Generalized Linear Model(一般化線形モデル)
GLM タブでは、一般化線形モデルによる回帰分析を実行できます。GLM は応答変数の分布(ファミリー)、線形予測子 、リンク関数 の3要素で定義され、OLS を指数型分布族に拡張した枠組みです。オフセット項が未指定の場合は です。数理的な背景はGLM の基礎を参照してください。
Linear Regression タブで実行する OLS 回帰は、GLM の特殊ケース(Gaussian ファミリー + Identity リンク)に相当します。OLS の詳細は線形回帰分析を参照してください。
分布ファミリーとリンク関数
MIDAS で選択可能な分布ファミリーとリンク関数を以下に示します。
分布ファミリーの選び方
| ファミリー | UI 表記 | 分散関数 | 用途 |
|---|---|---|---|
| Gaussian | Gaussian (Normal) | 連続値の応答変数。通常の線形回帰と同等 | |
| Binomial | Binomial (Logistic) | 二値データ(0/1)や割合データ。ロジスティック回帰 | |
| Poisson | Poisson (Count) | カウントデータ(イベントの発生回数など)。平均と分散が等しいと仮定 | |
| Gamma | Gamma (Positive Continuous) | 正の連続値で右に裾が長い分布(待ち時間、費用など) | |
| Negative Binomial | Negative Binomial (Overdispersed Count) | 過分散のあるカウントデータ。Poisson の等分散仮定 が成り立たない場合に使用 |
ファミリーの選択は応答変数の性質で決まります。二値なら Binomial、非負整数なら Poisson(または過分散があれば Negative Binomial)、正の連続値で変動係数がほぼ一定(分散が平均の2乗に比例)なら Gamma が自然な選択です。
Binomial ファミリーでは、個体ごとの0/1データ(Binary)に加えて、成功数/試行数の集約データ(Grouped)にも対応しています。詳細は 用量反応データの Grouped Binomial GLM を参照してください。
リンク関数
リンク関数は線形予測子 と応答変数の期待値 を結びつける単調関数 です。Negative Binomial を除き、各ファミリーの正準リンク関数をデフォルトのリンク関数としています。Negative Binomial の正準リンクは ですが、 を推定するとリンク関数自体が反復ごとに変わり推定が不安定になるため、実用上は Log リンクをデフォルトとしています。
| ファミリー | デフォルトリンク | 利用可能なリンク |
|---|---|---|
| Gaussian | Identity | Identity, Log |
| Binomial | Logit | Logit, Probit |
| Poisson | Log | Log, Identity |
| Gamma | Inverse | Inverse, Log, Identity |
| Negative Binomial | Log | Log |
| リンク関数 | 数式 | 説明 |
