DoE Analysis(実験計画法)
DoE Analysis タブは、2水準の実験計画法データを分析します。直交表の生成、主効果プロット・交互作用プロットによる因子効果の推定、ANOVA テーブルによる変動の分解に対応しています。
タブを開く
メニューバーから Analysis > DoE Analysis... を選択します。
直交表の生成
実験条件の組み合わせを決める直交表を生成できます。DoE Analysis タブ右上の New Design... をクリックするとウィザードが開きます。
因子の定義
各因子の名前と2つの水準ラベルを入力します。最低2因子が必要です。
直交表タイプ
因子数に応じた直交表タイプを選択します。
| タイプ | 実験回数 | 最大因子数 |
|---|---|---|
| L4 | 4 | 3 |
| L8 | 8 | 7 |
| L16 | 16 | 15 |
直交表は Hadamard 行列から生成されます。任意の2因子の水準の組み合わせが均等に出現し、デザイン行列上の因子間の相関が0になります。
最大因子数は直交表に配置できる因子数の上限であり、反復なしで分析可能な因子数とは限りません。反復の追加については次のセクションを参照してください。
反復数
Replications に反復数を入力します。デフォルトは1です。2以上を指定すると、直交表の各行を指定回数分複製してデータセットに追加します。例えば L4 で Replications = 3 と設定すると、基本4行 x 3反復 = 12行のデータセットが生成されます。
反復を追加すると観測数が増え、誤差分散の推定精度が向上します。観測数がパラメータ数以下の場合は誤差分散を推定できず、分析を実行するとエラーになります。L4 で3因子の主効果モデルでは、切片を含む4パラメータに対して観測が4行であり、これに該当します。反復を追加するか、因子数に対して余裕のある直交表タイプを選択してください。
実行順序のランダム化
Randomize run order はデフォルトでオンになっており、生成される実験条件の順序をランダムに並べ替えます。実験順序による系統的な偏りを防ぐため、実際の実験ではランダム化したまま生成することを推奨します。オフにすると直交表の行順のまま生成します。
データセットの生成
