チュートリアル: 用量反応データの Grouped Binomial GLM
殺虫剤の濃度を段階的に変えて昆虫に投与し、各濃度で何匹が死亡したかを記録したデータがあります。このチュートリアルでは、そのデータに Grouped Binomial GLM(ロジスティック回帰)を当てはめ、「濃度が上がると死亡率がどの程度上昇するか」を定量的に推定します。
ここでは用量反応データを題材にしますが、「ある条件で N 回試行して K 回成功した」という構造のデータであれば同じ手法が使えます。品質検査の合格数/検査数、疫学調査の発症数/対象者数などが典型例です。
分析の流れは次のとおりです。
- サンプルデータを読み込み、データの構造を確認します
- Binary 形式と Grouped 形式の違いを説明します
- 説明変数を対数変換します
- GLM タブで Grouped Binomial を設定し、分析を実行します
- 係数テーブルと Model Summary の読み方を説明します
- 診断プロットでモデルの妥当性を確認します
データを読み込む
ランチャー画面の Sample Data セクションから Dose Response をクリックしてください。プロジェクトが作成され、データが読み込まれます。
このデータは、殺虫剤の用量反応実験を模した合成データです。8段階の濃度それぞれについて、約50匹の昆虫を曝露し、死亡数を記録しています。
データの構造を確認する
Data Table タブを開くと、8行4列のデータが表示されます。
| 列名 | 内容 |
|---|---|
dose | 殺虫剤の濃度(mg/L)です。1.0 から 128.0 まで、おおむね2倍ずつ増加しています |
exposed | その濃度で曝露した昆虫の数です。各濃度で46〜52匹です |
dead | 死亡した昆虫の数です |
mortality_rate | 死亡率(dead / exposed)です。参考値として含まれていますが、分析には使いません |
全データを示します。
| dose | exposed | dead | mortality_rate |
|---|---|---|---|
| 1.0 | 50 | 1 | 0.020 |
| 2.0 | 48 | 3 | 0.063 |
| 4.0 | 46 | 8 | 0.174 |
| 8.0 | 50 | 28 | 0.560 |
| 16.0 | 47 | 42 | 0.894 |
| 32.0 | 52 | 49 | 0.942 |
| 64.0 | 49 | 47 | 0.959 |
| 128.0 | 51 | 50 | 0.980 |