|---|---|---|
| Identity | 変換なし。Gaussian の正準リンク | |
| Logit | 対数オッズ変換。Binomial の正準リンク | |
| Log | 対数変換。Poisson の正準リンク。 を保証 | |
| Inverse | 逆数変換。Gamma の正準リンク | |
| Probit | 標準正規分布の逆累積分布関数。潜在正規変数モデルに対応 |
正準リンクは最尤推定の安定性に優れています。非正準リンクは係数の解釈しやすさから選ばれることがありますが、収束が不安定になる場合があります。正準リンクの数理的な性質はGLM の基礎を参照してください。
基本的な使い方
以下の例では Auto MPG データセットを使用しています。
GLM を開く
メニューバーから Analysis > Generalized Linear Model (GLM)... を選択します。
変数の設定
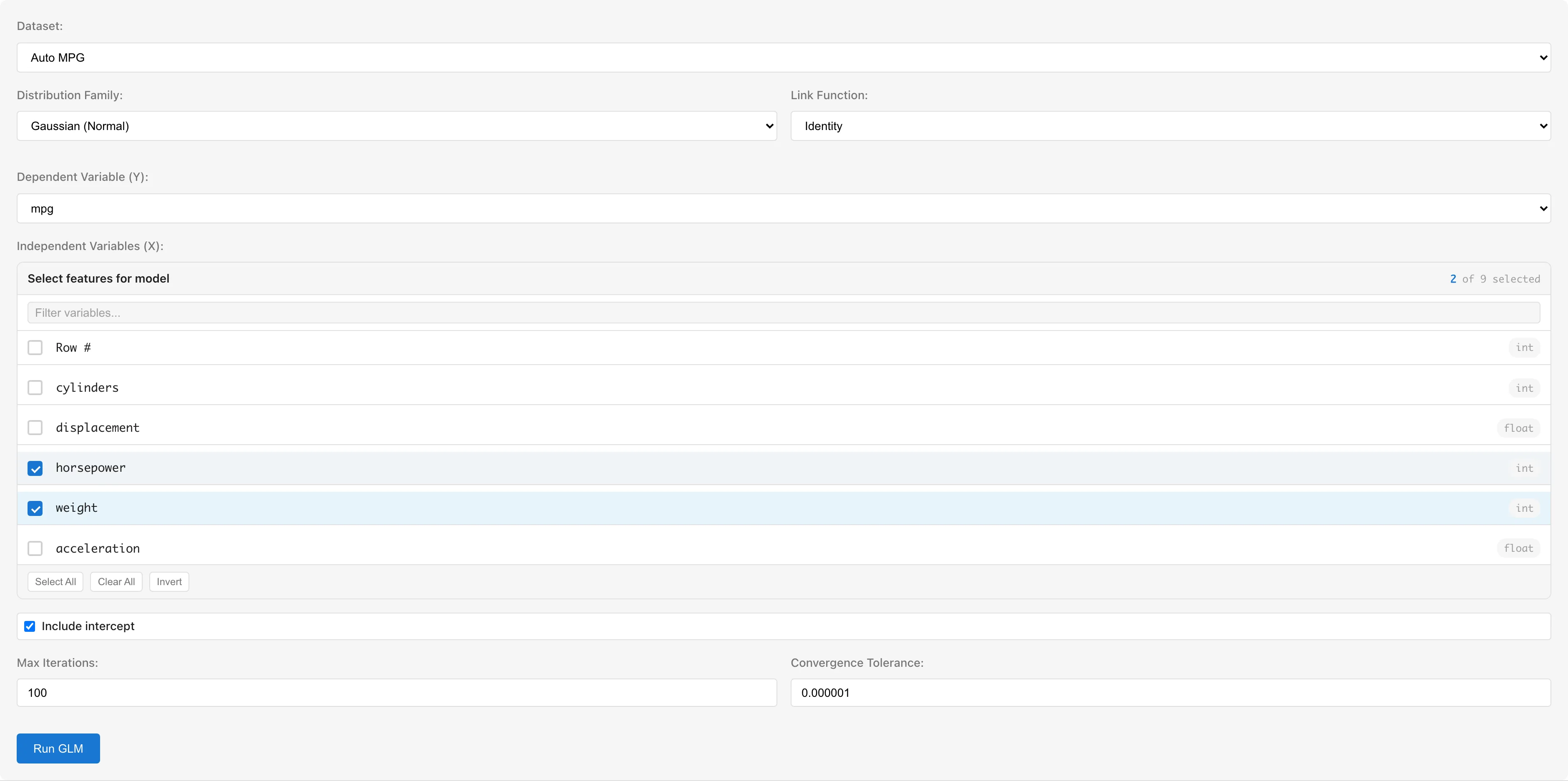
Dataset で分析対象のデータセットを選択します。
Response Variable (Y) で目的変数を選択します。数値型(int64, float64)および boolean 型の列が選択できます。boolean 型は自動的に true=1, false=0 に変換されます。Binomial ファミリーの場合は0/1または boolean の列を使用します。
Predictor Variables (X) で説明変数を選択します。チェックボックスで複数の変数を選択できます。カテゴリ尺度(名義・順序)や日付型の列は選択できません。カテゴリ変数を使用する場合は、事前に Dummy Coding タブで数値変換が必要です(注意事項を参照)。
Distribution Family で分布ファミリーを選択します。ファミリーを変更すると、リンク関数がそのファミリーのデフォルトに自動で切り替わります。
Link Function でリンク関数を選択します。選択可能なリンク関数はファミリーによって異なります。
Include intercept で切片項の有無を設定します。デフォルトでオンです。
Negative Binomial の追加設定
Negative Binomial ファミリーを選択した場合、形状パラメータ の設定オプションが表示されます。Negative Binomial 分布の分散は (NB2 と呼ばれるパラメータ化)であり、 が過分散の程度を制御します。
- 自動推定(デフォルト): プロファイル尤度法で を推定します。外側ループで を最適化し、内側ループで IRLS により を推定するネストされた最適化です
- 手動指定: Manually specify θ チェックボックスをオンにして値を入力します(0.1〜100、デフォルト1.0)。感度分析やモデル比較に有用です
の解釈:
- : Poisson 分布に収束()
- : 中程度の過分散
- : 強い過分散
- : 極端な過分散
オフセット変数
Offset Variable で、線形予測子に固定係数 1 で加えるオフセット項を設定できます。オフセットは推定対象のパラメータではなく、各観測で既知の値です。
