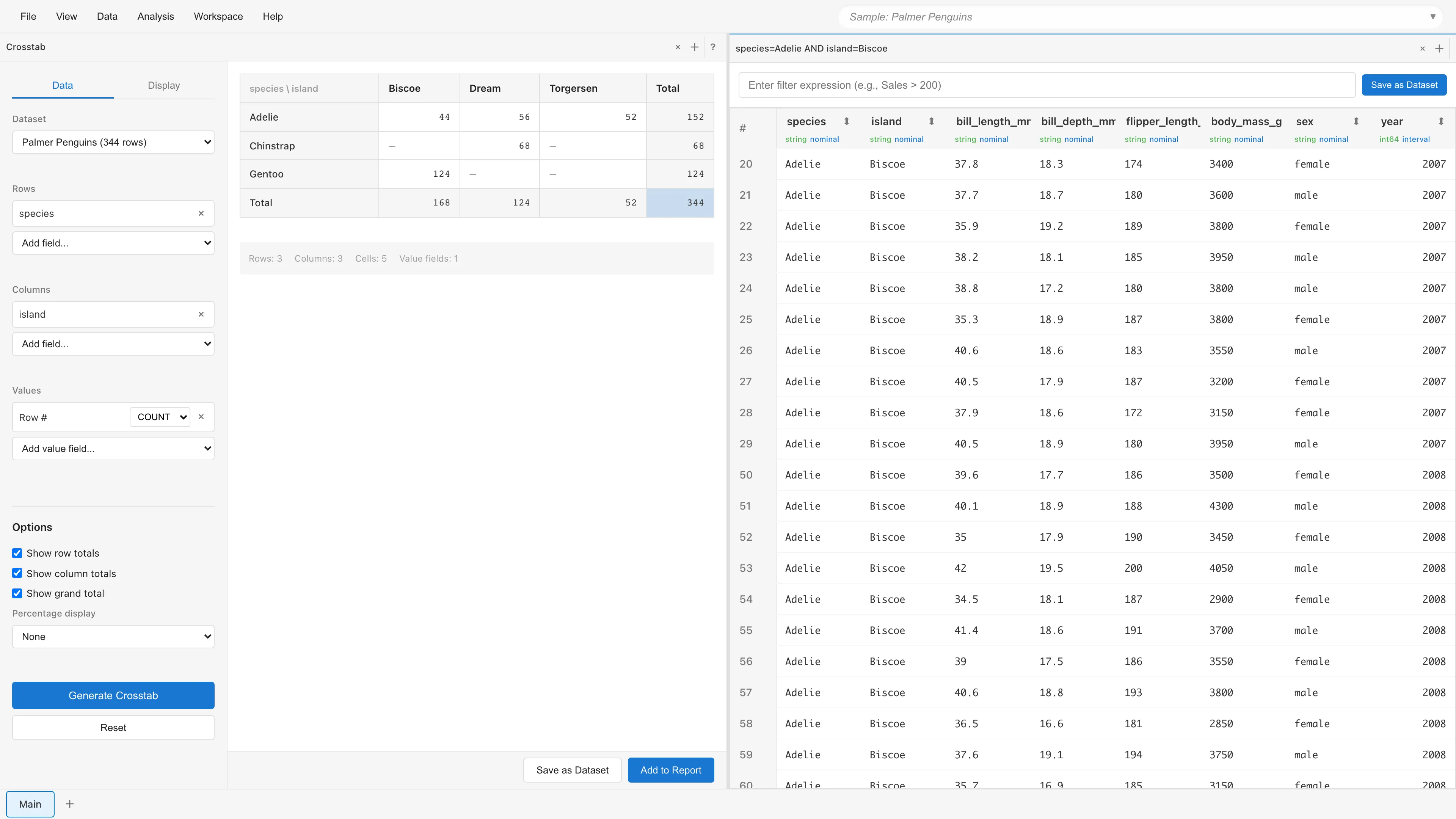
左のような Crosstab で「44」のセル(Adelie × Biscoe)をダブルクリックすると、その条件に該当する44行のデータが Filtered Data タブとして開きます。右側に表示されているのが Filtered Data タブです。
カイ二乗独立性検定
Options の Chi-square test of independence チェックボックスを有効にすると、Pearson のカイ二乗独立性検定を実行します。行フィールドと列フィールドがそれぞれ1つの場合に利用できます。
仮説
この検定は以下の仮説を評価します:
- H₀(帰無仮説): 行変数と列変数は独立である。
- H₁(対立仮説): 行変数と列変数は独立でない。
結果
結果はテーブルの下に表示されます。結果パネルには実際の変数名を使った仮説、有意水準0.05での判定、帰無仮説を棄却するかどうかの結論が表示されます。
以下の統計量が報告されます:
- カイ二乗統計量と自由度 (df)
- p 値
- Cramer's V(効果量、0から1の範囲)
検定には Values の集計関数にかかわらず、各セルの観測度数が使用されます。
期待度数の警告
期待度数が5未満のセルがある場合、該当するセルの数と割合が警告として表示されます。期待度数が低い場合、カイ二乗近似の精度が低下する可能性があります。
複数の値フィールド
Values に複数のフィールドを追加すると、各列が値フィールドごとに展開されます。たとえば、SUM(Sales) と AVG(Profit) を指定した場合、各列ヘッダーの下にそれぞれの集計値が並びます。
複数の値フィールドを使用する場合、ビジュアルモード(ヒートマップ等)は利用できません。
制限事項
ビジュアルモード(Heatmap、Text + Heatmap、Bar in Cell)は、値フィールドが1つの場合のみ利用できます。複数の値フィールドがある場合は、標準の Table モードで表示されます。