Linear Regression
The Linear Regression tab performs ordinary least squares (OLS) linear regression analysis. OLS finds the coefficient vector that minimizes the residual sum of squares. See Regression Analysis Fundamentals for the mathematical background.
For count data, binary outcomes, or other non-normal response variables, use Generalized Linear Model (GLM) instead.
Basic Usage
Opening Linear Regression
Select Analysis > Linear Regression (OLS)... from the menu bar to open a new Linear Regression tab.
Setting Up Variables
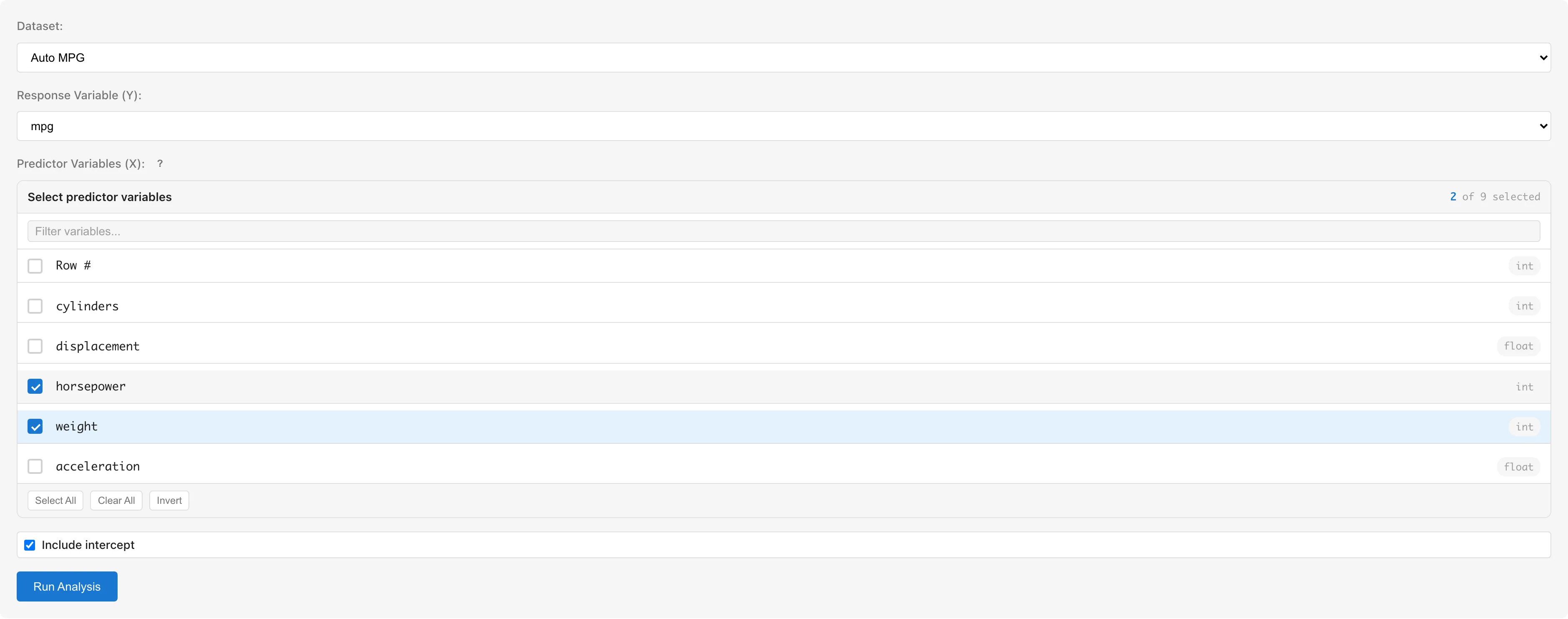
Dataset selects the dataset to analyze.