典型的な使用例はポアソン回帰でのレートモデリングです。イベントのカウント数を応答変数とし、観測期間の対数 をオフセットに設定すると、線形予測子は
となり、カウントではなくレート をモデリングします。 はレート比として解釈できます。
オフセットを設定すると null deviance にも影響します。null model は切片 + オフセットのモデルになるため、オフセットなしの場合と null deviance の値が異なります。
オフセット付きモデルを保存して予測を実行する場合、予測データセットにも同じ名前のオフセット列が必要です。予測時の線形予測子は として計算されます。
詳細オプション
- Max Iterations: IRLS の最大反復回数(デフォルト: 100)
- Convergence Tolerance: 係数の最大絶対変化量に基づく収束判定の閾値(デフォルト: 1e-6)
分析の実行
設定が完了したら、Run GLM ボタンをクリックします。
パラメータ推定には IRLS(Iteratively Reweighted Least Squares)を使用します(アルゴリズムの詳細)。進捗ダイアログに各反復の逸脱度が表示されるため、収束の様子を確認できます。Cancel ボタンで中止でき、収束履歴は Save as Dataset でデータセットとして保存できます。
結果の見方
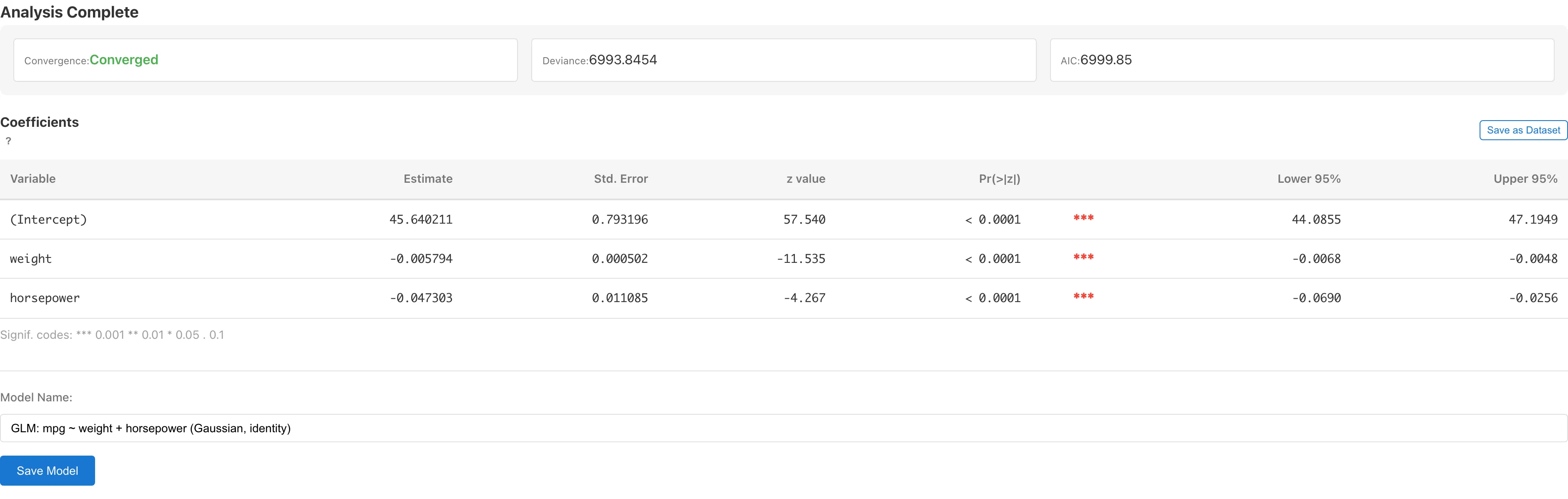
Model Summary
| 指標 | 説明 |
|---|---|
| Convergence | IRLS が収束したかどうか(反復回数つき) |
| Deviance | 残差逸脱度 。飽和モデルからの対数尤度の差に基づく適合度指標 |
| AIC | 赤池情報量規準 。 は推定パラメータの総数。同一ファミリー内でのモデル比較に使用します。ファミリーが異なるモデル間の比較は対数尤度の定数項の扱いが異なるため推奨しません。値が小さいほど良い |
| Shape Parameter () | Negative Binomial の場合のみ表示。 は過分散の程度を制御し、小さいほど過分散が強く、 で Poisson に収束します(Negative Binomial の追加設定を参照)。推定値か手動指定かも記載されます |
AIC の は推定パラメータの総数です。Poisson・Binomial では回帰係数(切片を含む)の数、Gaussian・Gamma では回帰係数の数に分散パラメータ(Gaussian: 、Gamma: )を加えた数です。Negative Binomial では を自動推定した場合のみ を に含めます。手動指定した は推定パラメータではないため含めません。 推定モデルと 固定モデルの AIC を比較する際はこの差に注意してください。
Coefficients(係数テーブル)
| 列 | 説明 |
|---|---|
| Variable | 変数名(切片は "(Intercept)") |
| Estimate | 回帰係数 の推定値(リンク関数のスケール) |
| Std. Error | Wald 標準誤差 。 は分散パラメータで、Poisson、Binomial、Negative Binomial( 推定時)では です |
