Generalized Linear Model (GLM)
The GLM tab performs regression analysis using generalized linear models. A GLM is defined by a distribution family, a linear predictor , and a link function , extending OLS to the exponential family of distributions. The offset term defaults to zero when not specified. See GLM Fundamentals for the mathematical background.
OLS regression in the Linear Regression tab is a special case of GLM (Gaussian family with identity link). See Linear Regression for details on OLS.
Distribution Families and Link Functions
The distribution families and link functions available in MIDAS are listed below.
Choosing a Distribution Family
| Family | UI Label | Variance Function | Use Case |
|---|---|---|---|
| Gaussian | Gaussian (Normal) | Continuous response variable. Equivalent to standard linear regression | |
| Binomial | Binomial (Logistic) | Binary data (0/1) or proportion data. Logistic regression | |
| Poisson | Poisson (Count) | Count data (event occurrences). Assumes variance equals the mean | |
| Gamma | Gamma (Positive Continuous) | Positive continuous values with right-skewed distributions (wait times, costs) | |
| Negative Binomial | Negative Binomial (Overdispersed Count) | Overdispersed count data. Use when the Poisson equidispersion assumption does not hold |
The choice of family is driven by the nature of the response variable. Binary outcomes call for Binomial, non-negative integers for Poisson (or Negative Binomial if overdispersed), and positive continuous values with a roughly constant coefficient of variation (variance proportional to the square of the mean) for Gamma.
The Binomial family supports both individual 0/1 data (Binary) and aggregated successes/trials data (Grouped). See Grouped Binomial GLM with Dose-Response Data for details.
Link Functions
The link function is a monotonic function connecting the linear predictor to the expected value of the response. Except for Negative Binomial, each family's default link is its canonical link. The canonical link for Negative Binomial is , but when is estimated the link function changes at each iteration, making estimation unstable. Log is used as the default in practice.
| Family | Default Link | Available Links |
|---|---|---|
| Gaussian | Identity | Identity, Log |
| Binomial | Logit | Logit, Probit |
| Poisson | Log | Log, Identity |
| Gamma | Inverse | Inverse, Log, Identity |
| Negative Binomial | Log | Log |
| Link Function | Formula | Description |
|---|---|---|
| Identity | No transformation. Canonical link for Gaussian | |
| Logit | Log-odds transformation. Canonical link for Binomial | |
| Log | Log transformation. Canonical link for Poisson. Ensures | |
| Inverse | Reciprocal transformation. Canonical link for Gamma | |
| Probit | Inverse CDF of the standard normal distribution. Corresponds to a latent normal variable model |
The canonical link provides stable maximum likelihood estimation. Non-canonical links may be chosen for easier coefficient interpretation but can lead to convergence issues. See GLM Fundamentals for the mathematical properties of canonical links.
Basic Usage
The examples below use the Auto MPG dataset.
Opening GLM
Select Analysis > Generalized Linear Model (GLM)... from the menu bar.
