高度なグラフ作成
Graph Builder タブを開き、Graph Type から Custom Graph を選択します。Graph Builder は Analysis → Graph Builder... から開けます。
Graph Builder は Bar Chart、Histogram、Scatter Plot など、複数の Graph Type を提供しています。 描画したいものが決まり切った形式のグラフで、多少の調整さえできればよい場合には、これらは手軽で使いやすいものです。
散布図に回帰直線を重ねる、ファセットでサブグループを比較する、複数のグラフタイプを1つに重ね合わせるなど、より柔軟にグラフを構成したい場合に Custom Graph を使います。
Custom Graph は、Grammar of Graphics の考え方をベースにしています。グラフを構成要素に分解し、これらをレイヤーとして自由に組み合わせます。
- 複数のグラフタイプを1つのグラフに重ね合わせる(例:散布図+回帰直線)
- データを統計的に変換してから可視化する(例:ヒストグラム、カーネル密度推定)
- ファセット(小区画)で多次元データを探索する
- 座標軸のスケールや方向を柔軟に制御する
他の Graph Type が「完成品の家具」だとすれば、Custom Graph は「組み立て式の素材セット」です。基本的な構成要素を理解すれば、多様な可視化パターンを作成できます。
Grammar of Graphics の構成要素
Custom Graph は、以下の要素を組み合わせてグラフを構築します。
- Data: 可視化対象のデータセット
- Aesthetics: 変数(データセットの列)と視覚属性(位置、色、サイズなど)との対応関係
- Geometry: データの視覚的な表現形式(Point、Line、Bar など)
- Statistics: データの統計変換(ビニング、平滑化など)
- Scales: データ値から視覚値への変換方法
- Coordinates: 座標系(直交座標、軸の入れ替えなど)
- Position: 要素の位置調整(積み上げ、並列など)
- Facets: 複数の小グラフをまとめたグラフを作る場合の、その構成
これらの要素は Layer として束ねられ、複数のレイヤーを重ねることで多様な可視化を構成できます。