| Lower N% / Upper N% | 信頼区間 。N は選択した信頼水準です。dispersion 推定ファミリーでは 、それ以外では (95% の場合 ) |
| OR / IRR / exp(Est.) | 。logit リンクではオッズ比 (OR)、Poisson・Negative Binomial の log リンクでは率比 (IRR)、Gamma・Gaussian の log リンクでは乗法的効果 exp(Est.) として表示されます。identity、inverse、probit リンクではこの列は表示されません |
| exp(Lower N%) / exp(Upper N%) | 、。link スケールの信頼区間を応答スケールに変換した値です。OR / IRR 列と同じ条件で表示されます |
Negative Binomial の 推定時に とするのは、過分散が分散関数の 項で既にモデル化されているためです。 でさらに過分散を吸収させる必要がないため、標準誤差は で計算します。 固定時は、指定した がデータの過分散を十分に捉えていない可能性があるため で推定します。
係数の解釈
係数はリンク関数のスケールで推定されるため、解釈にはリンク関数の逆変換を考慮する必要があります。
- Identity リンク: は の期待値の変化量そのもの(OLS と同じ解釈)
- Logit リンク: は説明変数を1単位変化させたときの対数オッズの変化量。 がオッズ比
- Log リンク: は の変化量。 が の期待値の乗法的変化
- Inverse / Probit リンク: 直接的な解釈が困難なため、予測値を通じた解釈が実用的
係数テーブルは Save as Dataset ボタンでデータセットとして保存し、CSV にエクスポートできます。保存には先にモデルを Save Model で保存しておく必要があります。係数データセットを具体的なモデルに紐付けることで、モデル削除時に係数データセットとレポート要素も一緒に削除され、再学習時にデータセットの内容が新しい fit の結果で更新されます。
保存されるデータセットの列は Variable, Estimate, Std. Error, Lower N%, Upper N% です。logit リンクと log リンクでは exp 変換列(OR / IRR / exp(Est.)、exp(Lower N%)、exp(Upper N%))も含まれます。
モデルの保存と診断
モデルの保存
Model Name フィールドにモデル名を入力し、Save Model をクリックします。モデル名はデフォルトで「GLM: Y ~ X1 + X2 (Family, link)」の形式で自動生成されます。
同じ設定(データセット、目的変数、説明変数、ファミリー、リンク関数、切片の有無)の既存モデルが存在する場合、上書きの確認ダイアログが表示されます。
診断用に生成されるデータ
モデル保存後に View Diagnostics で GLM Diagnostics タブを最初に開くと、元のデータセットに診断統計量の列を追加した派生データセットが生成されます。
| 列名 | 数式での記号 | 内容 |
|---|---|---|
fitted_values | 予測値(応答変数のスケール) | |
deviance_residuals | Deviance 残差 | |