Setting Up Variables
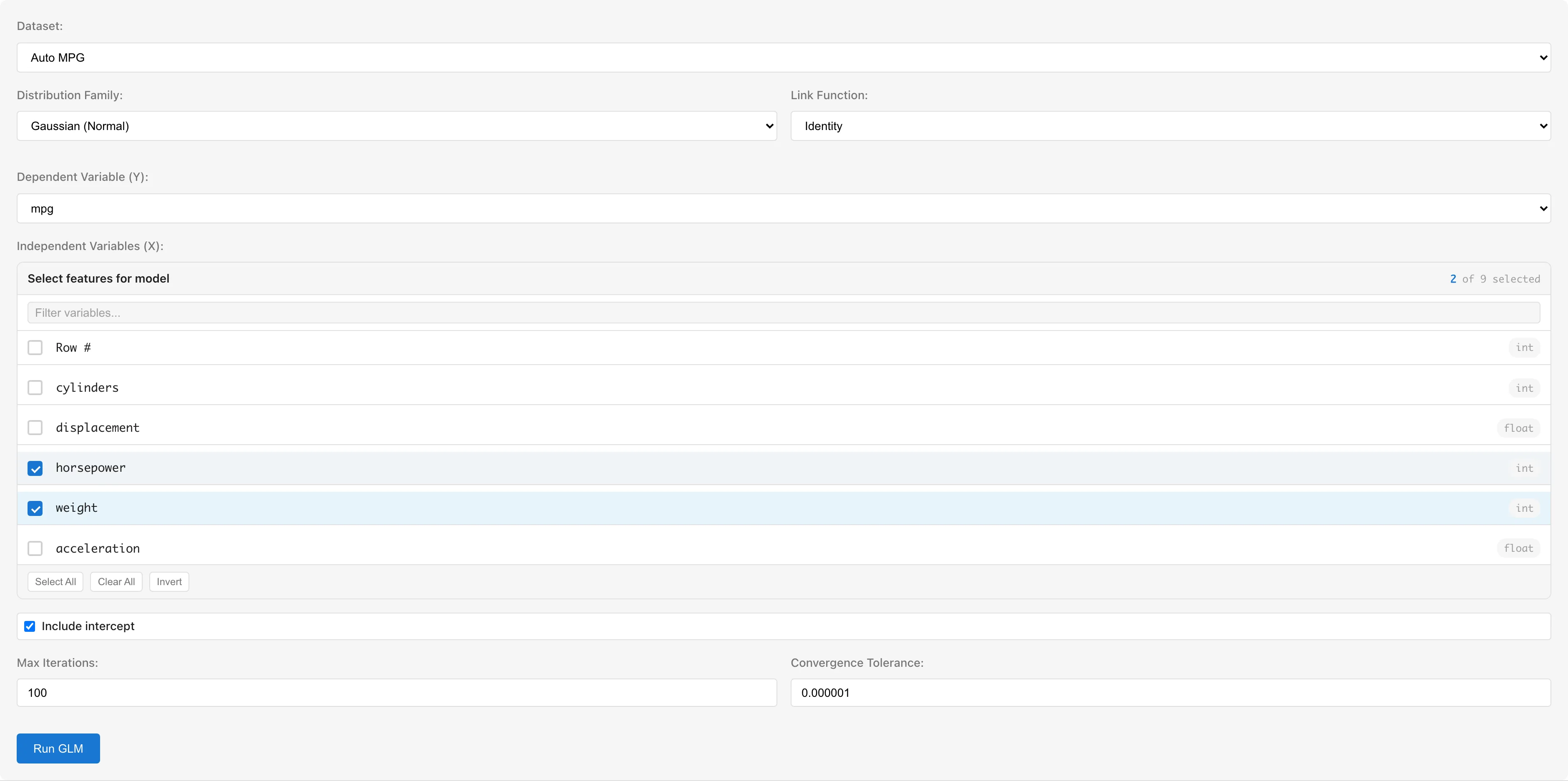
Dataset selects the dataset to analyze.
Response Variable (Y) selects the response variable. Numeric columns (int64, float64) and boolean columns are available. Boolean values are automatically converted to true=1, false=0. For the Binomial family, use a 0/1 or boolean column.
Predictor Variables (X) selects predictor variables using checkboxes. Columns with categorical scales (nominal/ordinal) or date/datetime types are not selectable. To use categorical variables, convert them to numeric dummy variables using the Dummy Coding tab first (see Notes).
Distribution Family selects the distribution family. Changing the family automatically switches the link function to the canonical link for that family.
Link Function selects the link function. Available options depend on the selected family.
Include intercept toggles the intercept term. Enabled by default.
Negative Binomial Settings
When the Negative Binomial family is selected, options for the shape parameter appear. The Negative Binomial variance is (the NB2 parameterization), where controls the degree of overdispersion.
- Automatic (default): is estimated using profile likelihood. An outer loop optimizes while an inner IRLS loop estimates
- Manual: Check Manually specify θ and enter a value (0.1 to 100, default 1.0). Useful for sensitivity analysis or model comparison
Interpreting :
- : Converges to Poisson ()
- : Moderate overdispersion
- : Strong overdispersion
- : Extreme overdispersion
Offset Variable
Offset Variable adds a known quantity to the linear predictor with a fixed coefficient of 1. The offset is not estimated from data; it is a fixed value for each observation.