mortality_rate を見ると、濃度 1.0 mg/L では 2% の死亡率ですが、128.0 mg/L では 98% に達しています。横軸を対数スケールにした散布図でプロットすると、S字型(シグモイド)のパターンが見えます。ロジスティック回帰はこのS字カーブをモデル化します。
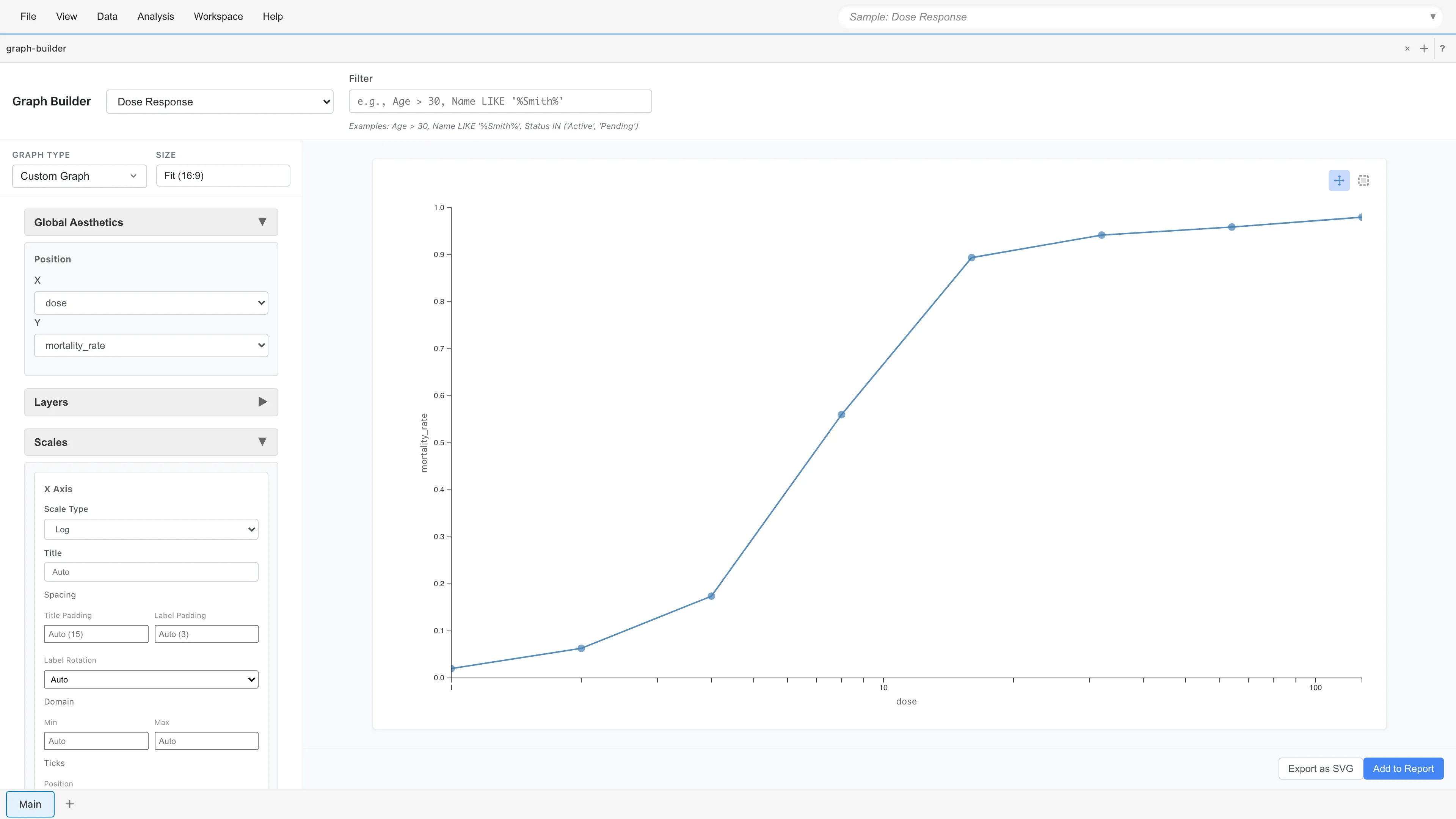
ここで重要なのは、各行が「1匹の昆虫が死亡したかどうか」ではなく「ある濃度で何匹中何匹が死亡したか」を表していることです。この形式を Grouped(集約)形式と呼びます。
Binary と Grouped の違い
Binomial GLM で扱えるデータ形式は2種類あります。
Binary 形式は個体ごとに1行を使います。50匹のうち3匹が死亡したデータを Binary で表すと50行必要です。1匹ずつ「死亡 = 1」「生存 = 0」を記録します。臨床試験の患者個人データなど、個体レベルの共変量がある場合に使います。
Grouped 形式は条件ごとに1行です。同じデータを dead = 3, exposed = 50 の1行で表せます。用量反応実験、品質検査の合格率、疫学調査の発症率など、条件ごとに集計されたデータはこの形式が自然です。
条件内の個体が同質(個体レベルの共変量がない)であれば、係数の推定値と標準誤差はどちらの形式でも一致します。ただし対数尤度には形式ごとに異なる定数項(二項係数)が含まれるため、対数尤度の絶対値と AIC は Binary と Grouped で一致しません。AIC で比較するときは同じ形式どうしに限ります。Grouped では応答変数を割合 (成功数/試行数)とし、試行数 を重みとして推定エンジンに渡します。今回のデータは条件(濃度)ごとに集計されているので、Grouped 形式を使います。
説明変数を対数変換する
散布図で確認したとおり、dose と mortality_rate の関係は対数スケールでS字型です。GLM は対数オッズと説明変数の間に線形な関係を仮定するため、dose をそのまま使うと仮定に合いません。dose の対数を説明変数にします。
Data > Add Columns... を選択します。Add Columns タブが開きます。
- Column name に
log_doseと入力します - SQL expression に
ln(dose)と入力します
Preview をクリックして結果を確認します。Output Name にデータセット名を入力し、Save as Dataset をクリックすると、元のデータに log_dose 列が追加された新しいデータセットが作成されます。