pearson_residuals | Pearson 残差。 は prior weight で、Binary データでは | |
standardized_residuals | 標準化残差(Deviance ベース) | |
sqrt_abs_std_residuals | 標準化残差の絶対値の平方根。Scale-Location プロットの縦軸 | |
standardized_pearson_residuals | 標準化残差(Pearson ベース) | |
sqrt_abs_std_pearson_residuals | Pearson ベースの標準化残差の絶対値の平方根 | |
cooks_distance_pearson | Pearson ベースの標準化残差から計算した Cook's Distance | |
leverage | てこ比(Hat 行列の対角要素) | |
cooks_distance | Cook's Distance |
Pearson ベースの列は、残差タイプの選択 で Pearson を選んだ場合の診断プロットに対応します。
標準化残差と Cook's Distance の計算に使う はファミリーごとに異なります。Poisson、Binomial、Negative Binomial では です。これらのファミリーでは分散関数 が理論分散を規定しているため、診断統計量に過分散を吸収させません。Negative Binomial では の推定・固定によらず です。Gaussian では 、Gamma では を使います。なお、Negative Binomial の 固定時に 係数テーブル の標準誤差で使う とは異なります。
診断と詳細
モデル保存後、2つのボタンが表示されます。
- View Model Details - モデルの詳細情報を表示する Model Detail タブを開きます。Confidence Level 入力を変更すると、保存済みの係数と標準誤差から Wald 信頼区間と列ヘッダをその場で再計算します(モデルに保存された値は変わりません)。Add to Report ボタンから係数テーブルをレポートに追加できます。
- View Diagnostics - 残差診断プロットを表示する GLM Diagnostics タブを開きます
診断プロット
View Diagnostics をクリックすると、4つの診断プロットが表示されます。OLS と同様に、線形性・等分散性・外れ値の影響を確認します。
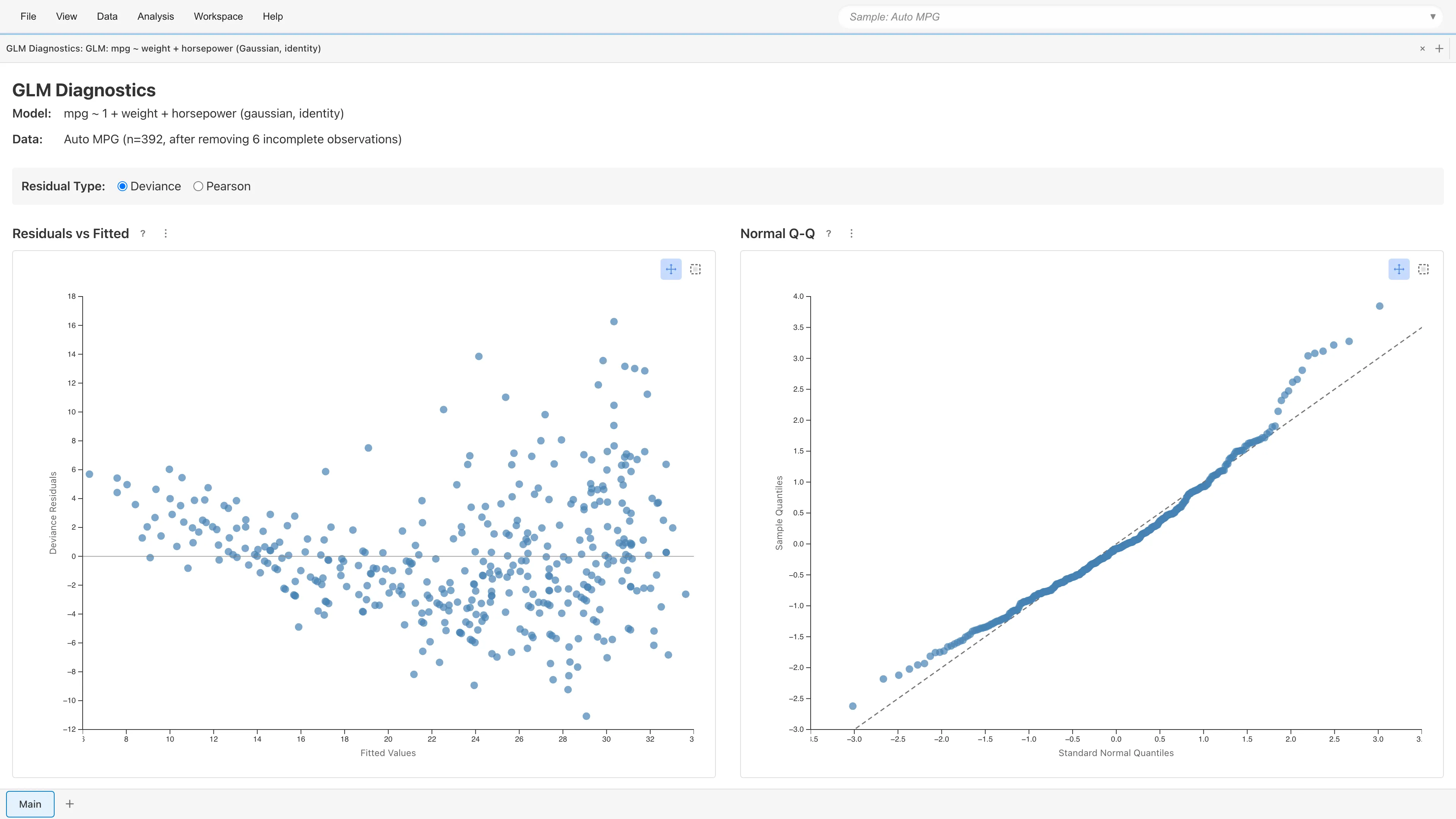
残差タイプの選択
診断プロットの残差タイプを Deviance(デフォルト)または Pearson から選択できます。切り替えると4つのプロット全てが即座に更新されます。
- Deviance Residuals: 。 は飽和モデル()の対数尤度です。尤度に基づく残差で、MIDAS のデフォルト
- Pearson Residuals: 。 は prior weight で、Binary データでは 、Grouped Binomial では は試行数です。観測値と期待値の差を分散関数で標準化した残差で、過分散の診断に有用です。Pearson 統計量 が分散パラメータ の推定に使われます