プレビューで直交表を確認した後、Generate をクリックするとデータセットとしてプロジェクトに追加されます。応答変数の列は空の状態で作成されるので、データテーブル右上の テーブルメニュー から Edit Data を選択して実験結果を入力してください。
分析の実行
設定パネルで以下を上から順に設定します。Response Variable と Model は同じ行に左右で並びます。
- Dataset から分析対象のデータセットを選択
- Response Variable (Numeric) に数値変数を選択
- Model でモデルの種類を選択
- Factors (categorical) で2水準のカテゴリ変数を選択。最低2因子を選択してください
- Run Analysis をクリック
データの要件
因子はカテゴリ変数を選択します。測定尺度が nominal または ordinal の列が因子の候補として表示されます。現在のバージョンでは2水準の因子のみに対応しています。3水準以上の因子を選択した場合、分析実行時にエラーメッセージが表示されます。
応答変数は数値型の列を選択します。
モデルの選択
Main effects only: 各因子の主効果のみをモデルに含めます。因子間の交互作用がないと仮定できる場合に使います。
Main effects + all 2-factor interactions: 全ての因子ペアの2因子交互作用を主効果に加えてモデルに含めます。交互作用がありうる場合に使います。因子数が多いと交互作用の項が増え、残差の自由度が減ります。例えば L8 で7因子を全て選択し、全2因子交互作用を含めると、主効果7項 + 交互作用21項 + 切片 = 29パラメータになりますが、データは8行しかないため分析できません。因子数が多い場合は、主効果のみから始めて必要に応じて交互作用を追加してください。
Main effects + selected interactions: 関心のある因子ペアの交互作用のみを選択してモデルに含めます。
結果の読み方
分析結果は4つのサブタブ(ANOVA Table / Main Effects / Interaction / Diagnostics)で確認できます。
ANOVA Table
各因子と交互作用の平方和と効果量の推定値です。Type III 平方和を使用しています。
| 列 | 説明 |
|---|---|
| Source | 因子名または交互作用名 |
| DF | 自由度。2水準因子では各項が1 |