A typical use case is rate modeling in Poisson regression. Set the count as the response variable and as the offset to model rates instead of counts:
This parameterization means that is interpretable as a rate ratio.
Setting an offset also affects the null deviance. The null model becomes intercept + offset, so the null deviance differs from the case without an offset.
When predicting with a saved model that includes an offset, the prediction dataset must contain an offset column with the same name. The linear predictor for prediction is .
Advanced Options
- Max Iterations: Maximum number of IRLS iterations (default: 100)
- Convergence Tolerance: Convergence threshold based on maximum absolute change in coefficients (default: 1e-6)
Running the Analysis
Click the Run GLM button.
Parameter estimation uses IRLS (Iteratively Reweighted Least Squares; see algorithm details). The progress dialog shows the deviance at each iteration. Click Cancel to stop the analysis, and use Save as Dataset to save the convergence history.
Understanding Results
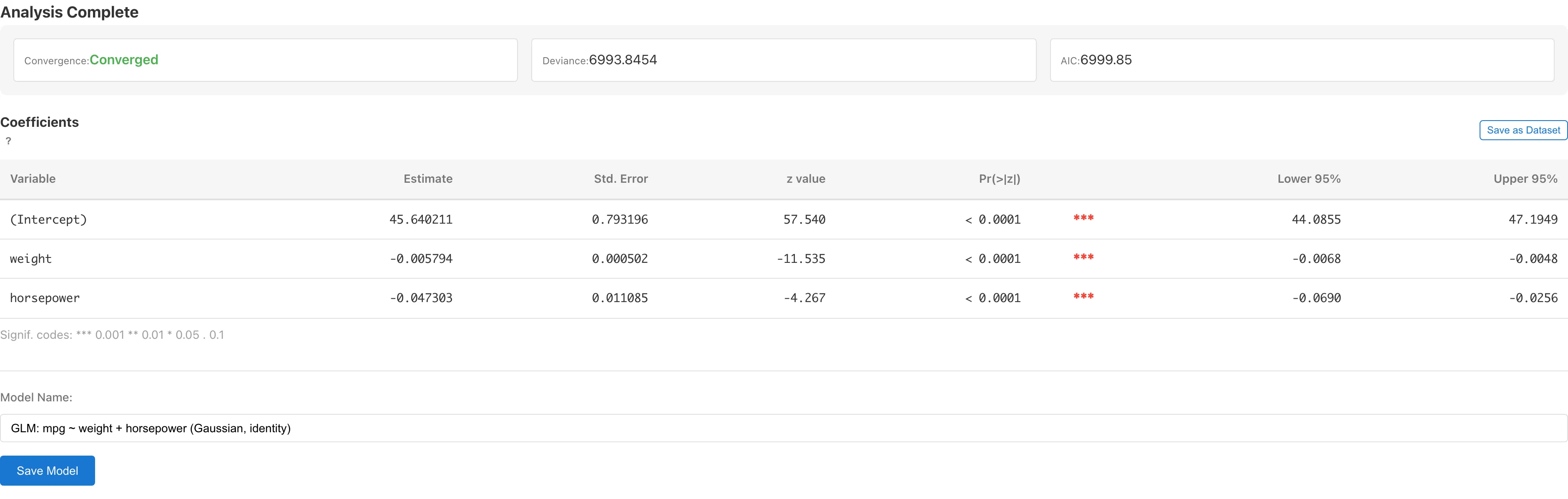
Model Summary
| Metric | Description |
|---|---|
| Convergence | Whether IRLS converged (with iteration count) |
| Deviance | Residual deviance . A goodness-of-fit measure based on the log-likelihood difference from the saturated model |
| AIC | Akaike Information Criterion , where is the total number of estimated parameters. Used for comparing models within the same family. Comparing AIC across different families is not recommended because the constant terms in the log-likelihood differ. Lower values indicate better fit-complexity trade-off |
| Shape Parameter () | Negative Binomial only. controls the degree of overdispersion: smaller values indicate stronger overdispersion, while converges to Poisson (see Negative Binomial Settings). Indicates whether was estimated or manually specified |
in the AIC formula is the total number of estimated parameters. For Poisson and Binomial, is the number of regression coefficients (including the intercept); for Gaussian and Gamma, it is the number of regression coefficients plus the dispersion parameter (Gaussian: , Gamma: ). For Negative Binomial, is included in only when it is automatically estimated. A manually specified is not an estimated parameter and is not counted. Be aware of this difference when comparing AIC between -estimated and -fixed models.