Residuals vs Fitted(残差 vs 予測値)
横軸に予測値 、縦軸に残差をプロットします。モデルが適切であれば、残差はゼロの周囲にランダムに散らばります。
- 曲線的パターン: リンク関数の選択が不適切、または説明変数の非線形効果が欠落している可能性
- 漏斗状パターン: 分散関数の選択が不適切な可能性(例: Poisson の が実データの分散と合わない)
Normal Q-Q Plot(正規 Q-Q プロット)
Gaussian ファミリーの場合のみ表示されます。 標準化残差の分位点を理論正規分位点に対してプロットし、正規性を確認します。
Gaussian 以外のファミリーでは、Deviance 残差が漸近的に正規分布に近づく保証はありません(特に Binomial の二値データでは成り立ちません)。そのため、非 Gaussian ファミリーではこのプロットの代わりに「This plot is only shown for Gaussian family GLMs.」と表示されます。
Scale-Location(尺度-位置プロット)
標準化残差を として、横軸に予測値、縦軸に をプロットします。分散が一定(等分散)であれば、点は水平方向に均等に散らばります。
右上がりの傾向がある場合、分散が予測値に依存していることを示唆します。GLM では分散関数 によって平均と分散の関係を明示的にモデル化しているため、このプロットでパターンが見られる場合は、選択したファミリーの分散関数がデータに合っていない可能性があります。
Residuals vs Leverage(残差 vs てこ比)
横軸にてこ比 (Hat 行列の対角要素)、縦軸に標準化残差をプロットします。Cook (1977) の Cook's Distance の等高線(: オレンジ破線、: 赤破線)が表示されます。
- てこ比(Leverage): 説明変数空間で観測値が他からどれだけ離れているかを示す。( は切片を含む推定パラメータ数、 は観測数)が高レバレッジの目安
- Cook's Distance: 。 は穏健な基準で注意を要し、 は強い影響を示す
等高線の外側に位置する観測値は、その1点を除外するだけでモデルの推定結果が大きく変わる可能性があります。
ポイントの選択
各プロット上でデータポイントをクリックまたは矩形選択すると、該当する観測値の詳細(予測値、残差、てこ比、Cook's Distance 等)がプロット下部のテーブルに表示されます。選択状態は4つのプロット間で同期されます。
Deviance の適合度
Poisson および Binomial ファミリーでは、Deviance/df 比(残差 Deviance を残差自由度で割った値)を表示します。この比が 1 に近ければ、データの変動がモデルの想定と整合的です。1 から大きく離れる場合は過分散(または過少分散)を疑います。
Deviance/df が 1 より大幅に大きい場合、モデルがデータの変動を十分に捉えていない可能性があります。重要な説明変数が欠けていないか、分布の仮定が適切かを検討してください。Poisson データの場合、Negative Binomial ファミリーへの切り替えが有効な場合があります。1 より大幅に小さい場合は過少分散であり、モデルの仕様誤りを疑います。理論的背景は GLM の基礎 を参照してください。