| Adj SS | 調整平方和。他の全因子で調整された各項の寄与 |
| Adj MS | 調整平均平方。Adj SS を DF で割った値 |
| partial η² | 偏イータ二乗(SS_effect / (SS_effect + SS_residual)) |
| partial ω² | 偏オメガ二乗。自由度で調整された効果量推定値。推定値が負の場合は 0 と表示される |
テーブルの下に R-squared、Adjusted R-squared、Model SE が表示されます。
応答変数の全値が同一だと、全変動が0になります。このとき R-squared と partial η²/ω² の推定値は定義できず、R-squared は "-"、η²/ω² 列は空欄になり、警告が理由を示します。
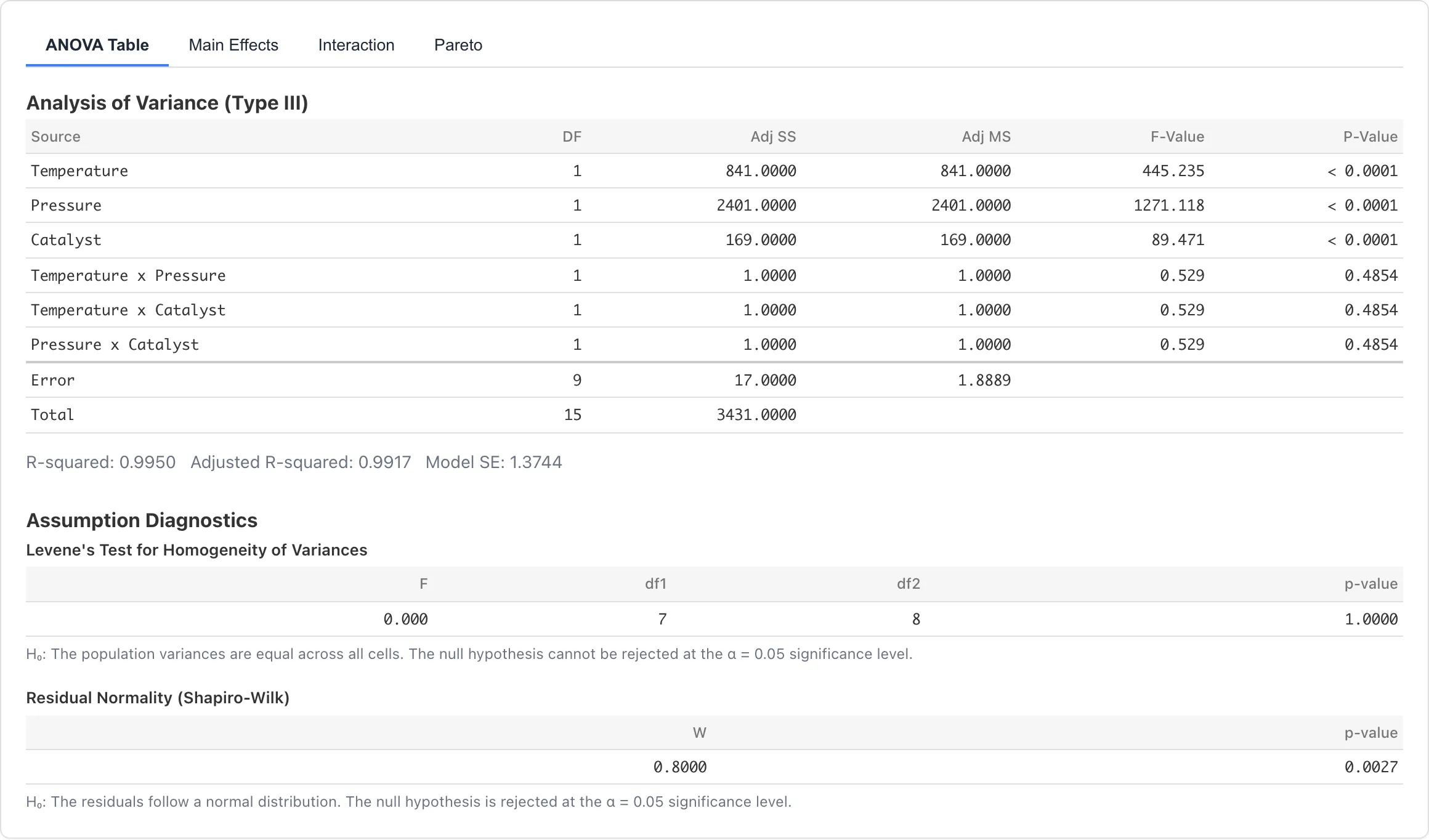
テーブルの行をクリックすると、主効果プロットや交互作用プロットで対応する因子がハイライトされます。
Main Effects Plot
各因子の水準ごとの応答変数の観測平均を折れ線グラフで表示します。因子ごとに1つのサブプロットを描画し、Y 軸のスケールは全サブプロットで統一されています。傾きが急な因子ほど応答に対する効果が大きいことを示します。
水平の破線は全体平均です。全体平均は OLS モデルの切片であり、均衡デザインでは全観測の算術平均と一致します。
Show 95% confidence intervals をオンにすると、各水準平均に95%信頼区間をエラーバーとして表示します。信頼区間の信頼水準は 95% 固定です。標準誤差はモデルの残差平均二乗 MSE から として計算されます。 はその水準の観測数です。この標準誤差は全水準で誤差分散が等しいという仮定のもと、モデル全体の残差分散を使用しています。信頼区間の幅は残差自由度に基づく t 分布の臨界値を使います。エラーバーは個々の水準平均の推定精度を示すもので、2水準間の差の検定とは目的が異なります。
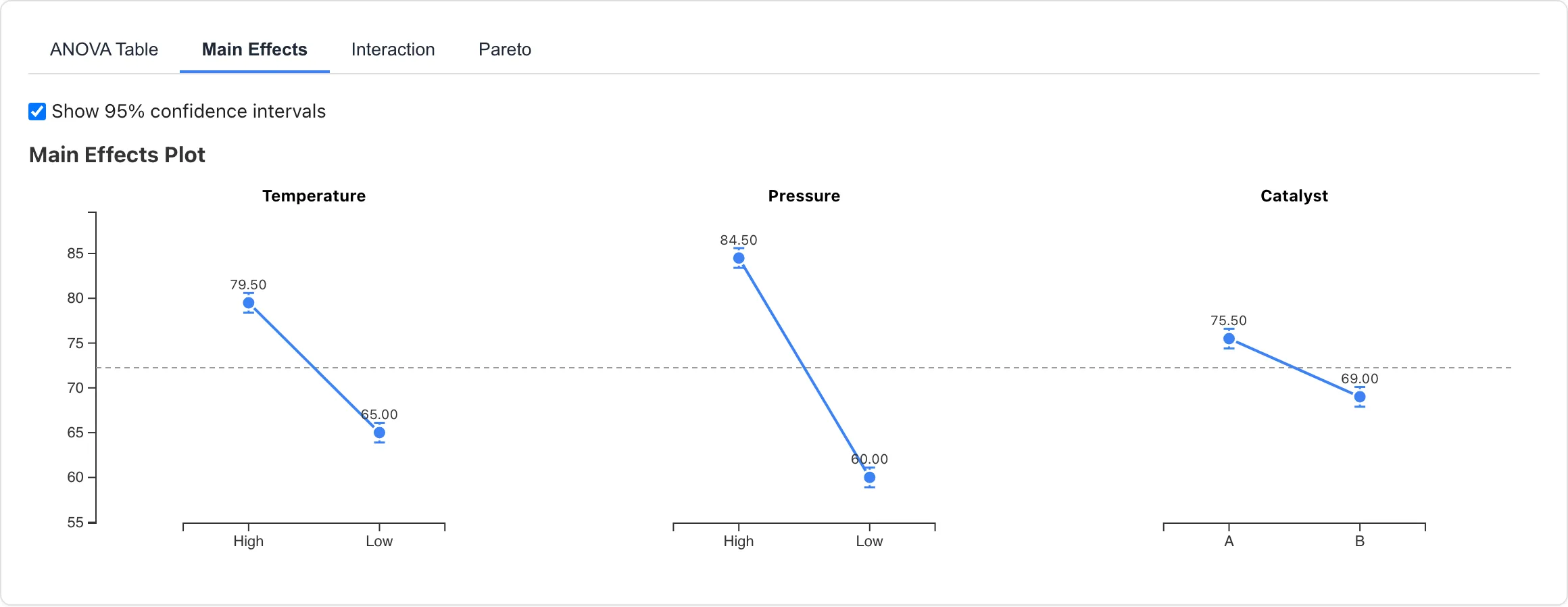
ポイントをクリックすると、対応する水準のデータ行がデータテーブル上で選択されます。
Add to Report ボタンで主効果プロットをレポートに追加できます。
Interaction Plot
