Linear Regression(線形回帰分析)
Linear Regression タブでは、最小二乗法(OLS)による線形回帰分析を実行できます。OLS は残差平方和を最小化する回帰係数 を求める手法です。数理的な背景は回帰分析の基礎を参照してください。
カウントデータや二値データなど、正規分布を仮定できない応答変数には GLM(一般化線形モデル) を使用してください。
基本的な使い方
Linear Regression を開く
メニューバーから Analysis > Linear Regression (OLS)... を選択すると、新しい Linear Regression タブが開きます。
変数の設定
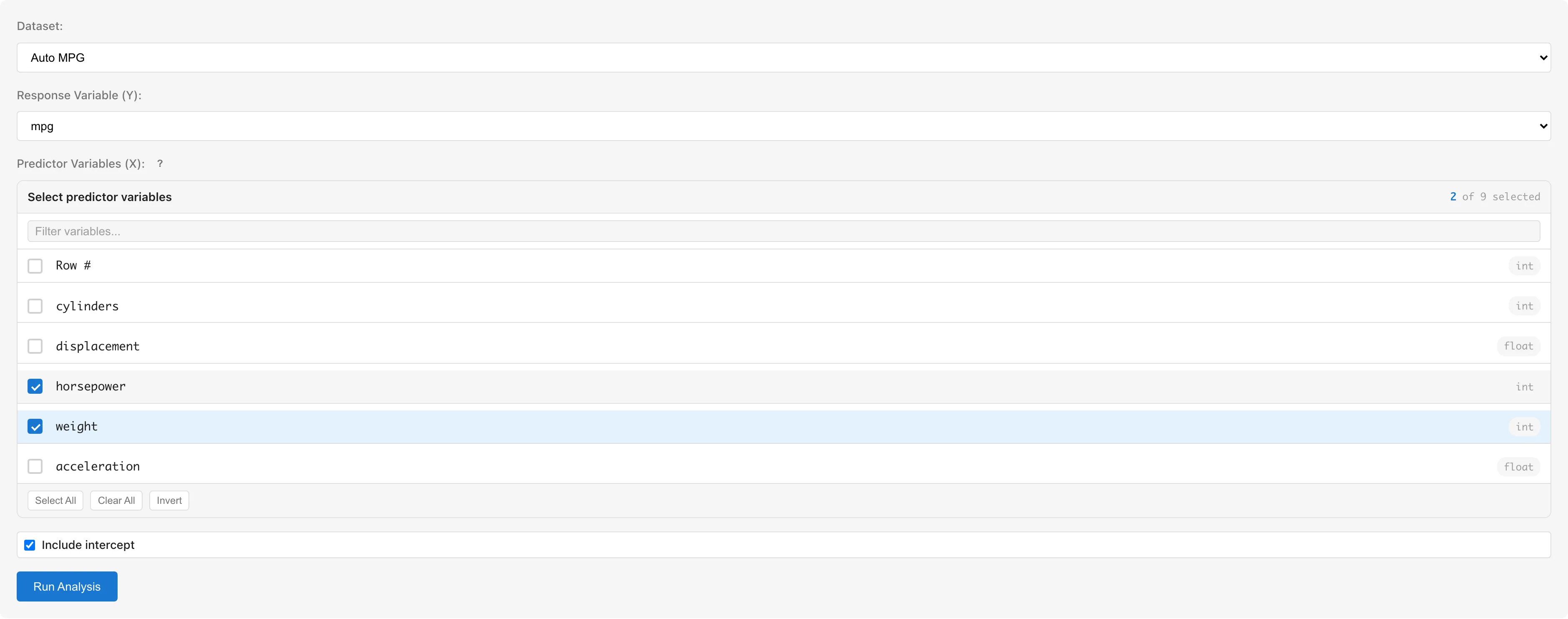
Dataset で分析対象のデータセットを選択します。
Response Variable (Y) で目的変数を選択します。数値型(int64, float64)とブール型の列を選択できます。ブール型の値は 0/1 として扱われます。日付型(date, datetime)の列と、尺度が nominal または ordinal に設定された列は選択できません。
Predictor Variables (X) で説明変数を選択します。チェックボックスで複数の変数を選択できます。選択できる列の条件は Response Variable と同じで、尺度が nominal または ordinal の列と日付型の列はグレーアウト表示されます。文字列型などのカテゴリ変数を使用する場合は、事前に Dummy Coding タブで数値変換が必要です(注意事項 を参照)。
Include intercept で切片項の有無を設定します。デフォルトでオンです。
Confidence Level で係数テーブルと Prediction & Confidence Intervals テーブルの区間推定に使う信頼水準を設定します。デフォルトは 95 で、50 から 99.99 までの値を入力できます。
設定が完了したら、Run Analysis ボタンをクリックして分析を実行します。
結果の見方
Model Summary
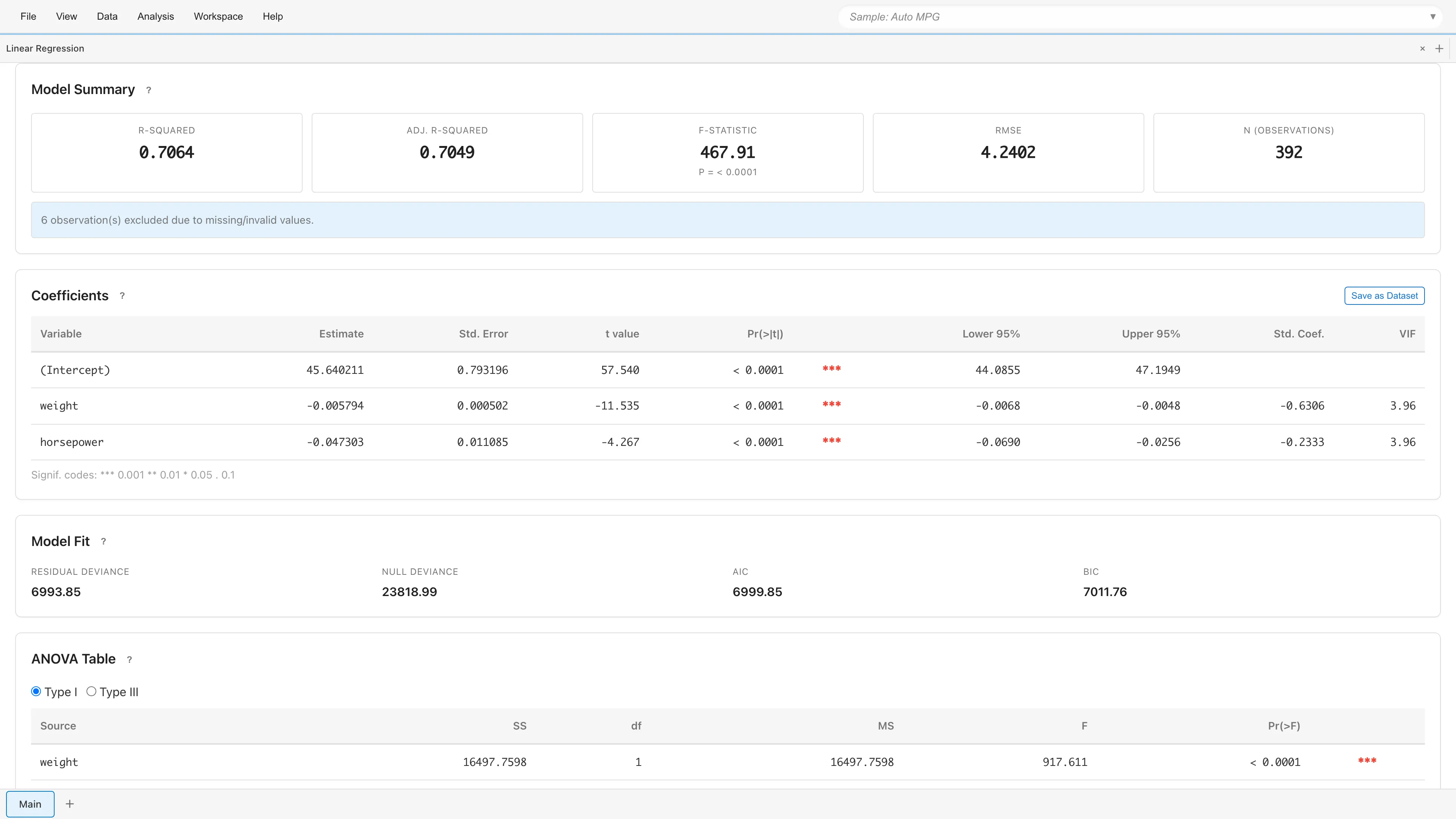
モデル全体の適合度を示します。
| 指標 | 説明 |
|---|---|
| R-squared | モデルが説明する分散の割合(0〜1) |
| Adj. R-squared | 説明変数の数で自由度調整した R-squared: 。 は切片を含む計画行列 の列数。変数追加で は単調増加するが、Adj. R-squared は不必要な変数の追加で下がりうる |