Data - データの選択
まずは可視化するデータセットを選択します。ここでは Auto MPG データセット(1970-1982年の自動車398台の燃費データ)を使います。
Aesthetics - 視覚属性のマッピング
データの列を視覚属性にマッピングします。最も基本的なのは、2つの連続変数を x 軸と y 軸にマッピングすることです。
Data: Auto MPG
Aesthetics: x = weight, y = mpg
Geometry: Point
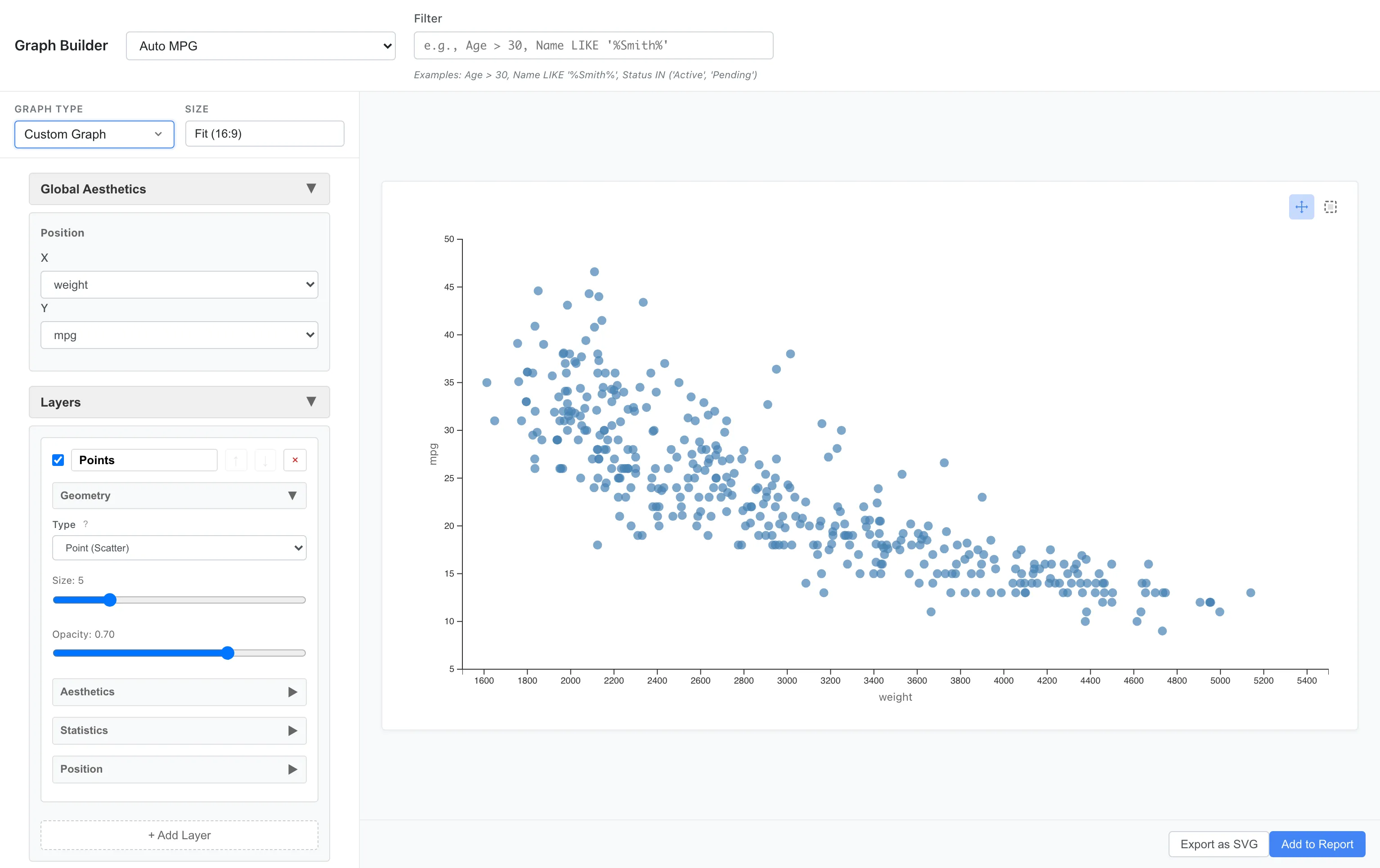
重い車ほど燃費が悪い、という負の関連が見えます。
色と対応させる
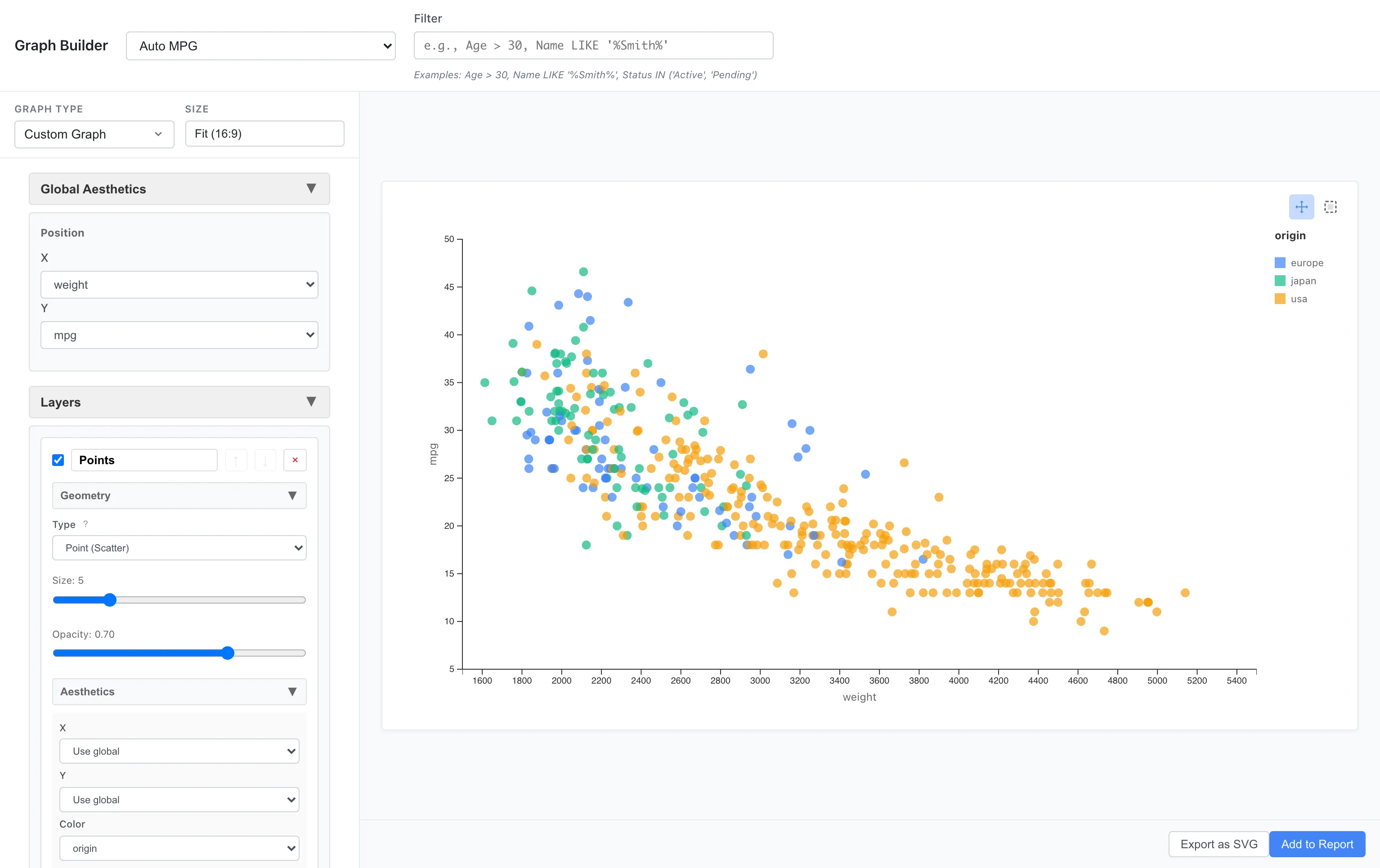
3つ目の変数を色にマッピングすることで、さらに情報を追加できます。
例えばorigin(usa、europe、japan)で色分けしてみます。
Aesthetics: x = weight, y = mpg, color = origin
サイズと対応させる
horsepowerを点のサイズに対応させます。
Aesthetics: x = weight, y = mpg, color = origin, size = horsepower
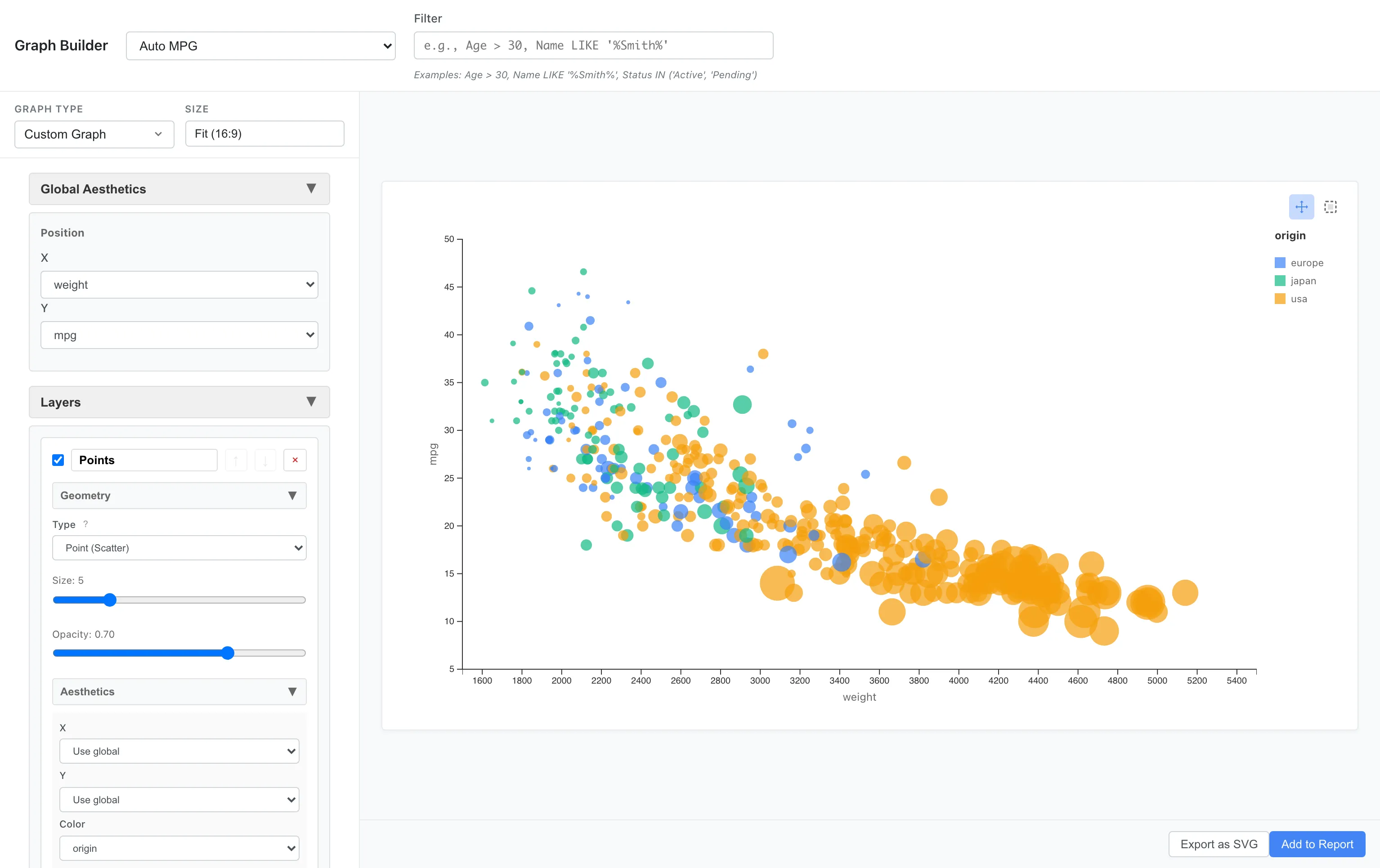
大きな点ほど馬力が高いことを示します。重くて馬力の高い車は燃費が悪い、という関係が視覚的に理解できます。
fill と color
Aesthetics には fill と color の2つの色指定があります。fill は Geometry の塗りに対応し、Bar の棒の内側や Area の面に適用されます。color は輪郭・線・点の色で、Point の点、Line の線、Bar の枠線に適用されます。Point と Line は fill に対応しておらず、色は color のみで制御します。
Layers - レイヤーの重ね合わせ
レイヤーにより、複数のグラフを重ねられます。 例えば散布図の上に LOESS(局所重み付け回帰)による平滑化曲線を追加してみます。
Layer 1: Point (x = weight, y = mpg)
Layer 2: Line + Smooth統計 (method = loess)