Coefficients
| Column | Description |
|---|---|
| Variable | Variable name (intercept shown as "(Intercept)") |
| Estimate | Estimated regression coefficient (on link function scale) |
| Std. Error | Wald standard error . is the dispersion parameter ( for Poisson, Binomial, and Negative Binomial with estimated ) |
| Lower N% / Upper N% | Confidence interval , where N is the selected confidence level. is for dispersion-estimating families, or for others (e.g., at the 95% level) |
| OR / IRR / exp(Est.) | . Displayed as odds ratio (OR) for logit link, incidence rate ratio (IRR) for Poisson and Negative Binomial with log link, or multiplicative effect exp(Est.) for Gamma and Gaussian with log link. Not shown for identity, inverse, or probit links |
| exp(Lower N%) / exp(Upper N%) | and . The link-scale confidence interval transformed to the response scale. Shown under the same conditions as the OR / IRR column |
For Negative Binomial with estimated , because the overdispersion is already modeled by the term in the variance function — there is no remaining overdispersion for to absorb, so standard errors are computed with . When is manually fixed, the specified value may not fully capture the data's overdispersion, so is estimated instead.
Interpreting Coefficients
Coefficients are estimated on the link function scale, so interpretation requires considering the inverse link function.
- Identity link: is the change in per unit change in (same as OLS)
- Logit link: is the change in log-odds. is the odds ratio
- Log link: is the change in . is the multiplicative change in
- Inverse / Probit link: Direct interpretation is difficult; interpretation through predicted values is more practical
The coefficients table can be saved as a dataset using the Save as Dataset button for export to CSV. You must save the model first (using the Save Model button). Linking the coefficient dataset to a specific model means that deleting the model also deletes the derived coefficient dataset and any report element that references it, and refitting the model updates the dataset contents to reflect the new fit.
The saved dataset contains Variable, Estimate, Std. Error, Lower N%, and Upper N%. For logit and log links, the exp-transformed columns are also included: OR / IRR / exp(Est.), exp(Lower N%), and exp(Upper N%).
Saving and Diagnostics
Saving the Model
Enter a model name in the Model Name field and click Save Model. The model name defaults to the format "GLM: Y ~ X1 + X2 (Family, link)".
If an existing model with the same configuration (dataset, response variable, predictor variables, family, link function, intercept inclusion) exists, a confirmation dialog for overwriting is displayed.
Data Generated for Diagnostics
After saving the model, opening the GLM Diagnostics tab for the first time via View Diagnostics creates a derived dataset that adds diagnostic columns to the original data.
| Column | Symbol | Description |
|---|---|---|
fitted_values | Predicted values (on the response scale) | |
deviance_residuals | Deviance residuals | |
pearson_residuals | Pearson residuals. is the prior weight ( for binary data) | |
standardized_residuals | Standardized residuals (deviance-based) | |
sqrt_abs_std_residuals | Square root of the absolute standardized residuals. The vertical axis of the Scale-Location plot | |
standardized_pearson_residuals | Standardized residuals (Pearson-based) | |
sqrt_abs_std_pearson_residuals | Square root of the absolute Pearson-based standardized residuals | |
cooks_distance_pearson | Cook's Distance computed from Pearson-based standardized residuals | |
leverage | Leverage (diagonal of the hat matrix) | |
cooks_distance | Cook's Distance |
The Pearson-based columns correspond to the diagnostic plots when Pearson is selected as the residual type.