Response Variable (Y) selects the response variable. Numeric (int64, float64) and boolean columns are available. Boolean values are treated as 0/1. Date and datetime columns, and columns whose scale is set to nominal or ordinal, cannot be selected.
Predictor Variables (X) selects predictor variables using checkboxes. The same columns as for the response variable are selectable; columns with nominal or ordinal scale and date/datetime columns are grayed out. To use string or other categorical variables, convert them to numeric dummy variables using the Dummy Coding tab first (see Notes).
Include intercept toggles the intercept term. Enabled by default.
Confidence Level sets the confidence level used for the interval estimates in the coefficients table and the Prediction & Confidence Intervals table. The default is 95; values from 50 to 99.99 are accepted.
Click the Run Analysis button to run the analysis.
Understanding Results
Model Summary
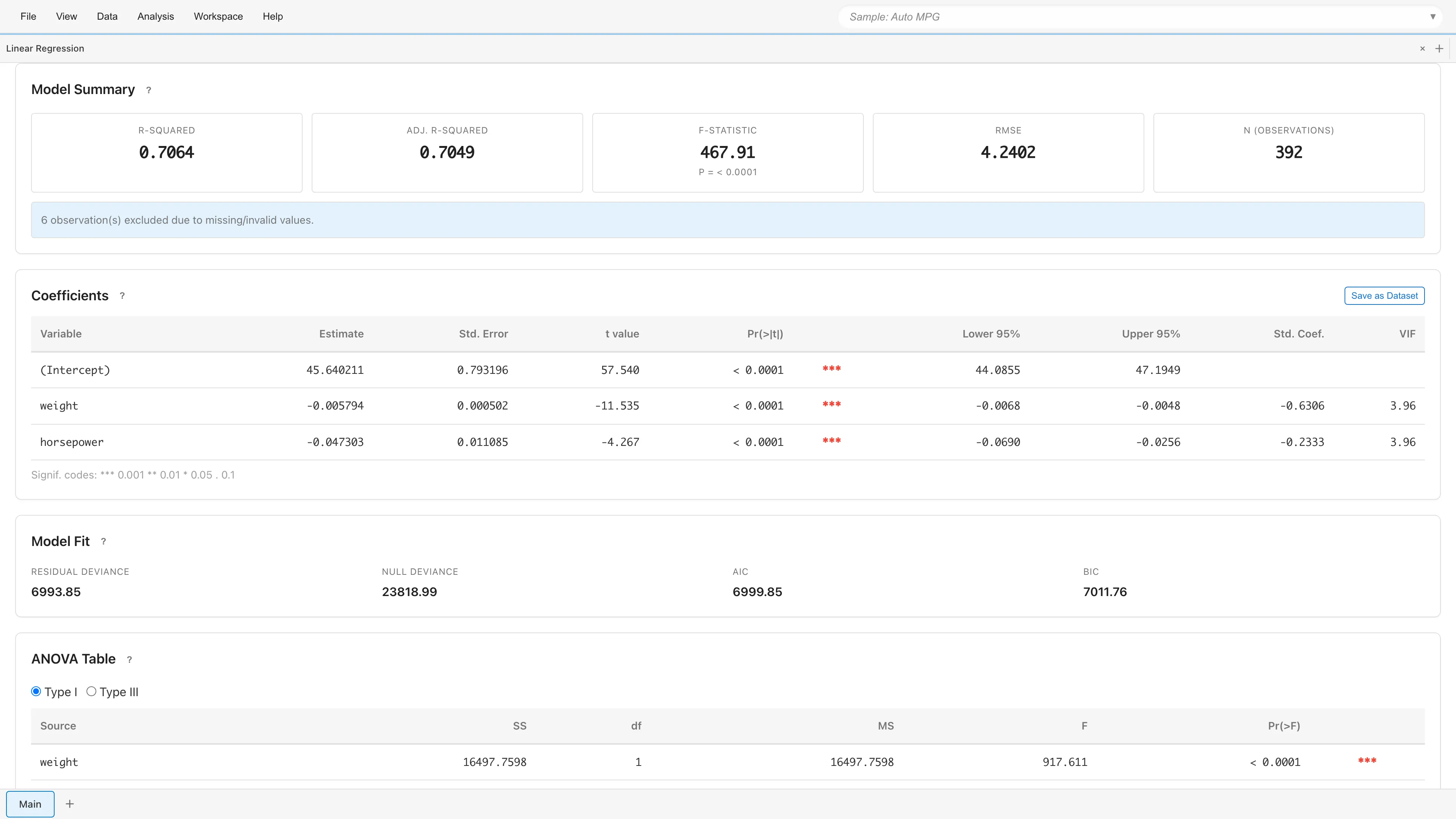
Displays overall model fit statistics.