GLM タブを開く
メニューバーから Analysis > Generalized Linear Model (GLM)... を選択します。GLM タブが開きます。
データセットを選択する
Dataset ドロップダウンで、Add Columns で作成した派生データセットを選択します。
分布ファミリーを設定する
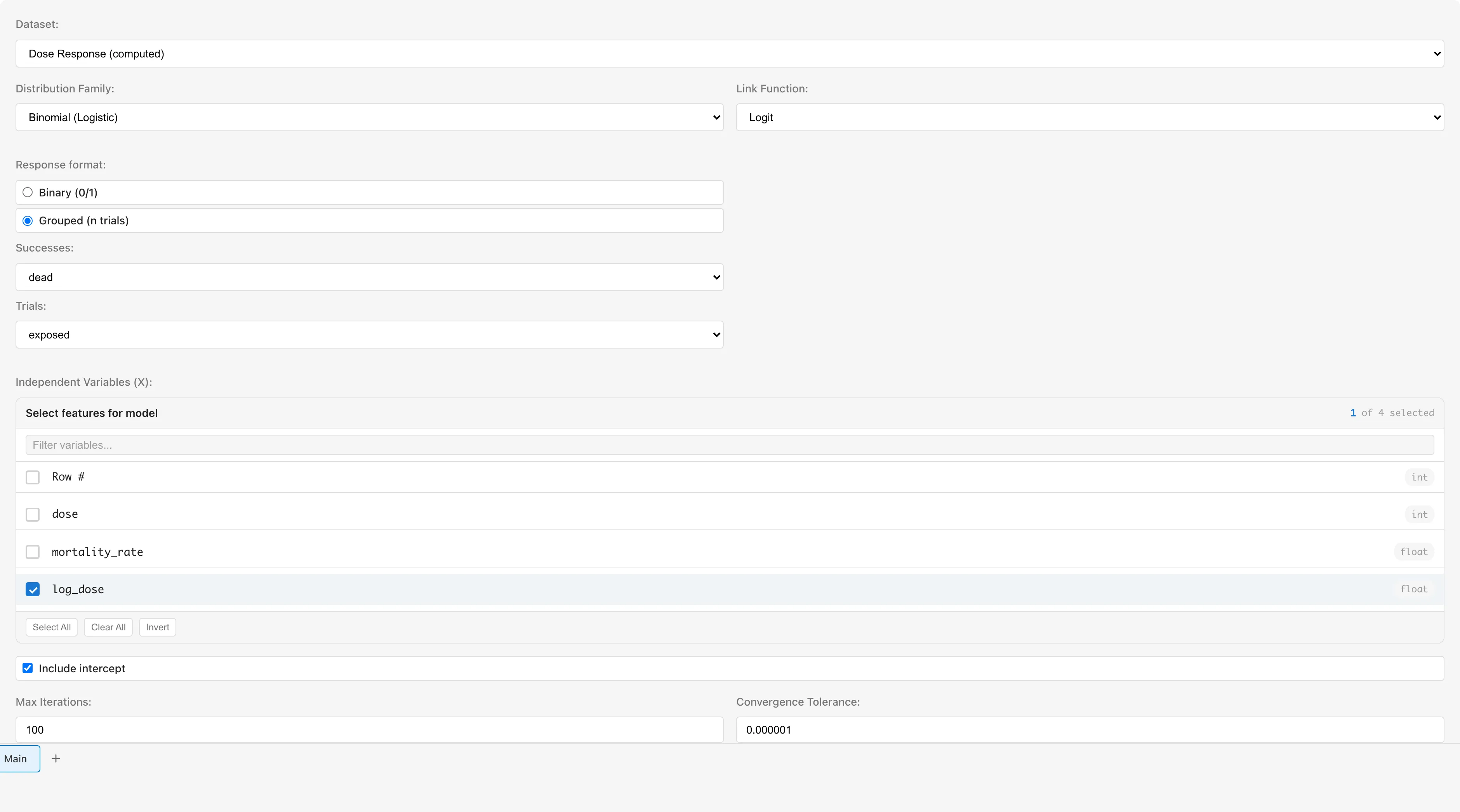
Distribution Family で Binomial (Logistic) を選択します。
Binomial を選ぶと Response format の選択肢が表示されます。デフォルトは Binary (0/1) です。今回は集約データなので、Grouped (n trials) を選択してください。
Grouped を選択すると、Successes と Trials の2つのドロップダウンが表示されます。
- Successes:
deadを選択します。死亡数が「成功」(関心のあるイベント)です - Trials:
exposedを選択します。曝露数が試行回数です
MIDAS はこの指定をもとに、内部で応答変数を (死亡率)に変換し、試行数 exposed を重みとして推定に使います。
説明変数を選択する
Predictor Variables (X) で log_dose にチェックを入れます。
Link Function はデフォルトの Logit のままにします。
リンク関数は「確率をどう変換して直線で表すか」を決めます。死亡率(確率 )は 0 から 1 の範囲に収まりますが、回帰式 の値は から までどこにでも行きます。このままでは回帰式の出力を確率として解釈できません。
Logit リンクはこのギャップを埋めます。確率 をオッズ (「死亡する確率 / 生存する確率」の比)に変換し、さらにその対数を取ります。この を対数オッズ(logit)と呼びます。対数オッズは から の値を取るので、回帰式の出力と直接つなげられます。
Binomial ファミリーでは Logit がデフォルトのリンク関数で、特別な理由がなければ変更する必要はありません。
Include intercept はオンのままにします。
分析を実行する
Run GLM をクリックします。進捗ダイアログが表示され、各反復の逸脱度(Deviance)が表示されます。このデータは8行しかないので、数秒で完了します。完了ダイアログが表示されたら OK をクリックします。
逸脱度(Deviance)とは: 「このモデルはデータをどれだけ説明できていないか」を表す数値です。OLS 回帰の残差平方和と類似する役割を果たします(Gaussian ファミリーでは一致します)。値が小さいほどモデルの当てはまりが良く、反復ごとに減少していれば推定が進んでいることを意味します。