モデルに含めた交互作用ペアごとに、セル平均を折れ線のサブプロットで表示します。X 軸に一方の因子、色分けされた線でもう一方の因子を表現します。Main effects + all 2-factor interactions では因子が 個あれば 個のサブプロットが描画され、Main effects + selected interactions では選択したペアのみ描画されます。Main effects only ではこのタブにサブプロットは表示されません。
線が平行に近い場合、交互作用は小さいと考えられます。線が交差する場合、一方の因子の効果がもう一方の因子の水準によって異なることを示します。交互作用の大きさは ANOVA Table の効果量(partial η²、partial ω²)で評価できます。
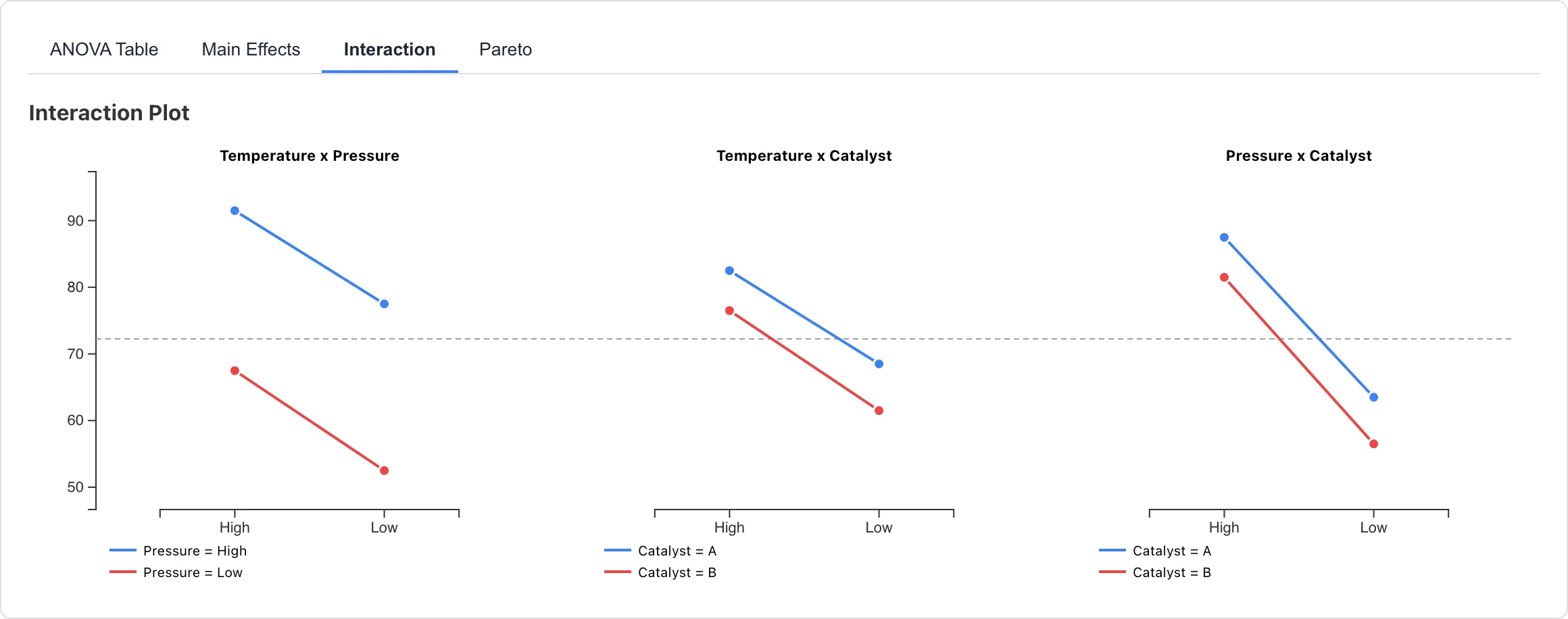
ポイントをクリックすると、対応するセルのデータ行がデータテーブル上で選択されます。
Add to Report ボタンで交互作用プロットをレポートに追加できます。
Diagnostics
残差の Q-Q プロットを表示します。残差は (OLS モデルの当てはめ値からの偏差)として計算されます。
参照線からの系統的な乖離は残差の非正規性を示します。両端で曲がる場合は裾の重さ、S字カーブは歪み、参照線から大きく離れた孤立点は外れ値を示唆します。
このタブは正規性の仮定のみを確認します。等分散性の評価には、因子水準の組み合わせごとに応答変数のばらつきを別途比較してください。
Add to Report ボタンで残差 Q-Q プロットをレポートに追加できます。
統計モデル
効果コーディング
2水準因子をアルファベット順にソートした最初の水準に +1、2番目の水準に -1 を割り当てます。2つの水準が ±1 に配置されるため、回帰係数は水準間の応答平均の差の半分に対応します。主効果プロットは各水準の応答平均とその信頼区間を表示します。X 軸には水準ラベルがアルファベット順に表示されるので、左側の水準が +1、右側が -1 に対応します。SS や効果量はコーディングの方向に依存しませんが、回帰係数の符号は +1 側の水準の応答が高い場合に正になります。
交互作用列は、対応する2因子の主効果列の要素ごとの積として構成されます。
係数の推定
切片と全ての項を含むデザイン行列を構築し、Householder QR 分解で最小二乗推定を行います。