| RMSE | 残差の標準偏差(予測誤差の目安) |
| N (observations) | 分析に使用した観測数 |
欠損値や無効な値を含む行が除外された場合、除外件数を表示します。
Coefficients(係数テーブル)
| 列 | 説明 |
|---|---|
| Variable | 変数名(切片は "(Intercept)") |
| Estimate | 回帰係数の推定値 |
| Std. Error | 標準誤差 |
| Lower N% / Upper N% | 信頼区間 。N は設定した信頼水準(50 から 99.99 の任意の値) |
| Std. Coef. | 標準化係数 。各変数の標準偏差を単位としたときの回帰係数。切片の行には「-」と表示される |
| VIF | 分散拡大係数(多重共線性を参照) |
誤差が正規分布に従えば、 分布に基づく信頼区間は標本サイズによらず正確な被覆確率を持ちます。
係数テーブルは Save as Dataset ボタンでデータセットとして保存し、CSV にエクスポートできます。保存には先にモデルを Save Model で保存しておく必要があります。係数データセットを具体的なモデルに紐付けることで、モデル削除時に係数データセットとレポート要素も一緒に削除され、再学習時にデータセットの内容が新しい fit の結果で更新されます。
保存されるデータセットの列は Variable, Estimate, Std. Error, Lower N%, Upper N%, Std. Coef., VIF です。
係数の解釈
係数は応答変数のスケールで直接解釈できます。
- 連続変数: 他の変数を一定に保ったとき、 が1単位増加すると の期待値は だけ変化する
- ダミー変数: 参照カテゴリに対する の期待値の差を表す
- 切片: すべての説明変数が0のときの の期待値
- 標準化係数(Std. Coef.): 各変数の標準偏差1つ分の変化に対する の変化を の標準偏差単位で表した値。スケールの異なる変数間で回帰係数の大きさを揃えられるが、「標準偏差1つ分」の意味は変数ごとに異なるため、係数の大小がそのまま変数の重要度を表すとは限らない。ダミー変数の標準偏差はカテゴリの比率に依存するため、連続変数との単純な比較は推奨されない
Model Fit
| 指標 | 説明 |
|---|---|
| Residual Deviance | 残差平方和 |
| Null Deviance | 全平方和 |