| Metric | Description |
|---|---|
| R-squared | Proportion of variance explained by the model (0 to 1) |
| Adj. R-squared | R-squared adjusted for the number of predictors |
| RMSE | Standard deviation of residuals (measure of prediction error) |
| N (observations) | Number of observations used in the analysis |
If rows containing missing or invalid values were excluded, the number of excluded rows is displayed.
Coefficients
Displays regression coefficients for each variable.
| Column | Description |
|---|---|
| Variable | Variable name (intercept shown as "(Intercept)") |
| Estimate | Estimated coefficient |
| Std. Error | Standard error |
| Lower N% / Upper N% | Confidence interval , where N is the selected confidence level (any value from 50 to 99.99) |
| Std. Coef. | Standardized coefficient for comparing effect sizes across variables (shown as "-" for the intercept) |
| VIF | Variance Inflation Factor (see Multicollinearity) |
If the errors are normally distributed, the -distribution-based confidence intervals have exact coverage regardless of sample size.
The coefficients table can be saved as a dataset using the Save as Dataset button for export to CSV. You must save the model first (using the Save Model button). Linking the coefficient dataset to a specific model means that deleting the model also deletes the derived coefficient dataset and any report element that references it, and refitting the model updates the dataset contents to reflect the new fit.
The saved dataset contains Variable, Estimate, Std. Error, Lower N%, Upper N%, Std. Coef., and VIF.
Interpreting Coefficients
Coefficients are directly interpretable on the response scale.
- Continuous predictor: Holding other variables constant, a one-unit increase in changes by
- Dummy variable: Represents the difference in relative to the reference category
- Intercept: when all predictors are zero
- Standardized coefficient (Std. Coef.): Expressed in standard deviation units, enabling direct comparison of effect sizes across variables with different scales
Model Fit
| Metric | Description |
|---|---|
| Residual Deviance | Residual sum of squares |
| Null Deviance | Total sum of squares |
| AIC | Akaike Information Criterion , where is the total number of estimated parameters ( regression coefficients plus , i.e. ). Lower is better |
| BIC | Bayesian Information Criterion . Penalizes complexity more strongly than AIC. BIC is consistent for model selection: when the true model is among the candidates, the probability of selecting it converges to 1 as the sample size increases |
ANOVA Table
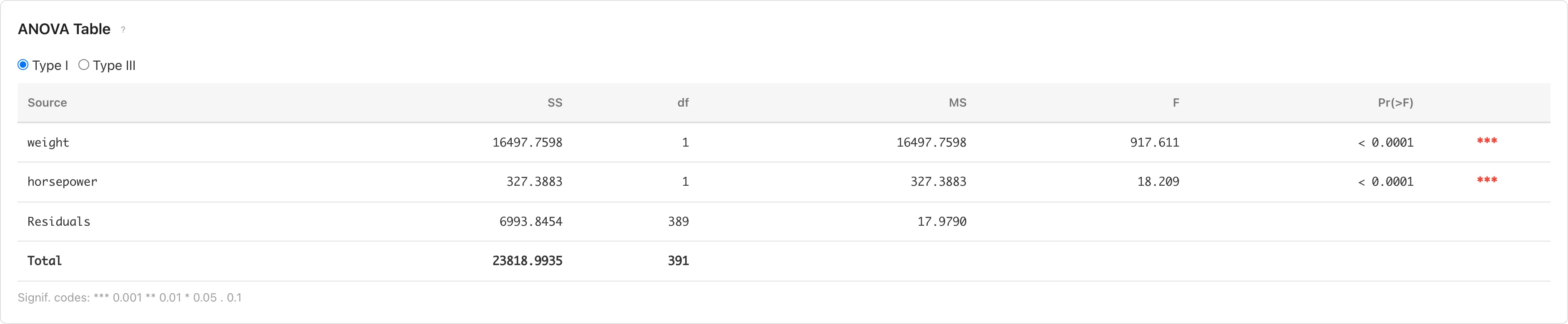
Evaluates each predictor's contribution through analysis of variance. Switch between Type I and Type III using radio buttons.