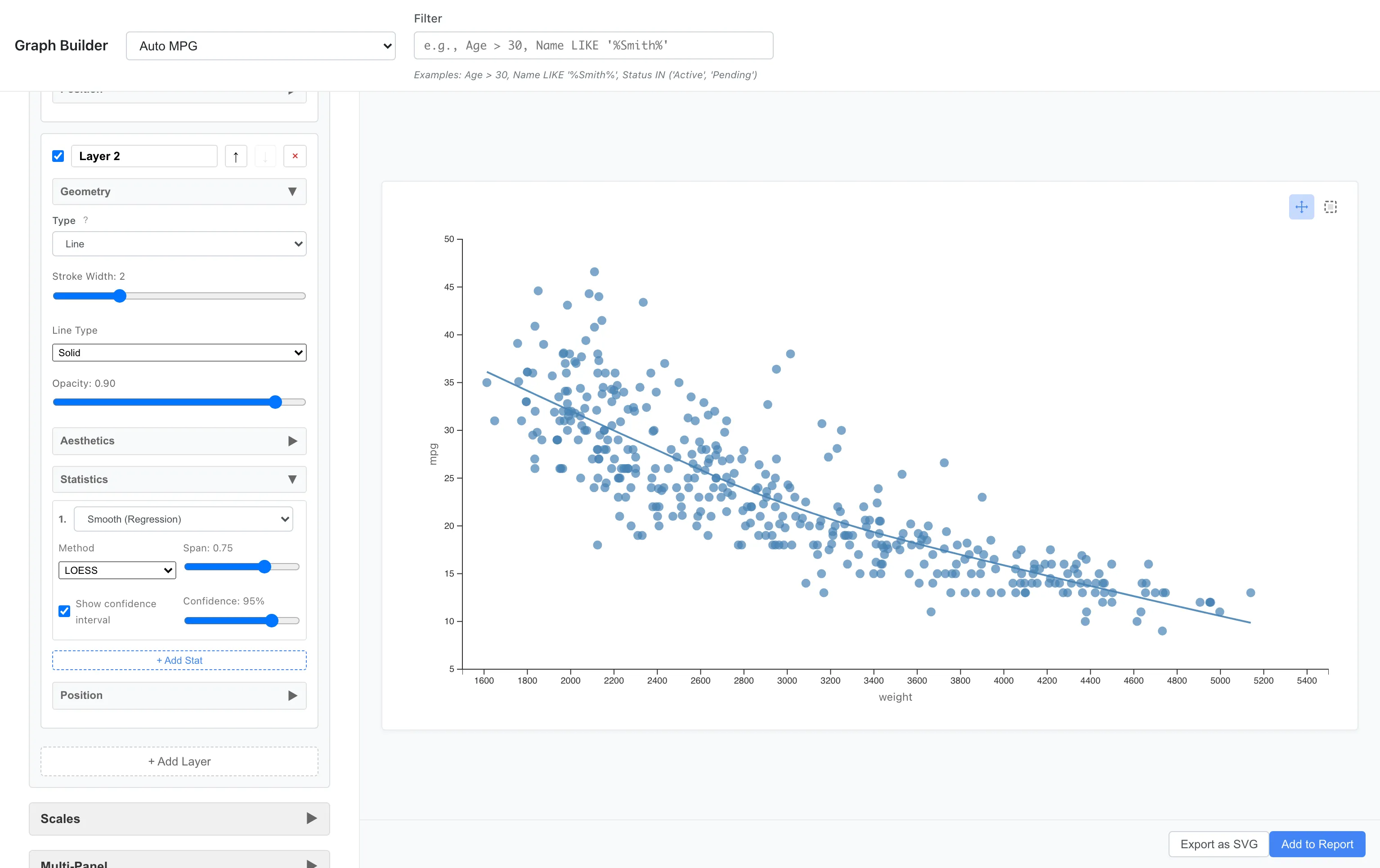
青い線が LOESS 平滑化曲線です。データの局所的なパターンを滑らかな曲線で要約します。Method を Linear (LM) に変更すると、線形回帰直線を描画します。
LOESS 選択時は Span で、各点の平滑化に使用する近傍データの割合を 0.1-1.0 の範囲で調整できます。値が大きいほど広い範囲のデータを参照し、曲線は滑らかになります。値を小さくするとデータへの追従が強まり、局所的な変動を拾います。デフォルトは 0.75 です。
LOESS は局所線形回帰に Tricube 重みを使って各点の推定値を計算します。データ範囲の端では近傍が片側に偏りますが、重み関数の計算式は内側と同じで端補正はしません。Linear (LM) は x のみを共変量とする OLS 単回帰です。color・fill・stroke・shape・linetype で aesthetic グルーピングしている場合は、グループごとに独立した回帰を実行します。重み付き回帰や頑健標準誤差には対応していません。
Compute interval band をオンにすると、区間の下限・上限を ymin・ymax として出力します。Interval type で区間の種類を選べます。デフォルトは予測区間 (Prediction Interval, PI) です。
- Prediction (individual observation): 同じ x で新たに観測される 1 件の値が、指定した水準の確率でおさまる範囲。LM は 。平方根内の
1は新規観測の誤差分散 の相対係数です - Confidence (mean response): 標本抽出を繰り返したとき、構築した区間のうち指定水準で真の平均応答 を含む頻度論的区間。回帰直線自体の推定精度を表します。LM は
同じ水準では予測区間 (PI) が信頼区間 (CI) より必ず広くなります。Interval level は区間の水準で、デフォルトは 95% です。Linear (LM) は 分布に基づく古典的な区間を x の最小値から最大値まで等間隔に 101 点で計算します。LOESS は局所回帰の重み付き予測分散 から近似区間を元データの x 位置で計算します。