| AIC | 赤池情報量規準 。 は推定パラメータの総数(回帰係数 個と誤差分散 の計 個)。値が小さいほど当てはまりがよいことを示します |
| BIC | ベイズ情報量規準 。AIC よりモデルの複雑さに強いペナルティを課します。AIC は予測精度の最適化に適し、BIC は真のモデルの選択において一致性を持ちます(標本数の増加に伴い真のモデルを選ぶ確率が 1 に収束します)。両者が異なるモデルを示す場合は分析の目的に応じて判断してください |
ANOVA Table
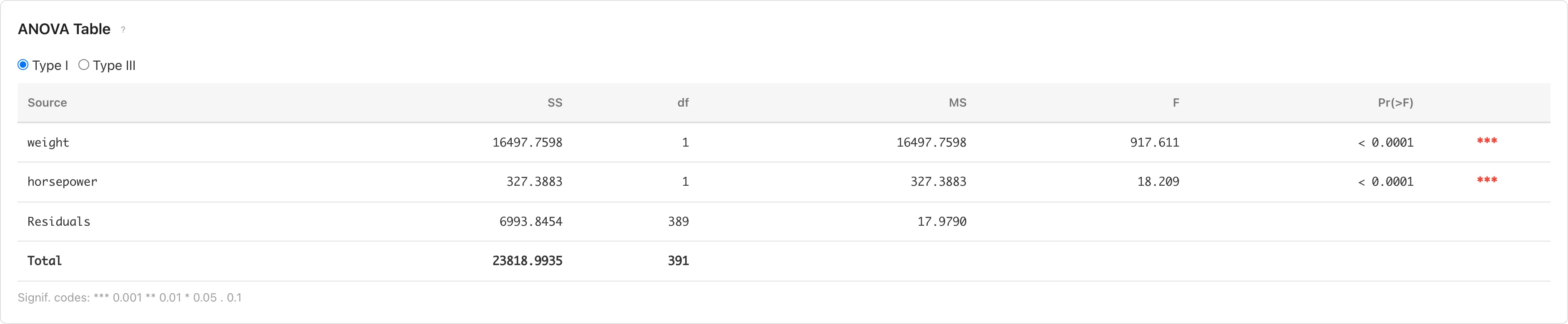
各説明変数の寄与を分散分析で評価します。Type I と Type III をラジオボタンで切り替えられます。
- Type I(Sequential): 変数を投入した順番で平方和を計算。変数の投入順序によって結果が変わります。
- Type III(Partial): 各変数を最後に投入した場合の平方和を計算。変数の投入順序に依存しません。
| 列 | 説明 |
|---|---|
| Source | 変動の要因 |
| Sum Sq | 平方和 |
| DF | 自由度 |
| Mean Sq | 平均平方(Sum Sq / DF) |
| partial η² | 偏イータ二乗(SS_effect / (SS_effect + SS_residual))。Type III のみ表示される |
| partial ω² | 偏オメガ二乗。自由度で調整された効果量推定値。推定値が負の場合は 0 と表示される。Type III のみ表示される |
Prediction & Confidence Intervals
各観測値の予測値と区間推定を表示します。
| 列 | 説明 |
|---|---|
| Fitted | 予測値 |
| CI Lower N% / CI Upper N% | 平均応答の信頼区間 |
| PI Lower N% / PI Upper N% | 個々の観測値の予測区間 |
信頼区間(CI)は母平均の推定精度を、予測区間(PI)は新しい個々の観測値の変動範囲を表します。PI は CI より常に広くなります。N は設定した信頼水準(50 から 99.99 の任意の値)です。
100行を超える場合は最初の50行のみ表示します。Show all N rows で全行を展開できます。
予測区間テーブルも Save as Dataset でデータセットとして保存できます。係数テーブルと同じく、保存には先にモデルを Save Model で保存しておく必要があります。