- Type I (Sequential): Computes sum of squares in the order variables were entered. Results depend on variable entry order.
- Type III (Partial): Computes sum of squares as if each variable were entered last. Results are independent of variable entry order.
| Column | Description |
|---|---|
| Source | Source of variation |
| Sum Sq | Sum of squares |
| DF | Degrees of freedom |
| Mean Sq | Mean square (Sum Sq / DF) |
| partial η² | Partial eta-squared (SS_effect / (SS_effect + SS_residual)). Shown for Type III only |
| partial ω² | Partial omega-squared, a bias-adjusted effect size estimator. Displayed as 0 when the estimate is negative. Shown for Type III only |
Prediction & Confidence Intervals
Displays predicted values and interval estimates for each observation.
| Column | Description |
|---|---|
| Fitted | Predicted value |
| CI Lower N% / CI Upper N% | Confidence interval for the mean response |
| PI Lower N% / PI Upper N% | Prediction interval for individual observations |
The confidence interval (CI) represents the precision of the estimated mean, while the prediction interval (PI) represents the range for a new individual observation. PI is always wider than CI. N is the selected confidence level (any value from 50 to 99.99).
When exceeding 100 rows, only the first 50 rows are displayed. Click Show all N rows to display all rows.
The prediction intervals table can also be saved as a dataset using the Save as Dataset button. As with the coefficients table, you must save the model first (using the Save Model button).
Saving and Diagnostics

Save analysis results to the project and view diagnostic plots.
Saving the Model
Enter a model name in the Model Name field and click Save Model. The model name defaults to the format "Linear Regression: Y ~ X1 + X2".
If an existing model with the same configuration (dataset, response variable, predictor variables, and intercept setting) exists, a confirmation dialog for overwriting is displayed.
Data Generated for Diagnostics
After saving the model, opening the Residual Diagnostics tab for the first time via View Diagnostics creates a derived dataset that adds diagnostic columns to the original data.
| Column | Symbol | Description |
|---|---|---|
fitted_values | Predicted values | |
deviance_residuals | Residuals | |
standardized_residuals | Standardized residuals | |
sqrt_abs_std_residuals | Square root of the absolute standardized residuals (used in the Scale-Location plot) | |
leverage | Leverage (diagonal of the hat matrix) | |
cooks_distance | Cook's Distance |
Diagnostics and Details
After saving the model, two buttons appear:
- View Model Details - Opens the Model Detail tab showing detailed model information. Changing the Confidence Level input recomputes the Wald confidence intervals and column headers in place from the saved coefficients and standard errors (the saved value is not modified). Use the Add to Report button to add the coefficients table to a report.