Model Summary を確認する
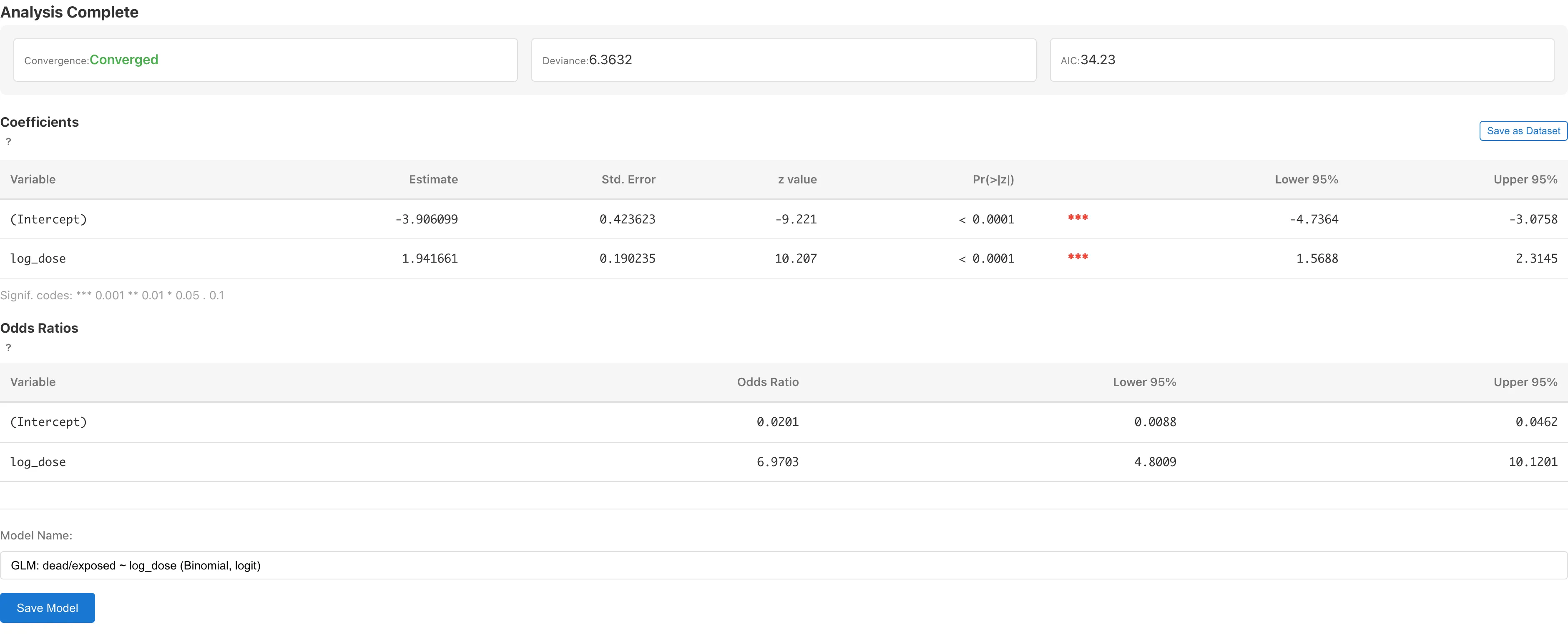
結果画面の上部に Model Summary が表示されます。
| 指標 | 意味 |
|---|---|
| Convergence | 推定が収束したかどうかを示します。「Converged」と表示されていれば正常です |
| Deviance | 残差逸脱度です。モデルがデータにどの程度適合しているかを示します。値が小さいほど当てはまりが良く、残差の自由度(、ここでは )と併せて評価します。数理的な背景は補遺を参照してください |
| AIC | 赤池情報量規準です。同じデータに同じ形式で当てはめた複数モデル間で、当てはまりとパラメータ数のトレードオフを比較する相対指標です。絶対値には意味がなく、値が小さいモデルを選びます。このチュートリアルでは1つのモデルのみ扱いますが、説明変数やリンク関数を変えた複数のモデルを作成し、AIC で比較できます |
係数テーブルを読む
Coefficients テーブルには2行あります。
(Intercept)
切片は log_dose = 0(つまり dose = 1)のときの対数オッズ を表します。
log_dose
log_dose の係数は、log_dose が1単位増えたとき(dose が 倍になったとき)の対数オッズの変化量です。正の値なら「濃度が上がると死亡確率が上がる」ことを意味します。
係数テーブルの各列の意味は次のとおりです。
| 列 | 意味 |
|---|---|
| Estimate | 回帰係数 の推定値です。Logit リンクなので対数オッズのスケールです |
| Std. Error | 推定値の標準誤差です |
| Lower 95% / Upper 95% | 95% Wald 信頼区間です |
このデータでの係数テーブルの値を示します。
| Estimate | Std. Error | Lower 95% | Upper 95% | |
|---|---|---|---|---|
| (Intercept) | -3.9061 | 0.4236 | -4.7364 | -3.0758 |
| log_dose | 1.9417 | 0.1902 | 1.5688 | 2.3145 |
係数をオッズ比として解釈する
Logit リンクの係数は対数オッズスケールなので、そのままでは直感的に読みにくいです。 を計算するとオッズ比になります。MIDAS は係数テーブルの OR 列にオッズ比を、exp(Lower 95%) / exp(Upper 95%) 列にその信頼区間を表示します。