モデルの保存と診断

分析結果をプロジェクトに保存し、診断プロットを確認します。
モデルの保存
Model Name フィールドにモデル名を入力し、Save Model ボタンをクリックします。モデル名はデフォルトで「Linear Regression: Y ~ X1 + X2」の形式で自動生成されます。
同じ設定(データセット、目的変数、説明変数、切片の有無)の既存モデルがある場合、上書き確認ダイアログが出ます。
診断用に生成されるデータ
モデル保存後に View Diagnostics で Residual Diagnostics タブを最初に開くと、元のデータセットに診断統計量の列を追加した派生データセットが生成されます。
| 列名 | 数式での記号 | 内容 |
|---|---|---|
fitted_values | 予測値 | |
deviance_residuals | 残差 | |
standardized_residuals | 標準化残差 | |
sqrt_abs_std_residuals | 標準化残差の絶対値の平方根(Scale-Location プロットで使用) | |
leverage | てこ比(Hat 行列の対角要素) | |
cooks_distance | Cook's Distance |
診断と詳細
モデル保存後、2つのボタンが使えるようになります。
- View Model Details - モデルの詳細情報を表示する Model Detail タブを開きます。Confidence Level 入力を変更すると、保存済みの係数と標準誤差から Wald 信頼区間と列ヘッダをその場で再計算します(モデルに保存された値は変わりません)。Add to Report ボタンから係数テーブルをレポートに追加できます。
- View Diagnostics - 残差診断プロットを表示する Residual Diagnostics タブを開きます
残差診断プロット
View Diagnostics をクリックすると4つの診断プロットが開きます。OLS 回帰の仮定が成り立っているかを確認できます。
OLS 回帰の仮定:
- 線形性 - 目的変数と説明変数の間に線形関係がある
- 正規性 - 残差が正規分布に従う
- 等分散性 - 残差の分散が予測値に依存せず一定である
- 独立性 - 残差が互いに独立である(診断プロットでは直接確認できない)。データに階層・クラスター構造がある場合は GLMM のランダム効果を検討してください。時系列的な系列相関がある場合は ARIMA(Analysis メニューから利用可能)を検討してください