- View Diagnostics - Opens the Residual Diagnostics tab showing residual diagnostic plots
Residual Diagnostics
View Diagnostics opens four diagnostic plots for assessing the OLS assumptions:
OLS assumptions:
- Linearity - A linear relationship exists between the response and predictor variables
- Normality - Residuals follow a normal distribution
- Homoscedasticity - The variance of residuals is constant and does not depend on fitted values
- Independence - Residuals are independent of each other (not directly verifiable through diagnostic plots). For hierarchical or clustered data, consider using GLMM with random effects. For time series data with autocorrelation, consider using ARIMA (available in the Analysis menu)
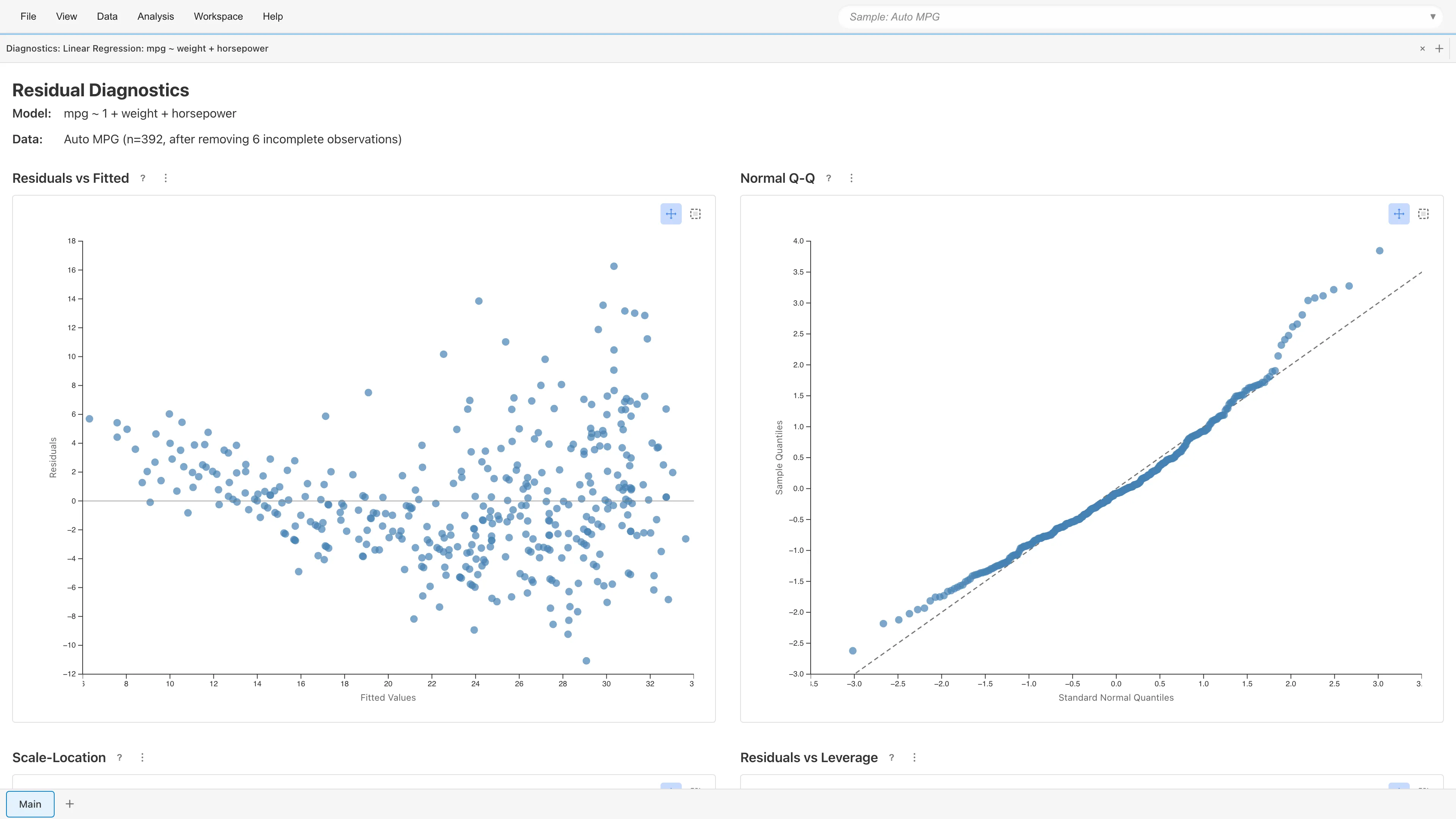
The diagnostic plots use standardized residuals (internally studentized residuals) . See Regression Analysis Fundamentals for the formulas.