The used for computing standardized residuals and Cook's Distance differs by family. For Poisson, Binomial, and Negative Binomial, : the variance function specifies the theoretical variance, so overdispersion is not absorbed into the diagnostic statistics. For Negative Binomial, regardless of whether is estimated or fixed. For Gaussian, ; for Gamma, . Note that for Negative Binomial with fixed , this differs from the used for standard errors in the coefficients table.
Diagnostics and Details
After saving the model, two buttons appear:
- View Model Details - Opens the Model Detail tab showing detailed model information. Changing the Confidence Level input recomputes the Wald confidence intervals and column headers in place from the saved coefficients and standard errors (the saved value is not modified). Use the Add to Report button to add the coefficients table to a report.
- View Diagnostics - Opens the GLM Diagnostics tab showing diagnostic plots
Diagnostic Plots
Clicking View Diagnostics displays four diagnostic plots. As with OLS, check linearity, constant variance, and outlier influence.
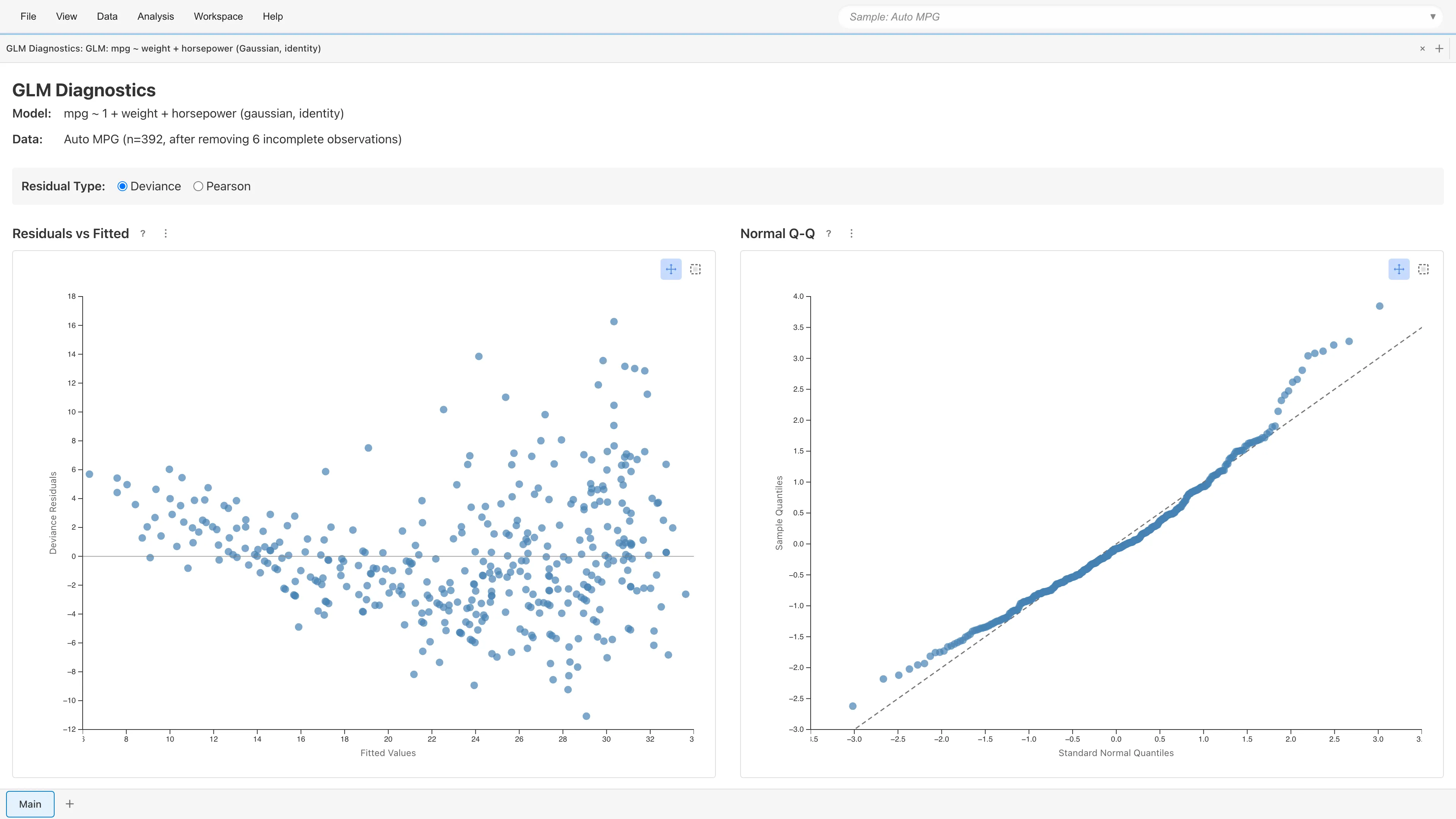
Residual Type Selection
Select the residual type: Deviance (default) or Pearson. Switching updates all four plots immediately.