区間の妥当性は以下の前提に依存します。誤差の独立性と等分散性を仮定しており、時系列・クラスタ構造があるデータでは区間幅を過小評価します。PI は新規観測の誤差分布の正規性も要求します。CI は大標本では中心極限定理により非正規でも近似的に妥当ですが、PI はこの緩和を受けません。頑健標準誤差 (HC) や重み付き回帰には対応していません。LOESS は span を大きく取るほど平滑バイアスが増えますが、区間幅はこのバイアスを反映しないため、極端な span では名目水準と実被覆率が乖離します。LOESS の PI は を用いた簡易近似です。データ点が少ない、 (x が定数列)、残差分散が 0、LOESS で の場合は区間を出力しません。aesthetic でグルーピングしている場合、これらの条件はグループごとに評価されるため、一部のグループだけ区間帯が表示されないことがあります。
Line geom は ymin/ymax があるとき、信頼帯を自動的に描画します。帯の見た目をさらに制御したい場合は、別途 Ribbon レイヤーを使用できます。CI と PI の両方を重ねて表示するには、Interval type を変えた smooth レイヤーを 2 つ作ります。
Statistics - 統計変換
データをそのまま表示するだけでなく、統計的に変換して表示できます。
ヒストグラム(Binning)
燃費の分布を見るため、データをビン(区間)に分割してカウントします。
Aesthetics: x = mpg
Geometry: Bar
Statistics: Bin (bins = 20)
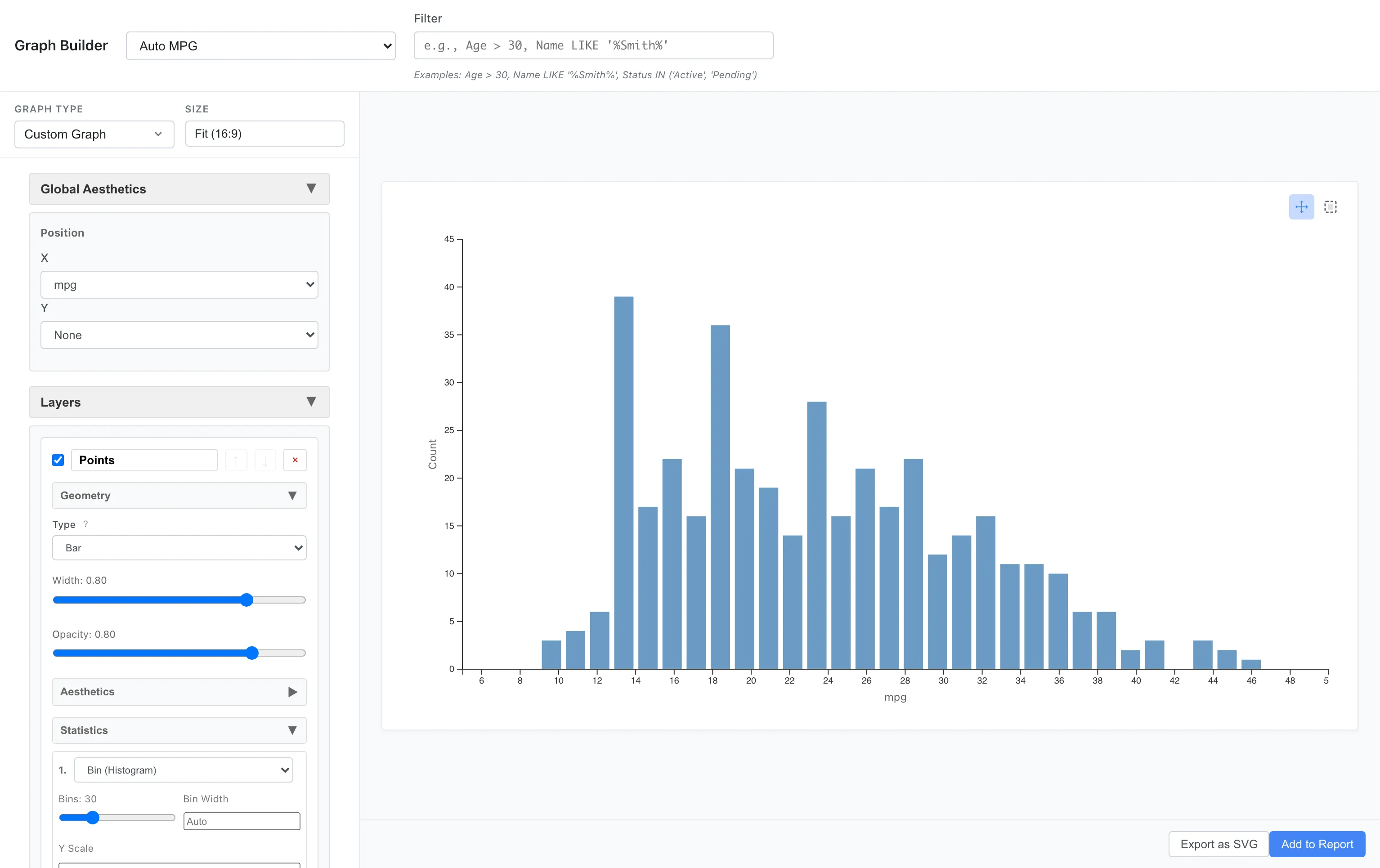
ほとんどの車が15-30 mpg の範囲に集中していることがわかります。分布は右裾が長く、燃費の良い車は少数派です。
bins のデフォルトは 30 です。ビン数は分布の形状に合わせて手動で調整します。
密度推定
ビンの代わりに滑らかな密度曲線で分布を表現できます。
Aesthetics: x = mpg
Geometry: Line
Statistics: Density
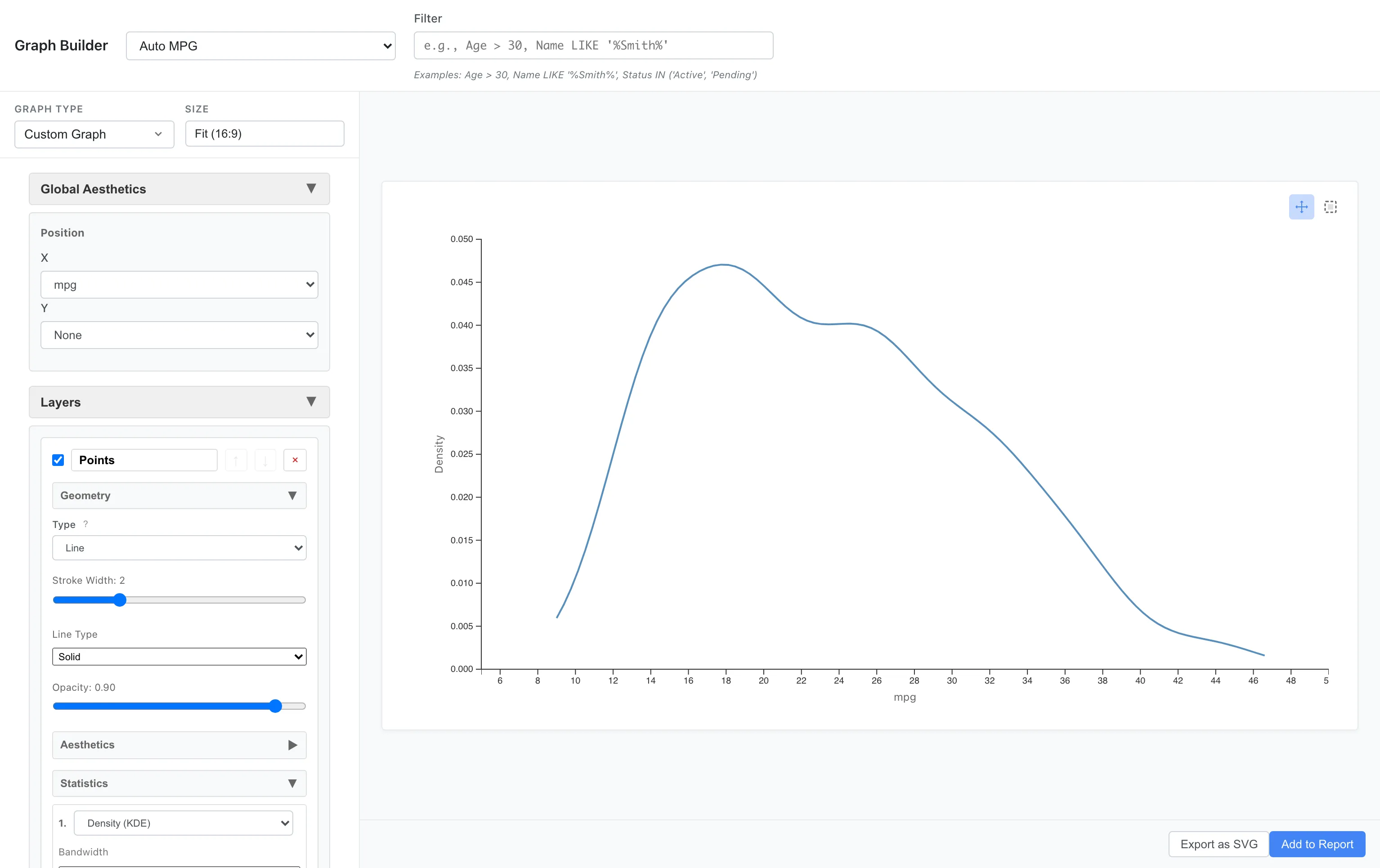
同じデータの分布を、別の方法で表現しています。ガウシアンカーネルで密度を推定し、バンド幅は Silverman の経験則で自動計算します。
複数グループの密度比較
カテゴリごとに密度曲線を重ねることで、分布の違いを比較できます。