| OR | exp(Lower 95%) | exp(Upper 95%) | |
|---|---|---|---|
| (Intercept) | 0.0201 | 0.0088 | 0.0462 |
| log_dose | 6.9703 | 4.8009 | 10.1201 |
OR 列は で、係数テーブルの Estimate を指数変換した値です。exp(Lower 95%) / exp(Upper 95%) は Wald 信頼区間を同様に指数変換したものです。
log_dose の係数が のとき、 は「dose が 倍になったときのオッズ比」です。log_dose のオッズ比は 6.97 で、95% 信頼区間は 4.80 から 10.12 です。95% 信頼区間は、95% 信頼水準のもとでデータとモデルに整合するオッズ比の範囲を示し、この例では区間全体が 1 を上回ります。区間の幅は推定の不確実性を反映します1。
特定の条件での予測確率を知りたい場合は、モデルを保存してから GLM の予測機能を使ってください。
モデルを保存する
Model Name フィールドにモデル名を入力します。デフォルトで「GLM: dead/exposed ~ log_dose (Binomial, logit)」のような名前が自動生成されます。Save Model をクリックします。
モデルを保存すると、元のデータセットに診断統計量(fitted_values、deviance_residuals、pearson_residuals、leverage、cooks_distance 等)を追加した派生データセットが自動生成されます。
保存後に View Diagnostics ボタンと View Model Details ボタンが表示されます。
診断プロットを確認する
View Diagnostics をクリックすると、GLM Diagnostics タブが開きます。
MIDAS では Gaussian ファミリー以外の GLM では Normal Q-Q Plot を表示しません。Deviance 残差の正規近似は、Binomial の Grouped データで試行数が大きい場合には成り立ちますが、Binary データや試行数が小さい場合には精度が悪いため、ファミリー全体として非表示にしています。残りの3つのプロットで確認する点は次のとおりです。
Residuals vs Fitted
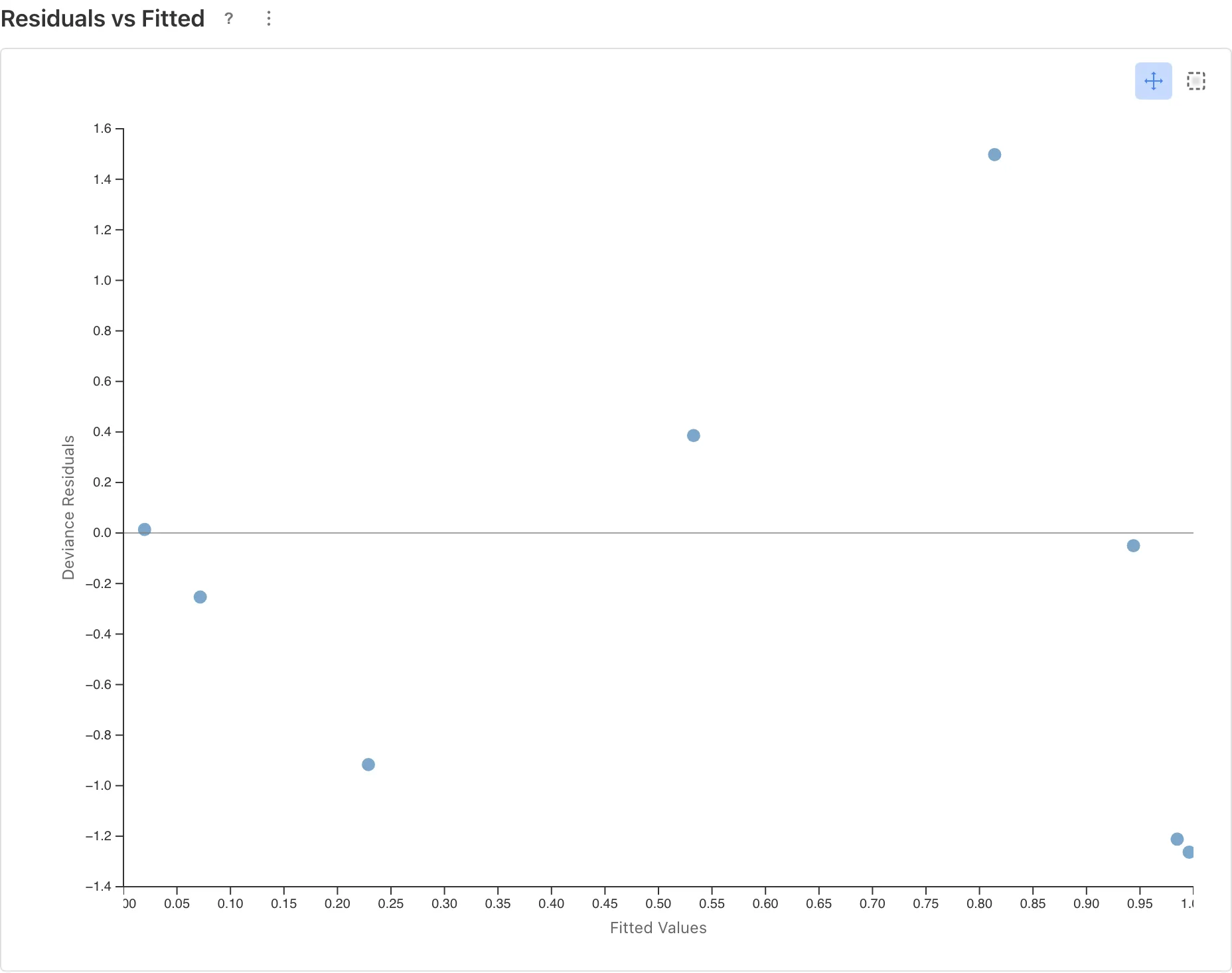