Type III 平方和
各因子の平方和は、フルモデルの係数とその標準誤差の比 を用いて として計算されます。2水準因子は各1自由度であるため、この値は Type III 平方和に一致します。他の全因子で調整された各因子の固有の寄与を評価するため、因子の投入順序に依存しません。Type III 平方和の詳細は ANOVA を参照してください。DoE Analysis は効果コーディングを使用しており、ANOVA ページの treatment coding に基づく解釈とは係数の意味が異なります。2水準均衡直交表では、平方和と効果量の分解はコーディングの選択によらず一致します。
前提条件
この分析は以下を前提としています。
- 独立性: 各実験が互いに独立に実施されていること
- 正規性: 応答変数の誤差が正規分布に従うこと
- 等分散性: 全ての因子水準の組み合わせで誤差の分散が等しいこと
独立性は実験の実施方法で決まります。正規性は Diagnostics タブの残差 Q-Q プロットで評価できます。等分散性は因子水準の組み合わせごとに応答変数のばらつきを比較して評価してください。
欠損値の処理
因子または応答変数に欠損値を含む行は分析から除外されます。除外された行数は結果パネルに表示されます。直交表から生成したデータで欠損値が発生すると、直交性が崩れて因子間に相関が生じます。因子間に相関があると、効果推定値の標準誤差が大きくなります。また、直交表のデータでは Type I と Type III の平方和が一致しますが、直交性が崩れると一致しなくなり、各因子の平方和の合計がモデル全体の平方和に満たなくなります。行の除外でセルごとの観測数が等しくなくなると、結果パネルに警告が表示されます。この場合、主効果プロットと交互作用プロットに表示されるセル平均とその標準誤差は調整されていない観測値であり、最小二乗平均ではありません。全体平均の破線は OLS モデルの切片であり、全観測の算術平均とは一致しません。欠損を最小限に抑えるよう実験を計画してください。この除外はリストワイズ除去に該当します。妥当な推定を与える条件については 欠損データのメカニズム を参照してください。
関連ページ
- ANOVA -- 水準数の制限がない一元配置・二元配置の分散分析
- Linear Regression -- 連続変数を含む回帰分析
このページの Markdown 版もあります。