originごとにヒストグラムの上に密度曲線を描いてみましょう。
Layer 1 (Bar):
Aesthetics: x = mpg, fill = origin
Geometry: Bar
Statistics: Bin (bins = 30)
Layer 2 (Line):
Aesthetics: x = mpg, color = origin
Geometry: Line
Statistics: Density (Y Scale = Count)
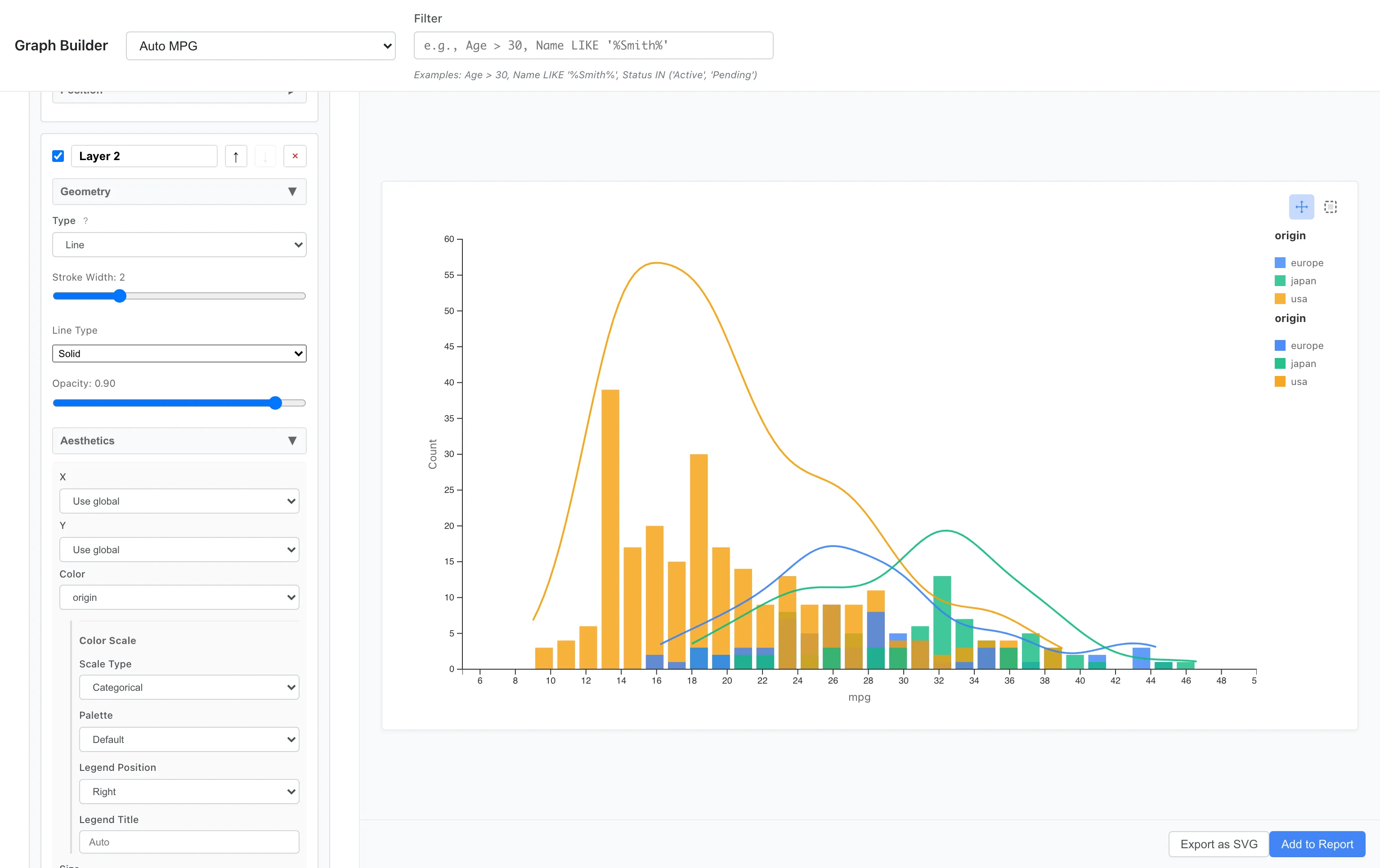
ポイント:
- Layer 1 (Bar):
fill = originで棒グラフの塗りつぶし色を分ける - Layer 2 (Line):
color = originで密度曲線の線色を分ける。Y Scale = Countは密度値にデータ件数とビン幅を掛けて度数スケールに変換します。ビン幅は Sturges の公式で内部計算するため、Layer 1 のbins = 30とは独立です。両者の縦軸が厳密に一致するとは限りません - Bar の塗りは
fill、Line の線色はcolorで制御します。同じ色スケールが適用されるため、色が一致します
日本車は高燃費側、米国車は低燃費側に分布のピークがあることが明確です。
Position - 位置調整
複数のカテゴリを棒グラフで比較する際、位置調整が重要になります。
積み上げ棒グラフ
Aesthetics: x = model_year, fill = cylinders
Geometry: Bar
Statistics: Count
Position: Stack
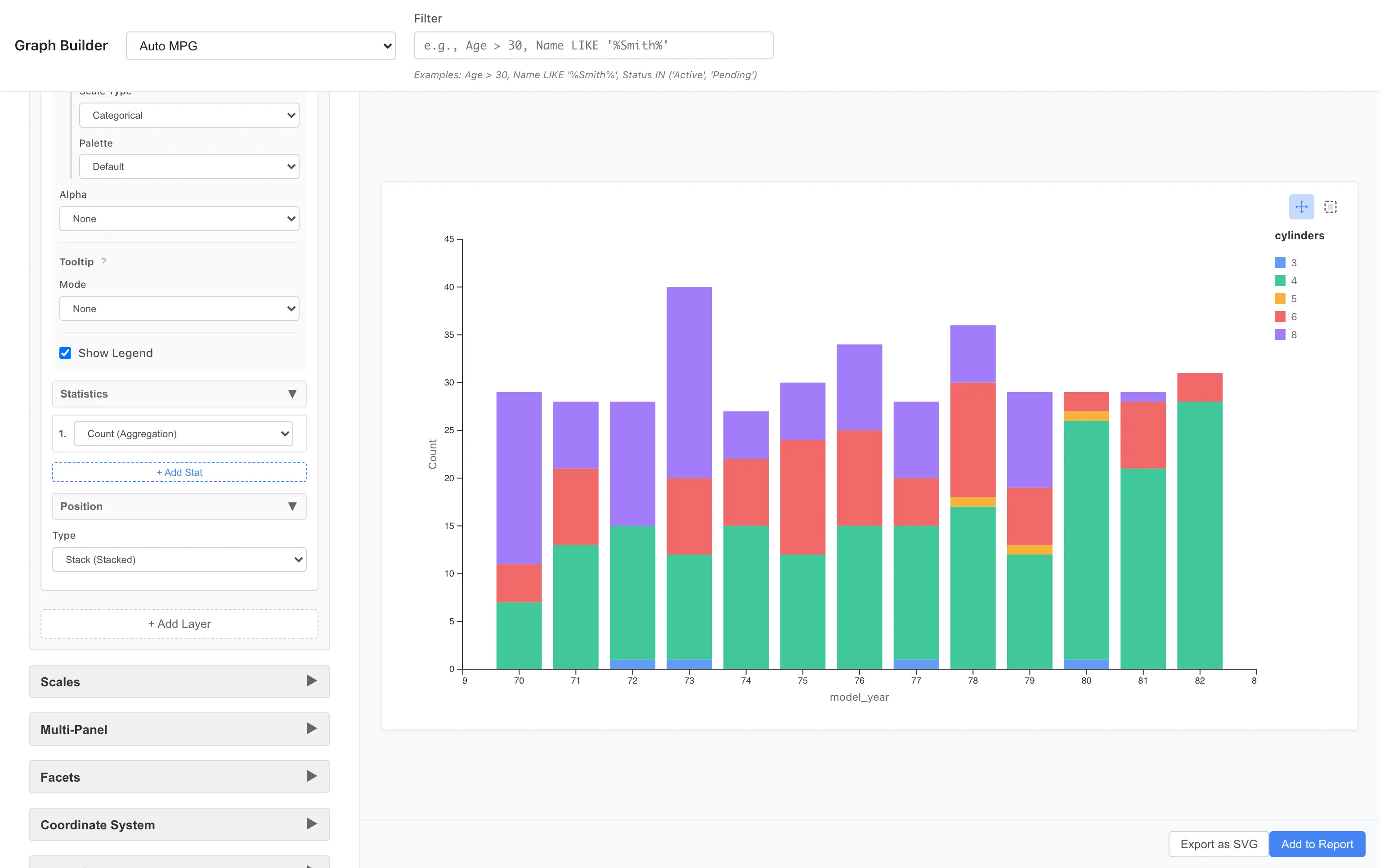
各年の車種の内訳が積み上げで表示されます。1970年代は8気筒車が多く、後半になるにつれ4気筒車が増えています。
並列棒グラフ
Position を dodge に変更すると、横に並べて表示されます。
Position: Dodge
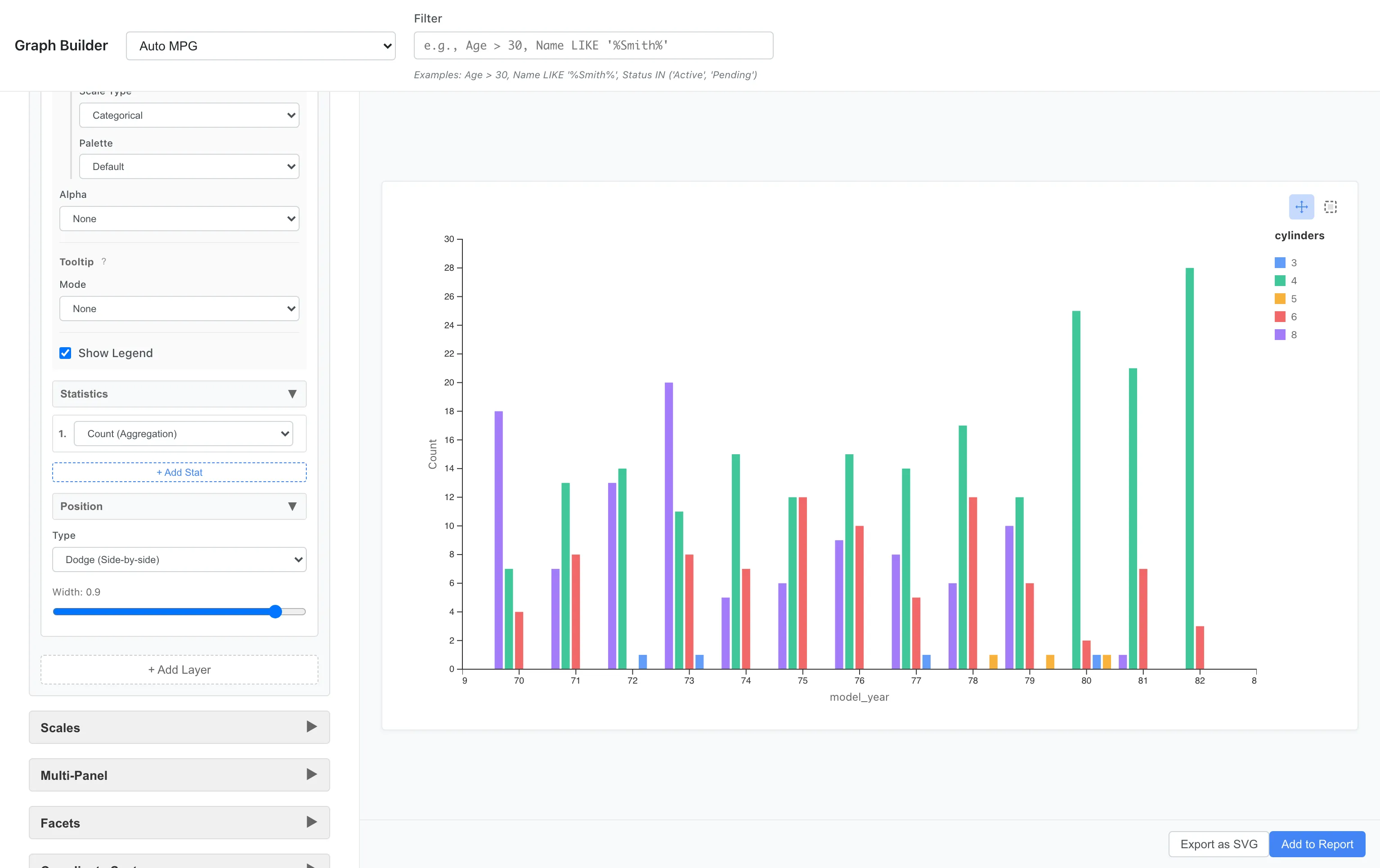
各シリンダー数の推移が比較しやすくなります。全体の構成比を見る場合は Stack、グループ間の値を直接比較する場合は Dodge が見やすくなります。
構成比で積み上げる