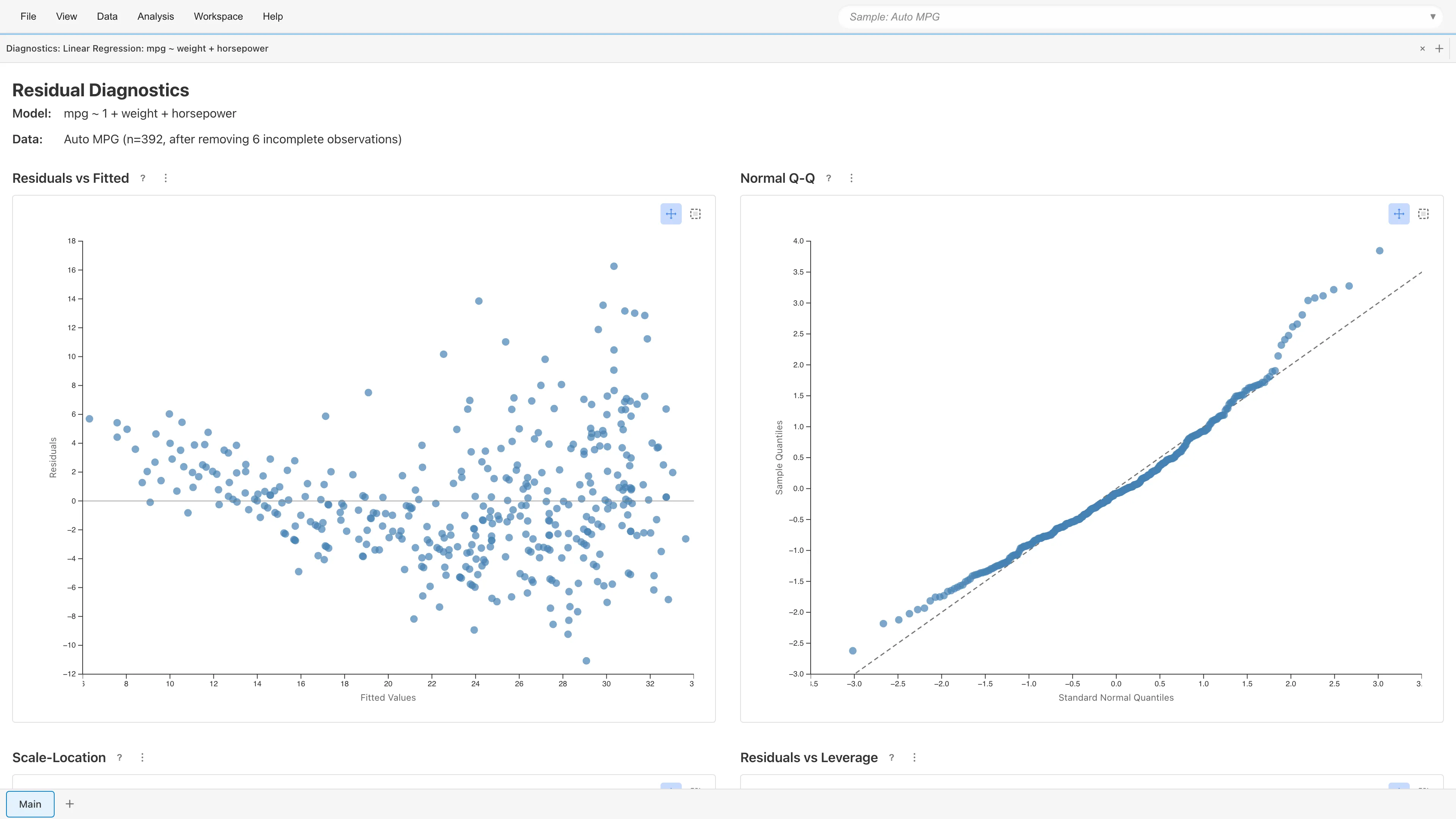
Normal Q-Q、Scale-Location、Residuals vs Leverage の3プロットでは標準化残差(internally studentized residual) を使用します。Residuals vs Fitted は生の残差 を使用します。数式の詳細は 回帰分析の基礎 を参照してください。
Residuals vs Fitted(残差 vs 予測値)
横軸に予測値 、縦軸に残差 をプロットします。モデルが適切なら、残差はゼロの周囲にランダムに散らばります。
- 曲線的パターン: 説明変数の非線形効果が欠落している可能性
- 漏斗状パターン: 不等分散の可能性(Scale-Location プロットで詳しく確認)
Normal Q-Q Plot(正規 Q-Q プロット)
標準化残差 の分位点を標準正規分布の理論分位点に対してプロットします。残差が正規分布に従っていれば点は対角線上に並びます。両端で外れる場合は裾が重い分布(外れ値が多い)、S 字型に外れる場合は歪みがあることを示します。
Scale-Location(尺度-位置プロット)
横軸に予測値、縦軸に をプロットします。分散が一定なら点は水平方向に均等に散らばります。予測値が大きくなるにつれて点が広がる(漏斗状)パターンや右上がりの傾向は、不等分散を示します。不等分散がある場合、係数の推定値は不偏ですが標準誤差が不正確になり、信頼区間の被覆確率が名目水準から乖離します。MIDAS は現在ロバスト標準誤差を実装していません。不等分散が疑われる場合は、応答変数の対数変換や、分散構造をモデル化できる GLM の使用を検討してください。
Residuals vs Leverage(残差 vs てこ比)
横軸にてこ比 、縦軸に標準化残差 をプロットします。Cook (1977) の Cook's Distance 等高線(: オレンジ破線、: 赤破線)を重ねて表示します。Cook は を 分布の50パーセンタイルと比較することを提案しており、 が小さく が十分に大きい場合はおよそ1前後の値になりますが、 や によって変わります。ただしこれは形式的な棄却域ではなく、観測値間の影響度を相対的に比較するための目安です。
- てこ比(Leverage): 説明変数空間で観測値が他からどれだけ離れているかを示す。 が高レバレッジの閾値
- Cook's Distance: てこ比と残差の大きさを1つの影響度指標にまとめたもの