横軸が予測値(Fitted Values)、縦軸が残差(Deviance Residuals)です。残差はモデルの予測と実際のデータのずれを表します。
点がゼロの水平線の周りにランダムに散らばっていれば、モデルはデータの傾向を適切に捉えています。データ点が少ない場合(この例では8点)、パターンの有無の判断は難しくなります。明確なパターンがなければ重大な問題はないと判断しますが、微妙なずれは検出できません。
曲線的なパターン(U 字や逆 U 字など)が見える場合、予測値が大きい領域や小さい領域でモデルの当てはまりが系統的に悪化していることを意味します。GLM は対数オッズと説明変数の間に線形な関係を仮定しているので、実際の関係が線形でなければ、特定の予測値の範囲で残差が偏ります。この場合、モデルの指定を見直す必要があります。具体的には、説明変数の変換やリンク関数の変更が候補です。
Scale-Location
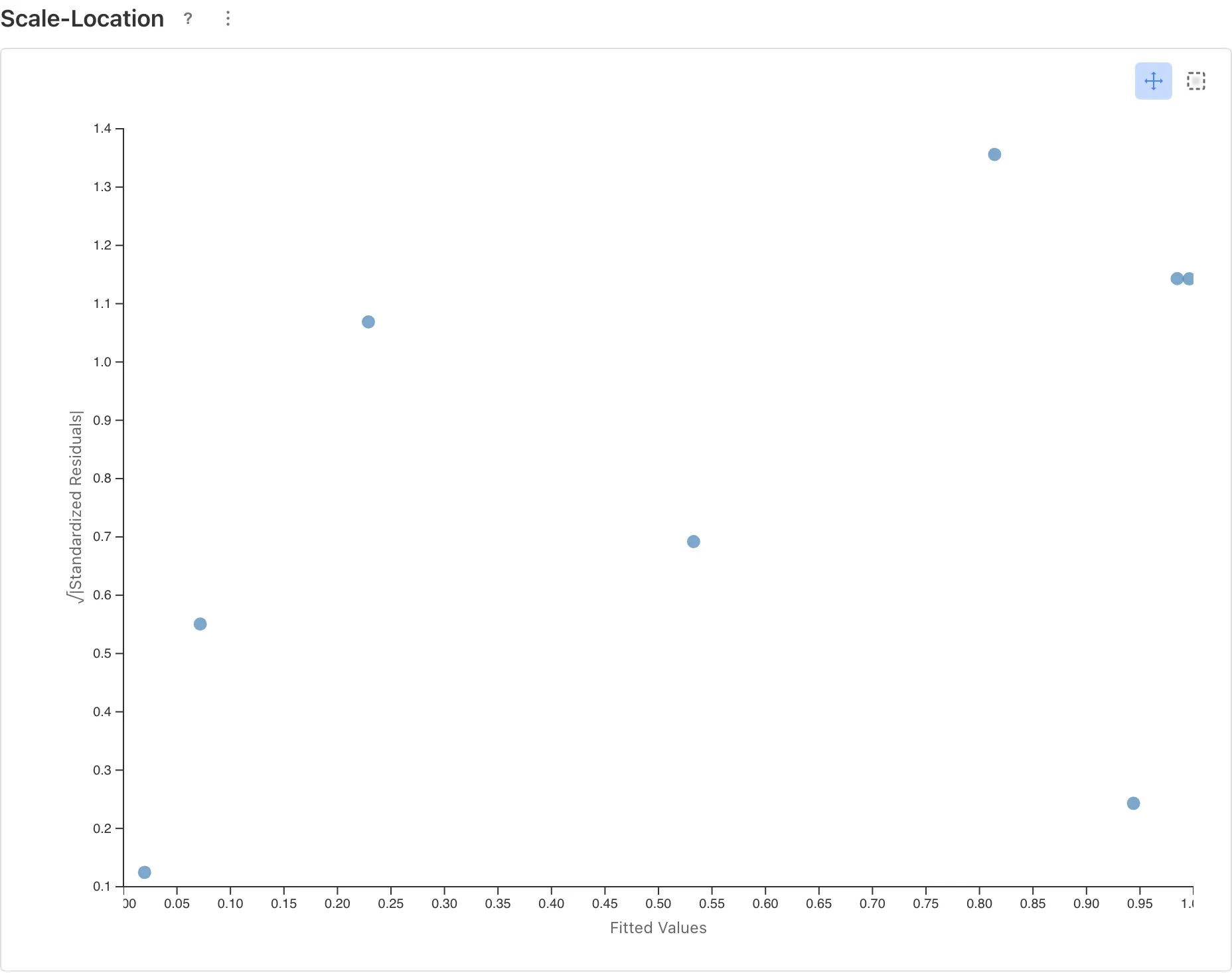
モデルが仮定する分散構造がデータに合っているかを確認します。Binomial では分散が でモデルに内在しているため、右上がりの傾向が見える場合は過分散の兆候です。GLM のページの過分散に関する説明も参照してください。
Residuals vs Leverage
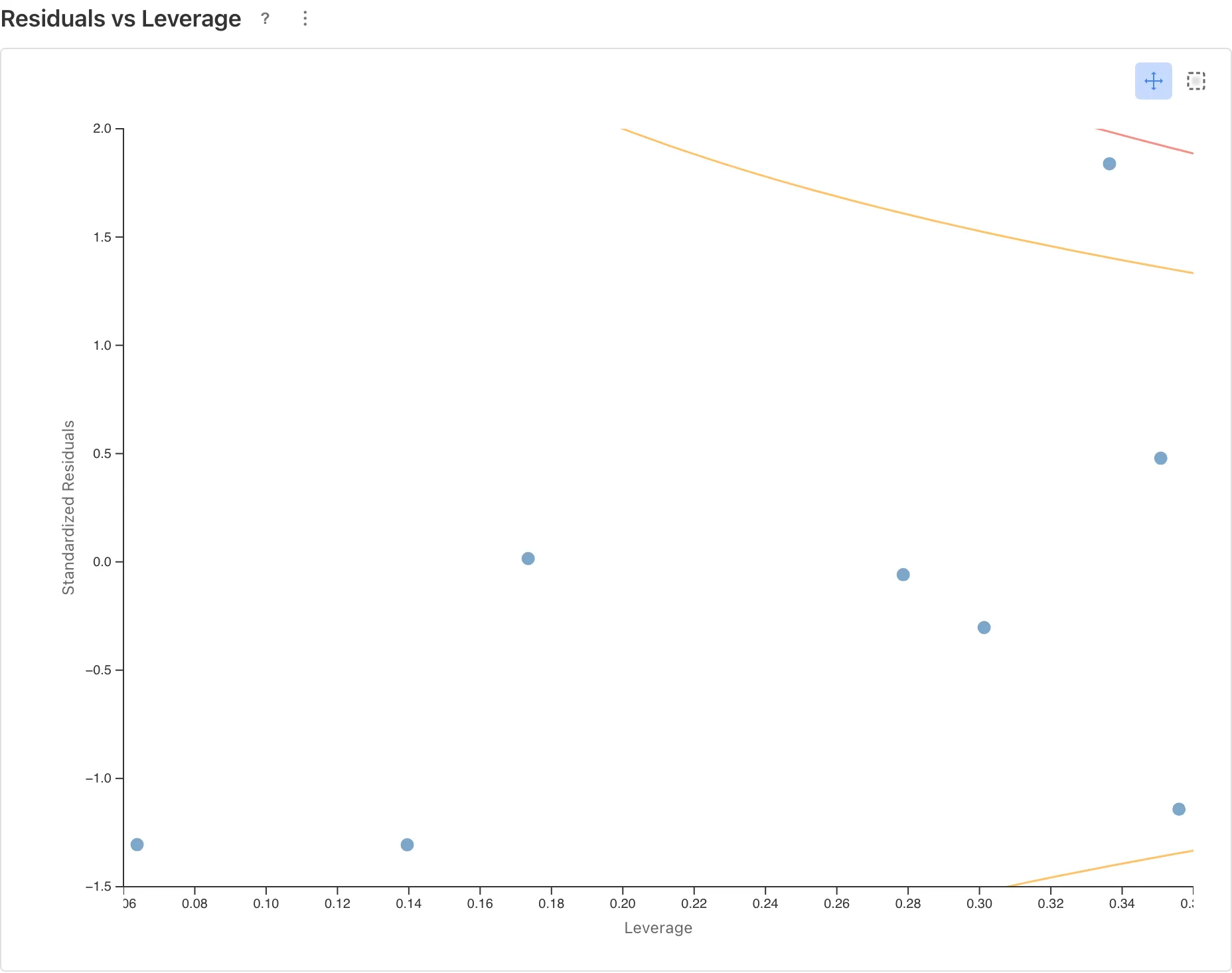
影響の大きい観測値を特定します。Cook's Distance の等高線(: オレンジ破線、: 赤破線)の外側にある点は、その1点を除くだけで推定結果が大きく変わる可能性があります。
分析結果をまとめる
モデルと診断プロットの確認が終わったので、冒頭の問い「濃度が上がると死亡率がどの程度上昇するか」に答えます。
濃度と死亡オッズの関係
log_dose の係数は 1.94 です。 なので、濃度が 倍になると死亡のオッズが約7倍に増加します。
dose は倍々(2倍ずつ)のスケールなので、2倍に換算すると便利です。 で、濃度を2倍にすると死亡のオッズは約3.8倍になります。
LD50 の推定
LD50 は「昆虫の50%が死亡する濃度」です。LD50 は用量反応分析に固有の派生量であり、GLM タブでは算出機能を提供していません。係数テーブルの値から計算します。死亡率50%のとき対数オッズは0なので、 を解くと次のとおりです。
この殺虫剤は約 7.5 mg/L の濃度で昆虫の半数を致死させると推定されます。係数テーブルの Save as Dataset でデータセット化すれば、SQL タブでも計算できます。
Delta 法による区間推定