Position を Fill にすると、各 x 値での積み上げ棒を合計が 100% になるよう正規化します。カテゴリ間の構成比の推移を比較したい場合に有効です。
Position: Fill
点の重なりをずらす
Position を Jitter にすると、各点に小さなランダムな変位を加えて重なりを緩和します。x が数値の場合は X・Y 両方向、x がカテゴリカルの場合は Y 方向のみにずらします。同じ x 値に多くの観測が重なる Point の散布図で、点の密度を読み取りやすくなります。Dodge がカテゴリの枠を保ったまま横にずらすのに対し、Jitter はランダムな変位を加えるため、個々の点の位置は描画のたびに微小に変わります。
Coordinates - 座標系
軸の入れ替え
ヒストグラムや棒グラフを横向きにすると、長いラベルが読みやすくなります。
Aesthetics: x = mpg
Geometry: Bar
Statistics: Bin
Coordinates: Flipped
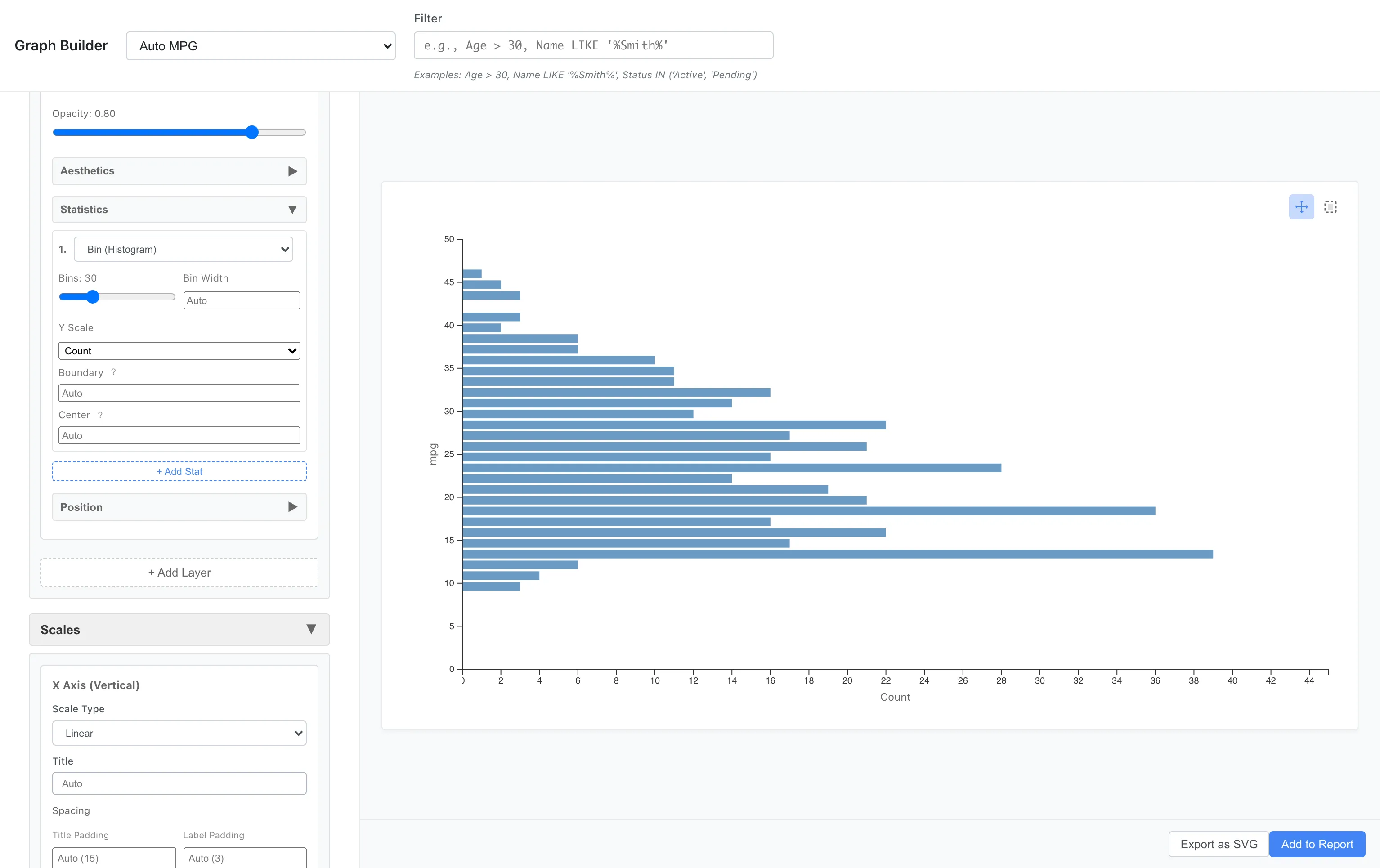
縦軸と横軸が入れ替わり、ヒストグラムが横向きに表示されます。カテゴリ名が長い場合や、縦方向のスペースを有効活用したい場合に便利です。
Facets - ファセット分割
カテゴリごとにグラフを分割して並べることで、サブグループの比較が容易になります。Facets セクションには2つのタイプがあります:Facet Wrap(単一変数による分割)と Facet Grid(2変数による行列分割)。
Facet Wrap - 単一変数による分割
Facet Wrap は、1つの変数でデータを分割し、複数のパネルをグリッド状に配置します。 分割にはデータセットの任意の列を指定できます。ユニーク値の数が上限を超える列は選択できません。上限はデフォルトで 1 変数あたり 20 カテゴリ、パネル総数 50 で、いずれも Settings から変更できます。
Aesthetics: x = weight, y = mpg
Geometry: Point
Facets: Type = Facet Wrap (Single Variable)
Variable = cylinders
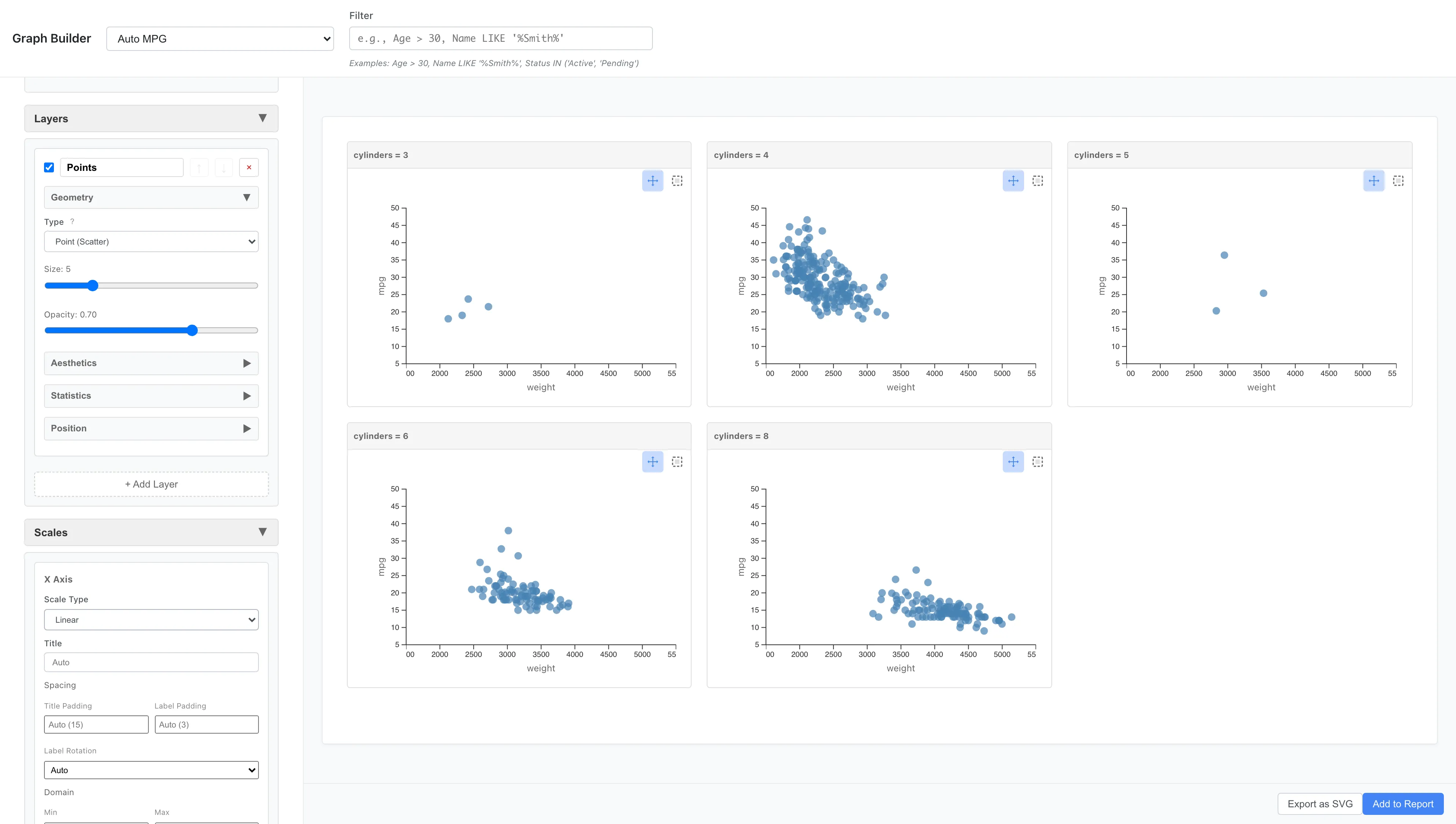
4気筒、6気筒、8気筒それぞれで、重量と燃費の関係を並べて比較できます。8気筒車は全体的に重く、燃費も悪い範囲に集中しています。