- Deviance Residuals: , where is the log-likelihood under the saturated model (). Likelihood-based residuals and the default in MIDAS
- Pearson Residuals: . is the prior weight ( for binary data; is the number of trials for grouped Binomial). Observed-minus-expected scaled by the variance function. Useful for diagnosing overdispersion, as Pearson is used to estimate the dispersion parameter
Residuals vs Fitted
Plots residuals against fitted values . Random scatter around zero indicates adequate model fit.
- Curved pattern: The link function may be inappropriate, or nonlinear effects of predictors may be missing
- Funnel-shaped pattern: The variance function may be inappropriate (e.g., Poisson's does not match the data)
Normal Q-Q Plot
Shown only for Gaussian family. Plots standardized residual quantiles against theoretical normal quantiles.
For non-Gaussian families, deviance residuals are not guaranteed to be asymptotically normal (particularly for binary Binomial data). Instead of the plot, the message "This plot is only shown for Gaussian family GLMs." is displayed.
Scale-Location
Plots against fitted values. Constant variance is indicated by points spreading evenly in the horizontal direction.
An upward trend suggests variance depends on fitted values. Since GLM explicitly models the mean-variance relationship through the variance function , patterns in this plot suggest the chosen family's variance function does not match the data well.
Residuals vs Leverage
Plots standardized residuals against leverage (diagonal elements of the hat matrix). Cook's (1977) distance contours are displayed at (orange dashed) and (red dashed).
- Leverage: Measures how far an observation's predictor values are from others. ( = number of parameters including the intercept, = number of observations) indicates high leverage
- Cook's Distance: . warrants attention; indicates strong influence
Observations outside the contour lines may substantially change the model estimates if removed.
Point Selection
Click or rectangle-select data points on any plot to display details (fitted values, residuals, leverage, Cook's Distance, etc.) in a table below the plots. Selection state is synchronized across all four plots.
Deviance Goodness-of-Fit
For Poisson and Binomial families, MIDAS displays the Deviance/df ratio (residual deviance divided by residual degrees of freedom). A ratio near 1 indicates that the observed variability is consistent with what the model expects. A ratio far from 1 suggests overdispersion (or underdispersion).
A Deviance/df ratio much greater than 1 suggests the model does not adequately capture the variability in the data. Consider whether important predictors are missing or whether the distributional assumption is appropriate. For Poisson data, switching to the Negative Binomial family may help. A ratio much less than 1 suggests underdispersion, which may indicate model misspecification. See GLM Fundamentals for the theoretical background.
For Binomial models with binary response data (trial size = 1), the Deviance/df ratio is not a reliable indicator of model fit. Use the diagnostic plots to assess the model in that case.
Prediction
Use a saved GLM model to generate predictions on new data.