上の値は点推定です。区間推定には と の共分散が必要です。Save as Dataset は係数テーブルと分散共分散行列を別々のデータセットとして保存します。SQL タブで両方を参照すれば、Delta 法で LD50 の 95% 信頼区間を計算できます。
の分散を Delta 法の1次 Taylor 展開で近似し、対数スケールで信頼区間を構成してから exp で変換します。この変換により、元のスケールでは非対称な区間になります1。
WITH coef AS (
SELECT
MAX(CASE WHEN Variable = '(Intercept)' THEN Estimate END) AS b0,
MAX(CASE WHEN Variable = 'log_dose' THEN Estimate END) AS b1
FROM [GLM Coefficients - bliss1947]
),
cov AS (
SELECT
MAX(CASE WHEN row_var = '(Intercept)' AND col_var = '(Intercept)' THEN value END) AS v00,
MAX(CASE WHEN row_var = '(Intercept)' AND col_var = 'log_dose' THEN value END) AS c01,
MAX(CASE WHEN row_var = 'log_dose' AND col_var = 'log_dose' THEN value END) AS v11
FROM [GLM Coefficients - bliss1947 - Covariance]
)
SELECT
exp(-b0 / b1) AS ld50,
exp(-b0/b1 - 1.96 * sqrt(
v00/(b1*b1) + (b0*b0)*v11/(b1*b1*b1*b1) + 2*(-b0)*c01/(b1*b1*b1)
)) AS lower_95,
exp(-b0/b1 + 1.96 * sqrt(
v00/(b1*b1) + (b0*b0)*v11/(b1*b1*b1*b1) + 2*(-b0)*c01/(b1*b1*b1)
)) AS upper_95
FROM coef, cov
データセット名はユーザーが Save as Dataset 時に指定した名前に依存します。上の例では GLM Coefficients - bliss1947 を使用しています。
モデルの指定を誤るとどうなるか
ここでは比較のために、dose を対数変換せずにそのまま説明変数として使ってみます。モデルは を仮定しますが、実際の関係は log(dose) と対数オッズの間にあるので、この仮定はデータに合いません。