Binomial モデルで Binary データ(試行数 = 1)を扱う場合、Deviance/df 比は信頼できる適合度指標になりません。その場合は診断プロットでモデルの適合度を評価してください。
予測
保存した GLM モデルを使って、新しいデータに対する予測を実行できます。
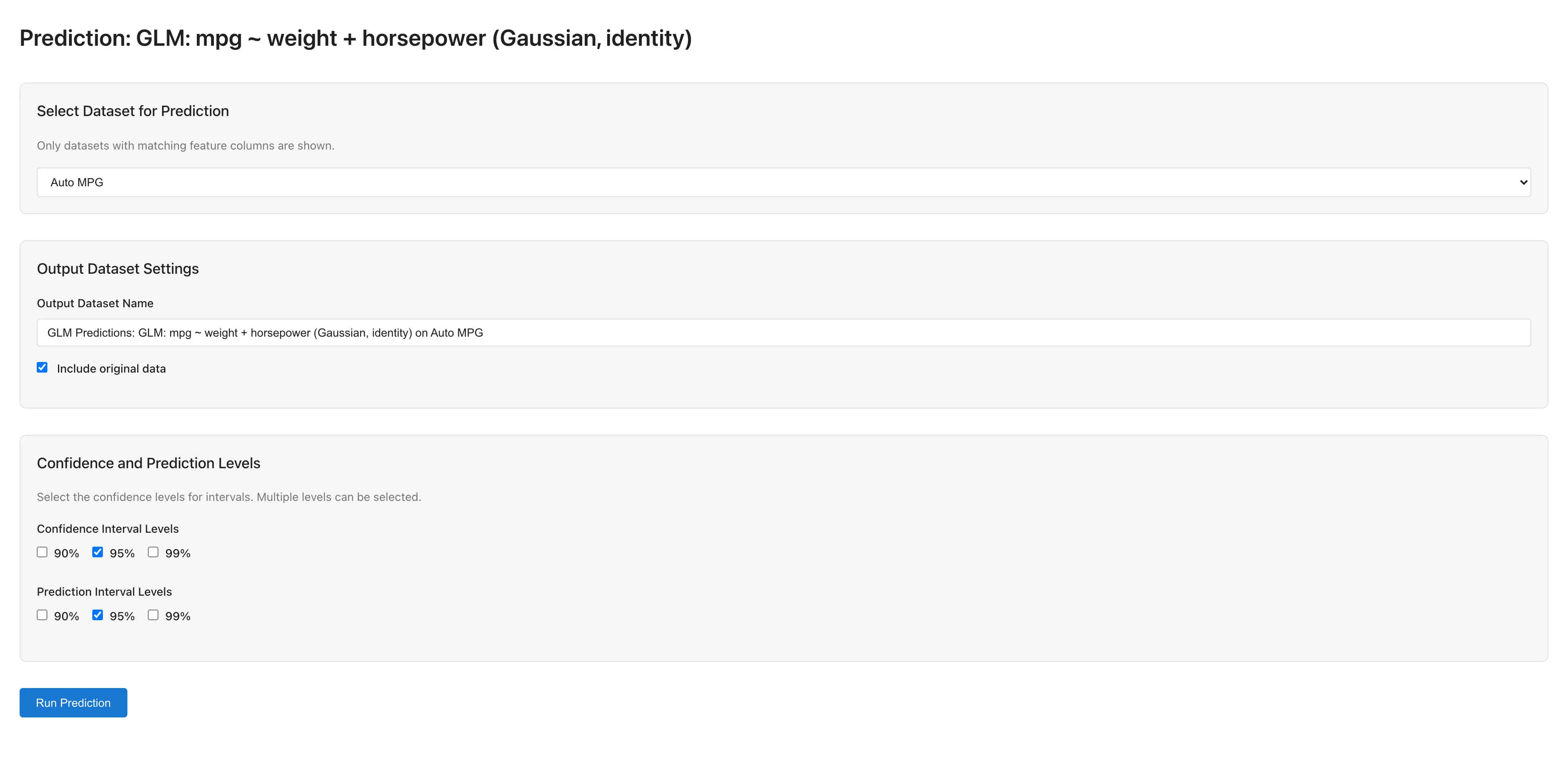
予測の実行方法
- View Model Details で Model Detail タブを開く
- Make Predictions ボタンをクリックして GLM Prediction タブを開く
- 予測に使用するデータセットを選択する(説明変数の列名が一致するデータセットのみ選択可能)
- 出力設定を行う:
- Output Dataset Name: 予測結果のデータセット名
- Include original data: 元データの列を結果に含めるかどうか
- Confidence Interval Levels: 信頼区間の水準(90%, 95%, 99%)
- Prediction Interval Levels: 予測区間の水準(90%, 95%, 99%)
- Run Prediction で予測を実行する
予測結果
予測結果はデータセットとして保存され、以下を含みます:
- 予測値 (応答変数のスケール)
- 平均応答 の信頼区間。与えられた説明変数の値における母平均の推定の不確かさを表します
- 新規観測値 の予測区間。個々の観測値のばらつきも含みます
区間の参照分布
分散パラメータ をデータから推定するファミリー(Gaussian の全リンク、Gamma、Negative Binomial の 固定時)では、信頼区間と予測区間に自由度 の 分布を使用します。 は学習データの観測数、 はインターセプトを含む推定パラメータの総数です。Gaussian + identity link では、誤差が正規分布に従うという仮定のもとで有限標本で正確な結果です。それ以外の dispersion 推定ファミリーでは、 の推定に伴う不確実性を 分布が反映します。
のファミリー(Poisson、Binomial、Negative Binomial の 推定時)では、標準正規分布()を参照分布として使用します。これは漸近近似であり、標本サイズが大きくなるほど精度が向上します。
予測区間の計算方法
予測区間の計算方法はファミリーに依存します。Gaussian + identity link では推定不確実性を含む解析的公式を使用し、それ以外ではプラグイン法を使用します。プラグイン法はパラメータ推定の不確実性を含まないため、小標本や外挿点で被覆確率が低下することがあります。各ファミリーの公式はGLM の基礎を参照してください。
予測データセットに目的変数が含まれている場合、精度指標(R², RMSE, MAE)が自動的に計算・表示されます。
注意事項
カテゴリ変数の使用
GLM では数値型の変数のみ使用できます。カテゴリ尺度(名義・順序)や日付/日時型の変数を説明変数として使用するには、Dummy Coding タブで数値のダミー変数に変換してから分析を行います。
欠損値・無効値の自動除外