等高線の外側に位置する観測値は、その1点を除外するだけでモデルの推定結果が大きく変わる可能性があります。
てこ比が 1 に極めて近い観測値()では、標準化残差と Cook's Distance の分母が 0 に近づき数値計算が不安定になるため、MIDAS は両者を 0 と表示します。これは影響が小さいことを意味せず、てこ比自体が極端であることを示します。プロットの横軸で確認してください。
ポイントの選択
プロット上でデータポイントをクリックまたは矩形選択すると、該当する観測値の詳細(予測値、残差、てこ比、Cook's Distance 等)をプロット下部のテーブルに表示します。選択状態は4つのプロット間で同期します。
注意事項
カテゴリ変数の使用
文字列型などのカテゴリ変数を説明変数として使用するには、Dummy Coding タブで数値のダミー変数に変換してから分析します。ブール型の列は変換不要で、0/1 として扱われます。
交互作用項
交互作用項を分析に含めるには、データセット上であらかじめ変数の積を計算した列を作成してください。MIDAS は交互作用項の自動生成をサポートしていません。
欠損値・無効値の自動除外
欠損値(null)、非数値、無限大を含む行は自動的に除外します。除外した行数は Model Summary に表示します。この除外はリストワイズ除去に該当します。妥当な推定を与える条件については欠損データのメカニズムを参照してください。
多重共線性
説明変数間の相関が高いと係数の推定が不安定になります。係数テーブルの VIF(Variance Inflation Factor)が大きい変数がある場合、冗長な変数の除外や統合を検討してください。VIF の詳細は回帰分析の基礎を参照してください。
サンプルサイズと正規性
信頼区間の被覆確率が有限標本で名目水準に一致するかどうかは、誤差の正規性に依存します。大標本では中心極限定理が効きますが、小標本では Q-Q プロットで残差の正規性を確認してください。必要なサンプルサイズは誤差の真の分布次第で、一律の基準はありません。
参考文献
- Cook, R. D. (1977). Detection of influential observation in linear regression. Technometrics, 19(1), 15-18. https://www.jstor.org/stable/1268249
Next steps
- 残差診断プロット - モデルの仮定を確認する
- GLM(一般化線形モデル) - カウントデータや二値データのモデリング
See also
このページの Markdown 版もあります。