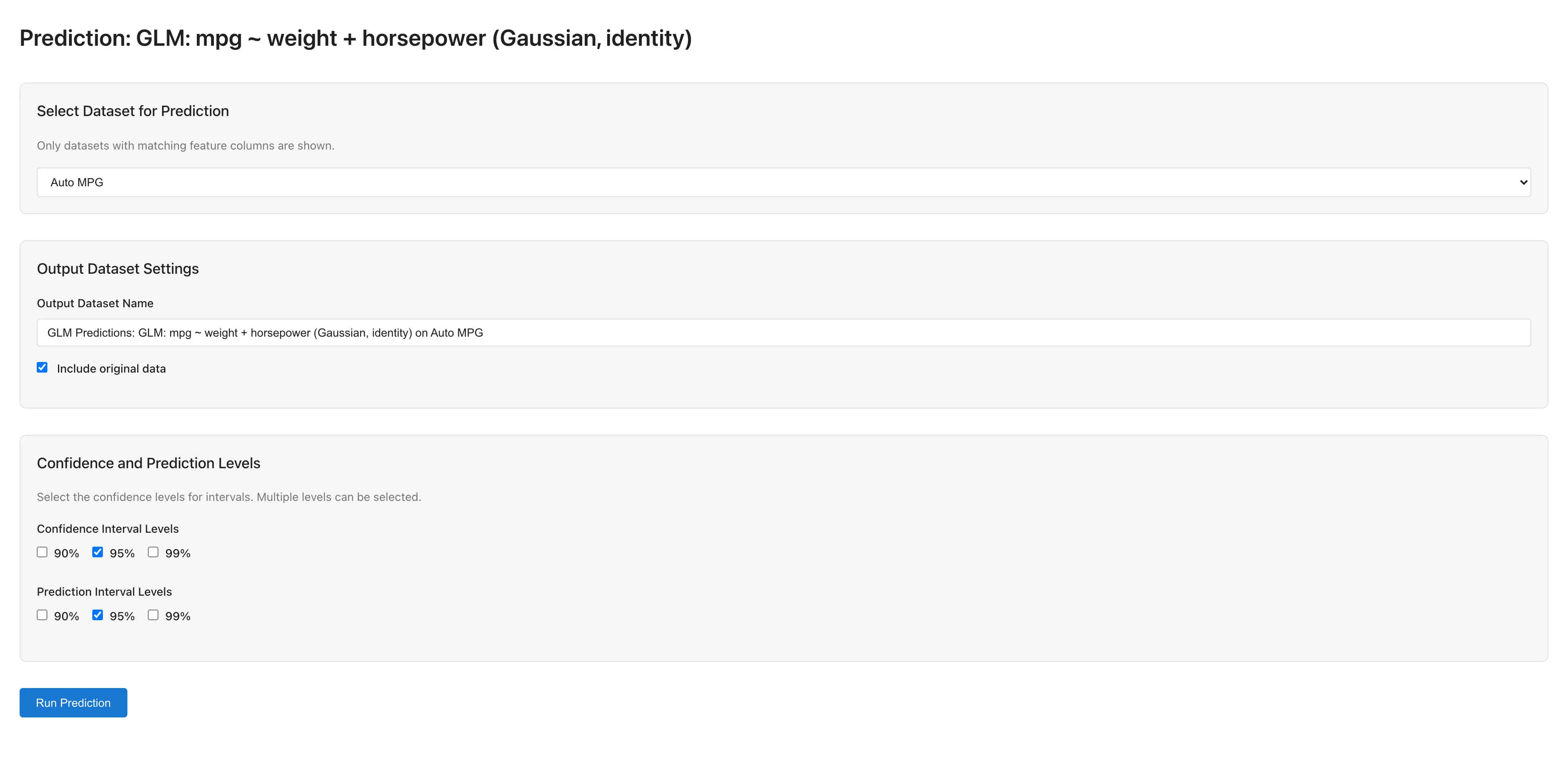
Running Predictions
- Open the Model Detail tab via View Model Details
- Click the Make Predictions button to open the GLM Prediction tab
- Select a dataset for prediction (only datasets with matching predictor column names are available)
- Configure output settings:
- Output Dataset Name: Name for the prediction results dataset
- Include original data: Whether to include original columns in the output
- Confidence Interval Levels: Confidence interval levels (90%, 95%, 99%)
- Prediction Interval Levels: Prediction interval levels (90%, 95%, 99%)
- Click Run Prediction to execute
Prediction Output
Prediction results are saved as a dataset containing:
- Predicted values (on the response scale)
- Confidence intervals for the mean response , which capture the uncertainty in estimating the population mean at a given set of predictor values
- Prediction intervals for a new observation , which capture the uncertainty in a single future value including observation-level variability
Reference Distribution for Intervals
For families that estimate the dispersion parameter from data (Gaussian with any link, Gamma, Negative Binomial with fixed ), confidence and prediction intervals use the distribution with degrees of freedom, where is the number of training observations and is the total number of estimated parameters including the intercept. For Gaussian with identity link, this is the exact finite-sample result under the assumption that the errors are normally distributed. For other dispersion-estimating families, the -distribution accounts for the additional uncertainty from estimating .