別の例として、originで分割することもできます:
Aesthetics: x = weight, y = mpg
Geometry: Point
Facets: Type = Facet Wrap (Single Variable)
Variable = origin
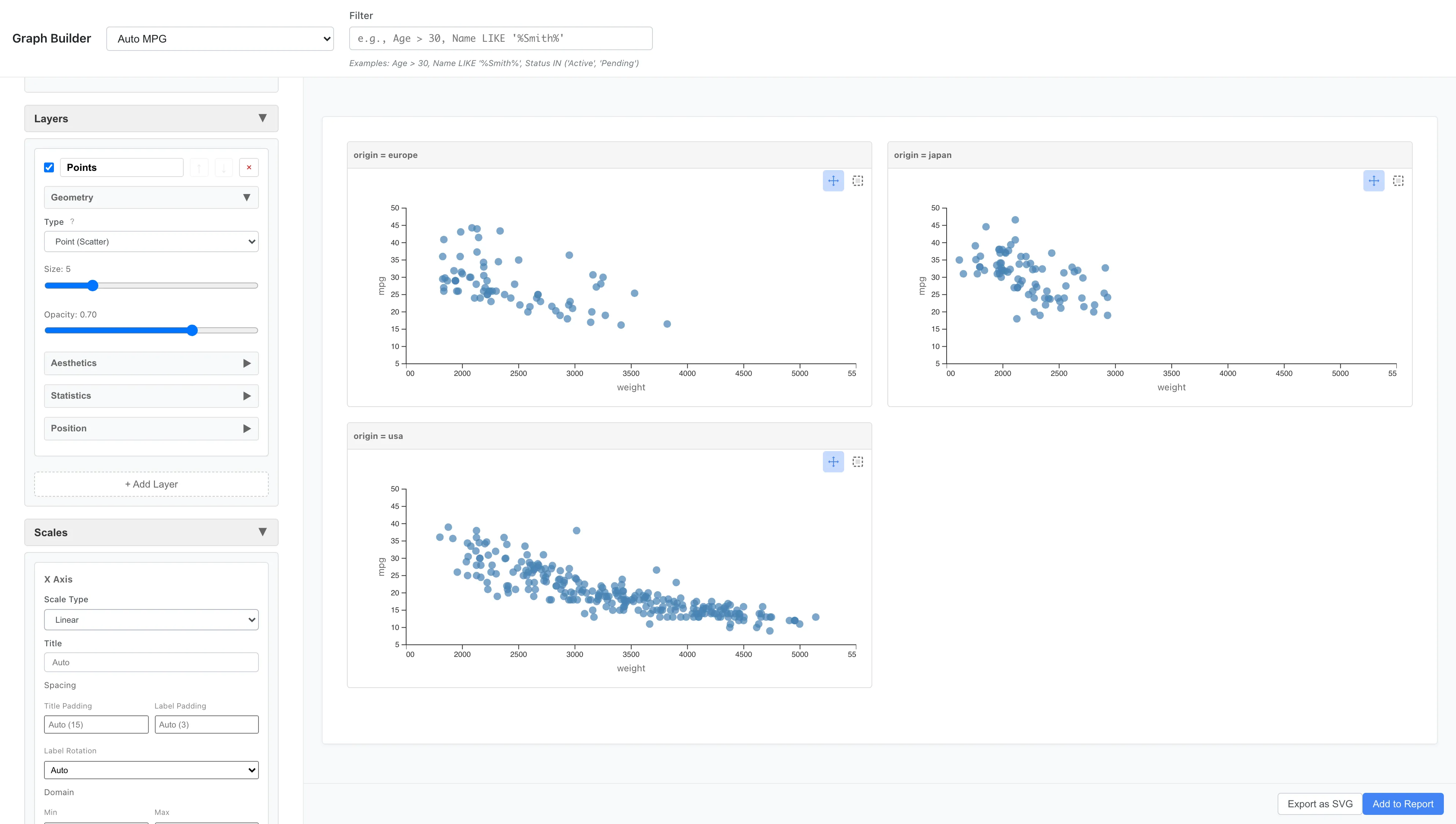
origin(europe、japan、usa)ごとにパネルが分割され、できるだけ正方形に近いグリッドに自動配置されます。3 パネルでは 2 列 × 2 行になります。横一列に並べたい場合は Columns に 3 を指定します。
Facet Wrap では、パネルの配置を制御するオプションがあります:
- Variable: 分割に使用する変数
- Columns: 1行あたりのパネル数(オプション)
- Rows: 行の数(オプション)
- Scales: 軸スケールの共有方法。Fixed(デフォルト)では全パネルで同じ軸範囲を使用します。Free X / Free Y / Free でパネルごとに軸範囲を独立させることができます
Columns のみを指定すると、行数が自動計算されます。Rows のみを指定すると、列数が自動計算されます。両方を省略すると、パネル数に応じて最適な配置が計算されます。
Facet Grid - 行列分割
Facet Grid は、1つまたは2つの変数で行(Rows)と列(Columns)の2方向にパネルを配置します。
Facets: Type = Facet Grid (Two Variables)
Rows = origin
Columns = cylinders
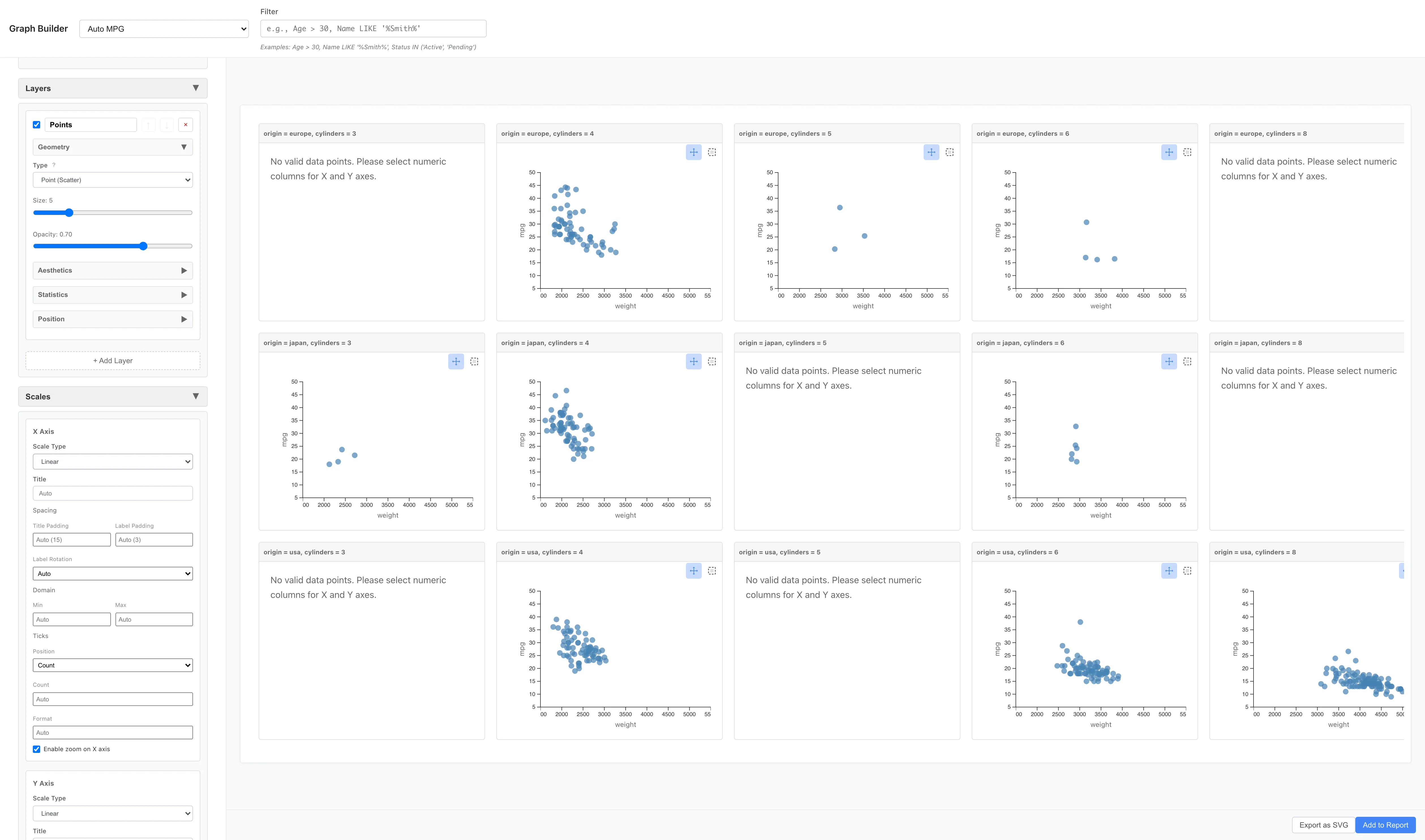
シリンダー数と原産地の組み合わせごとにグラフが配置されます
Scales - スケールの制御
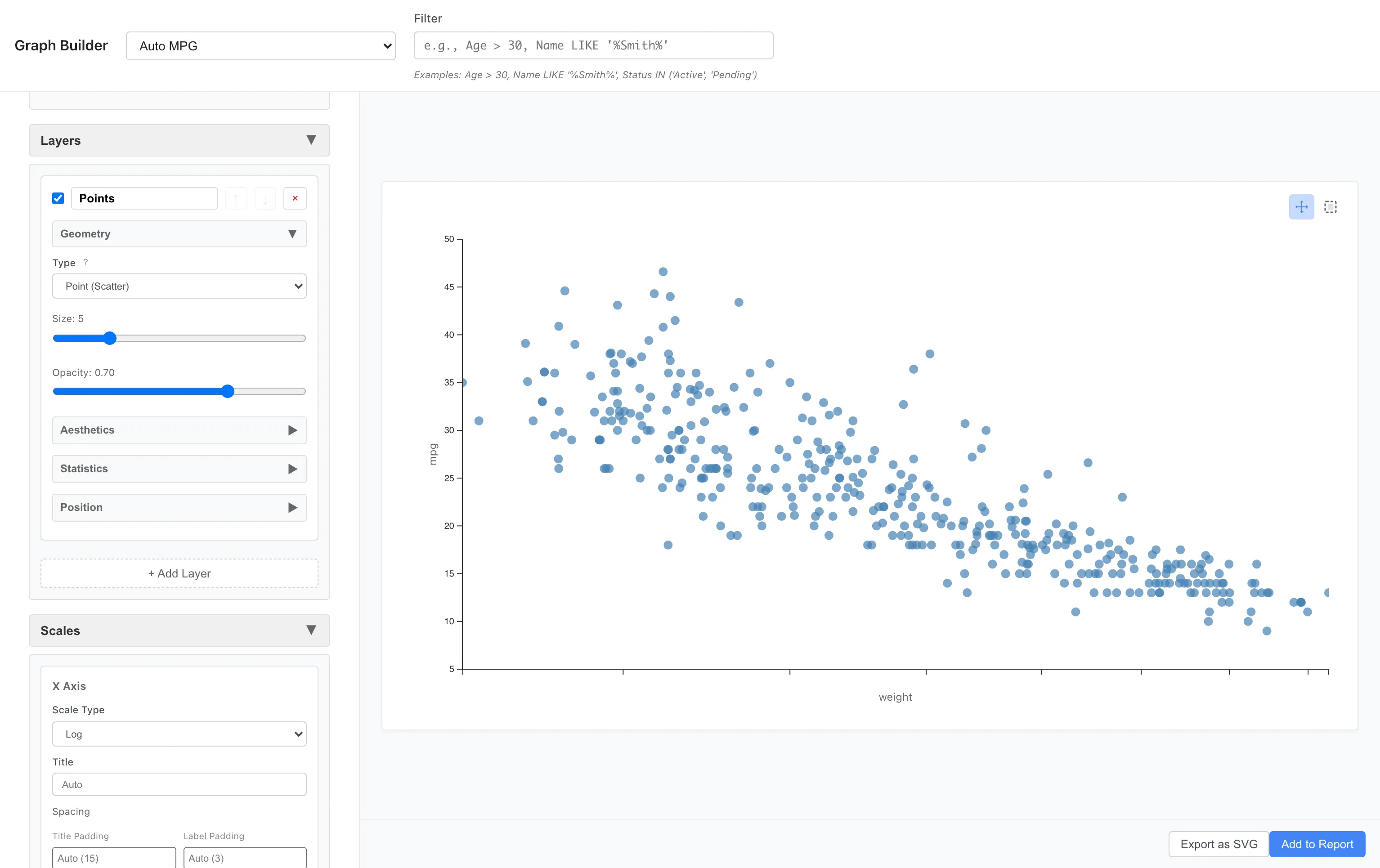
対数スケール