Residuals vs Fitted
Plots residuals against fitted values . With a well-specified model, residuals scatter randomly around zero.
- Curved pattern: Nonlinear effects of predictors may be missing
- Funnel-shaped pattern: Possible heteroscedasticity (check Scale-Location plot for details)
Normal Q-Q Plot
Plots standardized residual quantiles against theoretical normal quantiles. Points fall along the diagonal when residuals are normally distributed. Deviation at both ends indicates heavy tails; an S-shaped departure indicates skewness.
Scale-Location
Plots against fitted values. Constant variance produces an even horizontal spread. A funnel-shaped or upward-trending pattern indicates heteroscedasticity. When heteroscedasticity is present, coefficient estimates remain unbiased but standard errors become inaccurate, so the actual coverage of confidence intervals can deviate from the nominal level.
Residuals vs Leverage
Plots standardized residuals against leverage . Cook's (1977) distance contours (: orange dashed, : red dashed) are overlaid. Cook suggested comparing to the 50th percentile of , which is typically near 1. This is not a formal rejection threshold but a guide for comparing relative influence among observations.
- Leverage: Measures how far an observation's predictor values are from others. is the conventional threshold for high leverage
- Cook's Distance: Combines leverage and residual size into a single influence measure
Observations outside the contour lines may substantially change the model estimates if removed.
For observations with leverage extremely close to 1 (), the denominators of the standardized residual and Cook's Distance approach zero and the computation becomes numerically unstable, so MIDAS displays both as 0. This does not mean the observation has little influence; it indicates that the leverage itself is extreme. Check the horizontal axis of the plot.
Point Selection
Click or rectangle-select data points on any plot to display details (fitted values, residuals, leverage, Cook's Distance, etc.) in a table below the plots. Selection state is synchronized across all four plots.
Notes
Using Categorical Variables
To use string or other categorical variables as predictors, convert them to numeric dummy variables using the Dummy Coding tab before running the analysis. Boolean columns need no conversion and are treated as 0/1.
Automatic Exclusion of Missing and Invalid Values
Rows containing missing values (null), non-numeric values, or infinity are automatically excluded from the analysis. The number of excluded rows is displayed in the Model Summary. This is listwise deletion. See Missing Data Mechanisms for conditions under which it yields valid estimates.
Multicollinearity
When predictors are highly correlated, coefficient estimates become unstable. If VIF (Variance Inflation Factor) is large for any variable in the coefficients table, consider removing redundant variables or combining correlated predictors. See Regression Analysis Fundamentals for details on VIF.
Sample Size and Normality
Whether the coverage probability of the confidence intervals matches the nominal level in finite samples depends on the normality of errors. With large samples, the central limit theorem keeps the coverage approximately correct, but for small samples, verify residual normality using the Q-Q plot. The required sample size depends on the true error distribution, so no universal threshold applies.
References
- Cook, R. D. (1977). Detection of influential observation in linear regression. Technometrics, 19(1), 15-18. https://www.jstor.org/stable/1268249
Next steps
- Residual Diagnostics - Verify model assumptions
- Generalized Linear Model (GLM) - Modeling count data and binary outcomes
See also
- Regression Analysis Fundamentals - Mathematical background of OLS and diagnostic statistics
- Dummy Coding - Converting categorical variables to numeric
Also available as a Markdown file.