For families with known dispersion (: Poisson, Binomial, Negative Binomial with estimated ), intervals use the standard normal () distribution as the reference. This is an asymptotic approximation that becomes more accurate as the sample size increases.
Prediction Interval Methods
Prediction interval computation depends on the family. Gaussian with identity link uses an analytical formula that includes estimation uncertainty, while other combinations use plug-in methods. Plug-in methods do not account for parameter estimation uncertainty, so coverage probability may fall below the stated confidence level in small samples or for extrapolation points. See GLM Fundamentals for the formulas.
When the prediction dataset contains the response variable, accuracy metrics (R², RMSE, MAE) are automatically calculated and displayed.
Notes
Using Categorical Variables
GLM only accepts numeric variables. To use categorical (nominal/ordinal) or date/datetime variables as predictors, convert them to numeric dummy variables using the Dummy Coding tab before running the analysis.
Automatic Exclusion of Missing and Invalid Values
Rows containing missing values (null), non-numeric values, or infinity are automatically excluded from the analysis. The number of excluded rows is displayed in the Data field of the GLM Diagnostics tab, opened via View Diagnostics, in the form "after removing N incomplete observations". This is listwise deletion. See Missing Data Mechanisms for conditions under which it yields valid estimates.
Convergence Issues
If IRLS fails to converge or the results include an error or a numerical warning, check the following:
- Iteration count: Increase Max Iterations (e.g., 100 → 500)
- Tolerance: Relax Convergence Tolerance (e.g., 1e-6 → 1e-4)
- Scaling: Large differences in predictor scales can cause numerical instability. Consider standardizing
- Condition number warning: When the estimated condition number exceeds , MIDAS displays a warning that the design matrix is ill-conditioned. Strong correlation among predictors or large differences in their scales are common causes. See Condition Number for what it means and how to address it
- Out-of-range fitted means: With a link such as identity for Poisson or Gamma, the fitted mean can fall outside the valid range. Rather than clamp the mean into range, MIDAS stops the fit and reports an error, because clamping would make the deviance, AIC, residuals, standard errors, and confidence intervals describe a different fit from the coefficients. Choose a link that keeps the fitted mean in range, such as log
- Perfect separation: In logistic regression, when a predictor perfectly separates the response classes, the maximum likelihood estimate does not converge to a finite value (Albert & Anderson, 1984). MIDAS displays a warning when it detects separation. Remove the offending predictor or verify the data
- Excess zeros: When count data contains an extreme number of zeros, Poisson or Negative Binomial models may struggle to fit adequately
References
- Nelder, J. A., & Wedderburn, R. W. M. (1972). Generalized linear models. Journal of the Royal Statistical Society: Series A, 135(3), 370-384. https://www.jstor.org/stable/2344614
- Cook, R. D. (1977). Detection of influential observation in linear regression. Technometrics, 19(1), 15-18. https://www.jstor.org/stable/1268249
- Albert, A., & Anderson, J. A. (1984). On the existence of maximum likelihood estimates in logistic regression models. Biometrika, 71(1), 1-10. https://www.jstor.org/stable/2336390
Also available as a Markdown file.