欠損値(null)、非数値、無限大を含む行は分析から自動的に除外されます。除外された行数は、View Diagnostics で開く GLM Diagnostics タブの Data 欄に「after removing N incomplete observations」の形式で表示されます。この除外はリストワイズ除去に該当します。妥当な推定を与える条件については 欠損データのメカニズム を参照してください。
収束の問題
IRLS が収束しない場合や、結果にエラーや数値的な警告が表示される場合は以下を確認してください:
- 反復回数: Max Iterations を増やす(例: 100 → 500)
- 許容誤差: Convergence Tolerance を緩める(例: 1e-6 → 1e-4)
- スケーリング: 説明変数の桁が大きく異なる場合、数値的不安定性の原因になります。標準化を検討してください
- 条件数の警告: 推定された条件数が を超えると、計画行列が悪条件であることを示す警告を結果に表示します。説明変数間の強い相関や、説明変数間のスケールの大きな違いが主な原因です。意味と対処は 条件数 を参照してください
- 適合値の範囲外: Poisson や Gamma に identity のような link を使うと、適合した平均が有効範囲外になることがあります。MIDAS はこの値を範囲内に押し込めず、適合を中止してエラーを表示します。押し込めると deviance、AIC、残差、標準誤差、信頼区間が係数とは別の適合を表すことになるためです。適合した平均が範囲内に収まる link(log など)を検討してください
- 完全分離: ロジスティック回帰で応答変数を完全に分離できる説明変数が存在する場合、最尤推定値が有限値に収束しません(Albert & Anderson, 1984)。MIDAS は分離を検出すると警告を表示します。該当する変数の除外やデータの確認が必要です
- ゼロ過剰: カウントデータにゼロが極端に多い場合、Poisson や Negative Binomial では適合が困難な場合があります
参考文献
- Nelder, J. A., & Wedderburn, R. W. M. (1972). Generalized linear models. Journal of the Royal Statistical Society: Series A, 135(3), 370-384. https://www.jstor.org/stable/2344614
- Cook, R. D. (1977). Detection of influential observation in linear regression. Technometrics, 19(1), 15-18. https://www.jstor.org/stable/1268249
- Albert, A., & Anderson, J. A. (1984). On the existence of maximum likelihood estimates in logistic regression models. Biometrika, 71(1), 1-10. https://www.jstor.org/stable/2336390
このページの Markdown 版もあります。