比率や倍率でデータを比較する場合や、裾の重い分布に対数スケールが有効です。対数は 0 以下の値(non-positive values)に定義されないため、0 以下を含む列に Log スケールを適用するとグラフは描画されず、影響を受けた軸・列名・件数を含むエラーが表示されます。Square Root スケールは 0 を取れますが、負値(negative values)には定義されないため、負値を含む列に適用すると同じ形式のエラーが表示されます。該当列に Log / Square Root スケールを使いたい場合は、事前にデータを正側にシフトするか、該当行を除外してください。Scales で指定する domain 下限(min)も、Log では 0 以下、Square Root では負値を受け付けません。
Scales: x = log
色スケール
どのような色を使うかを、色スケールで指定できます。
連続変数、カテゴリカル変数それぞれで使用可能なパレットが定義されています。利用可能なパレットの一覧は Custom Graph リファレンス を参照してください。
ここでは cylinders 変数の尺度を Ordinal に変更してから描画しています。尺度の変更は Data Table で列を右クリックし、Edit Scale of Measurement から行えます。
Aesthetics: x = weight, y = mpg, color = cylinders
Scales: Palette = Viridis
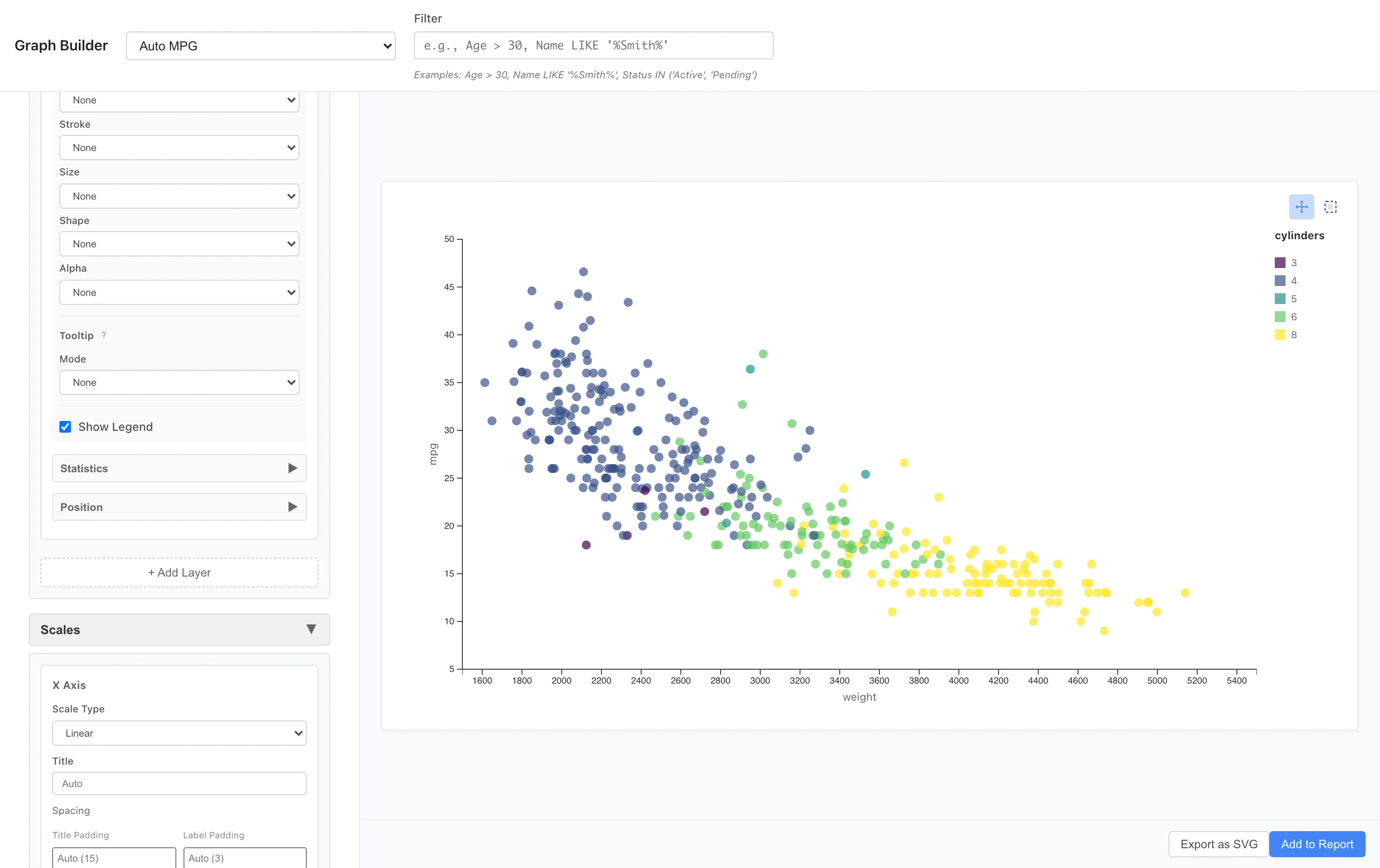
Viridis は知覚的に均一で色覚多様性に配慮したパレットです。cylinders(気筒数)のような順序尺度の変数に適用すると、カテゴリ数ぶんの色をパレット全域から等間隔にサンプリングするため、明度が順序に沿って単調に変化します。同種のパレットに Plasma、Inferno、Magma があります。
カテゴリの並び順は列の型で決まります。数値列は数値の昇順、順序尺度の enum 列は enum 定義の順、それ以外の列は文字列の昇順でソートされます。
Geometry/Statistics リファレンス
Geometry と Statistics の一覧は Custom Graph リファレンス を参照してください。
See also
- Custom Graph リファレンス - Geometry と Statistics の一覧
- グラフの作成 - Histogram、Scatter Plot などの基本グラフ
- レポート - グラフやテーブルをレポートにまとめる
このページの Markdown 版もあります。