Residuals vs Fitted プロットにその問題が現れます。
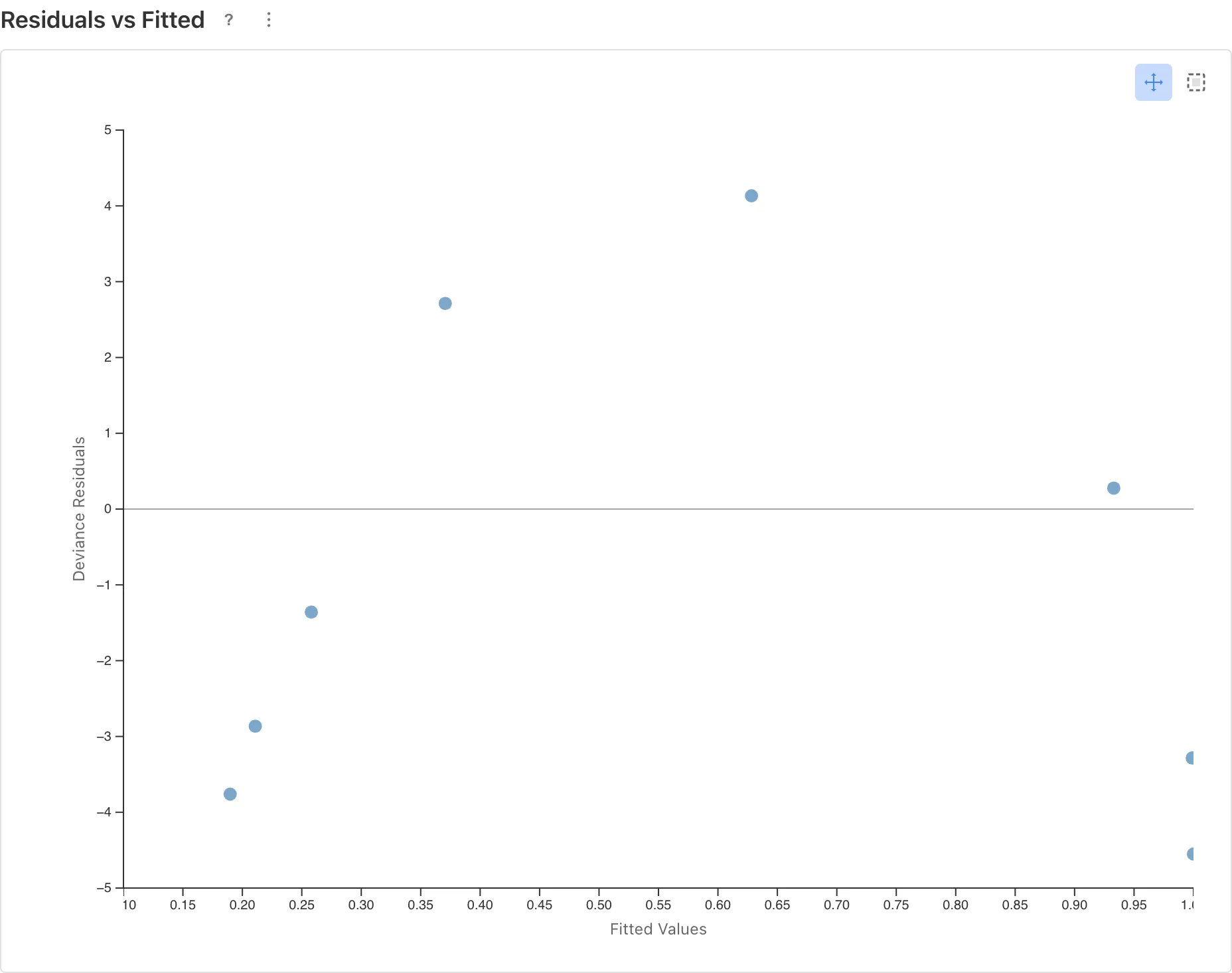
逆 U 字のパターンが見えます。予測値が中程度のあたりで残差が正(モデルが実際より低く予測)、予測値の両端で残差が負(モデルが実際より高く予測)になっています。これは対数オッズと dose の間の関係が線形ではないことを示しています。
このようなパターンが診断プロットに現れたら、モデルの指定に問題がないか見直してください。説明変数の変換はその対処法のひとつですが、リンク関数の変更や説明変数の追加・削除が適切な場合もあります。
振り返り
このチュートリアルで扱った内容を整理します。
- データ形式の選択: 個体データなら Binary、集計データなら Grouped を使います。条件ごとの成功数/試行数で記録されたデータには Grouped が適しています
- 説明変数の変換: 用量反応データでは
doseの対数変換が標準的です。Add Columns タブで変換列を作成してから GLM に渡します - 係数の解釈: Logit リンクの係数は対数オッズスケールです。 でオッズ比に変換して解釈します
- モデルの検証: Deviance を残差の自由度と比較し、診断プロットでパターンがないかを確認します
分布ファミリーやリンク関数の数理的な背景は GLM の基礎 で説明しています。
補遺
Deviance の漸近分布
Binomial GLM や Poisson GLM では分散パラメータ が理論的に固定されます。この条件のもとで、正しく指定されたモデルの残差 Deviance は漸近的に 分布に従います( は観測数、 はパラメータ数)。したがって Deviance を残差の自由度 で割った値()が1前後であれば、モデルの仮定する分散構造がデータと整合していることを示唆します。この比が1から大きく離れている場合は過分散の可能性があります。
この 近似は各群の試行数が十分大きい Grouped データで成り立ちます。Binary データでは各観測の試行数が1なので近似の精度が低く、Deviance/df を過分散の指標として使えません。
Wald 信頼区間の限界
このチュートリアルの係数テーブルに表示される信頼区間は Wald 信頼区間()です。Wald 区間は の標本分布の正規近似に依存するため、標本が小さいと被覆確率が名目水準(95%)を下回ります。このチュートリアルのデータは8群と少ないため、信頼区間の幅を過度に精密なものとして解釈しないでください。
脚注
このページの Markdown 版もあります。