Basic Statistics
The Statistics tab displays statistical information for the selected columns.
See also the "View Basic Statistics" section in Getting Started.
Statistics by Data Type
The statistics displayed vary depending on the column's data type.
Numeric Type (int64, float64)
When you select a numeric column, the following statistics are displayed.
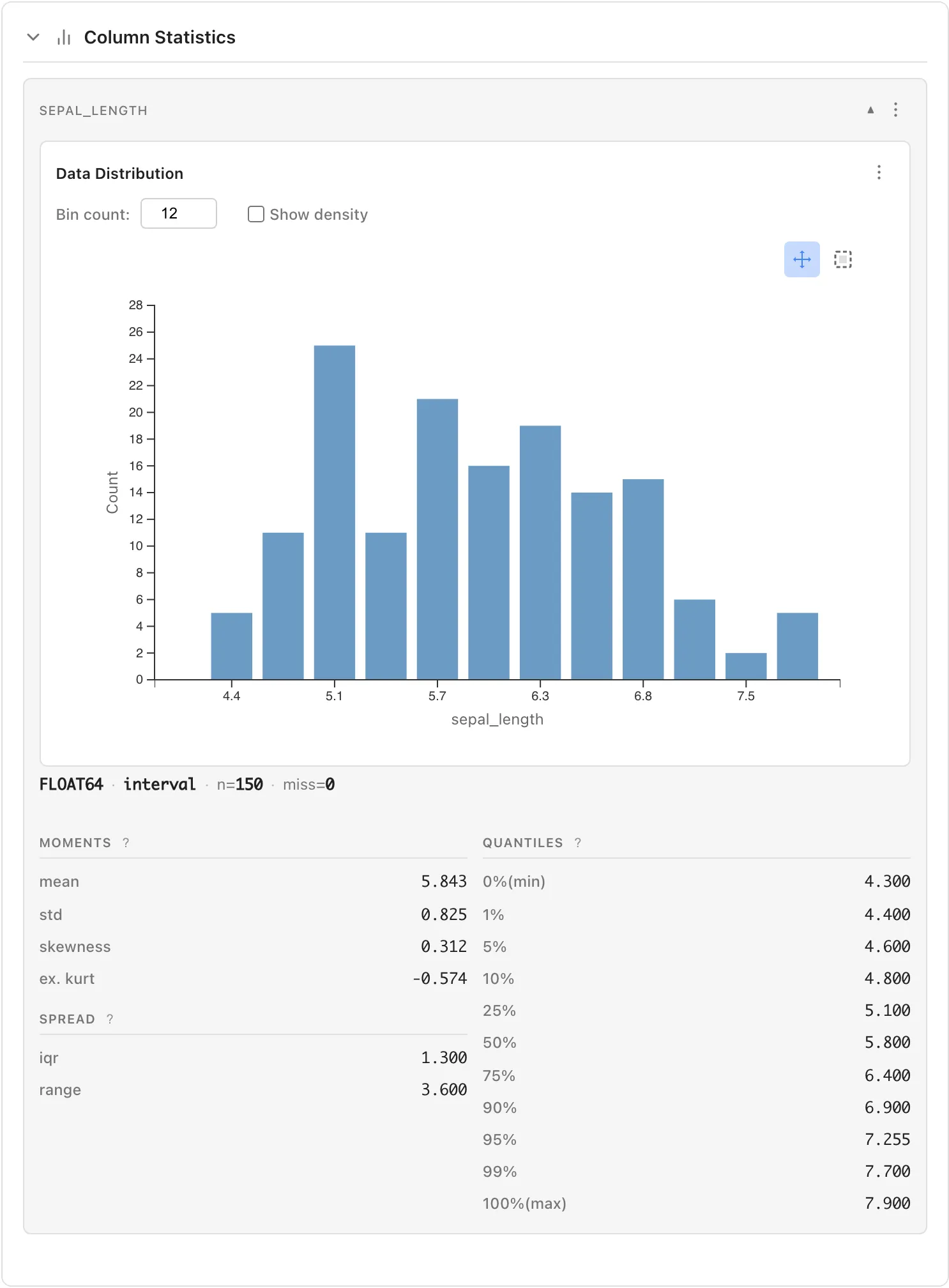
Measurement Scales and Displayed Statistics
For numeric types, MIDAS displays only statistically meaningful items based on the column's measurement scale (Nominal, Ordinal, Interval, Ratio).
| Statistic | Nominal | Ordinal | Interval | Ratio |
|---|---|---|---|---|
| Category breakdown (Most frequent) | o | o | ||
| min / max | o | o | o | |
| Quantiles (median, etc.) | o | o | o | |
| mean / std | o | o | ||
| skewness / ex. kurt | o | o | ||
| iqr / range | o | o |
For example, postal codes should be treated as Nominal scale. When treated as nominal, mean and standard deviation are not displayed because numerical magnitude has no meaning for nominal scales.
See Data Preparation and Import for how to change measurement scales.
For numeric columns with Nominal or Ordinal scale, a breakdown of counts per value (Most frequent) is displayed.
Basic Information
The column header shows data type, measurement scale, valid count (n), and missing count (miss).
Example: FLOAT64 · interval · n=150 · miss=0
Data Distribution (Histogram)
Visualize the distribution of your data. For numeric columns with Ordinal scale, a Category Distribution bar chart showing the count for each value is displayed instead of a histogram. For numeric columns with Nominal scale, both the histogram and the Category Distribution chart are displayed.
- Bin count: Adjust the number of histogram bins
- Show density: When checked, overlays a kernel density estimation curve on the histogram
Use the buttons at the top right of the chart to switch operation modes:
- Pan mode: Drag to pan the chart
- Select mode: Drag to select a range and highlight corresponding rows
Moments
- mean: Average value
- std: Sample standard deviation
- skewness: Skewness where is the sample standard deviation defined above (bias-corrected, ). 0 indicates symmetry; positive values indicate right-skewed
- ex. kurt: Excess kurtosis where is the sample standard deviation (bias-corrected, ). 0 indicates the same kurtosis as the normal distribution; positive values indicate heavier tails
For columns with ratio scale, the following statistics are also displayed:
- cv: Coefficient of variation . Represents the relative magnitude of variability to the mean
- geo mean: Geometric mean . Defined only when all values are strictly positive. Hidden for columns that contain zero or negative values
Spread
- iqr: Interquartile range (75th percentile - 25th percentile)
- range: Range (maximum - minimum)
Quantiles
For numeric columns with interval or ratio scale, quantiles are calculated on the sorted data by computing and linearly interpolating as (R type 7). For ordinal columns (both numeric and Enum), quantiles are the -th value of the sorted data without interpolation (R type 1), so the result is always an existing observed value. Shows positions when data is sorted in ascending order:
- 0%(min): Minimum value
- 1%, 5%, 10%: Lower percentiles
- 25%: First quartile
- 50%: Median
- 75%: Third quartile
- 90%, 95%, 99%: Upper percentiles
- 100%(max): Maximum value
String Type and Enum Type
When selecting a string or Enum column, the following are displayed:
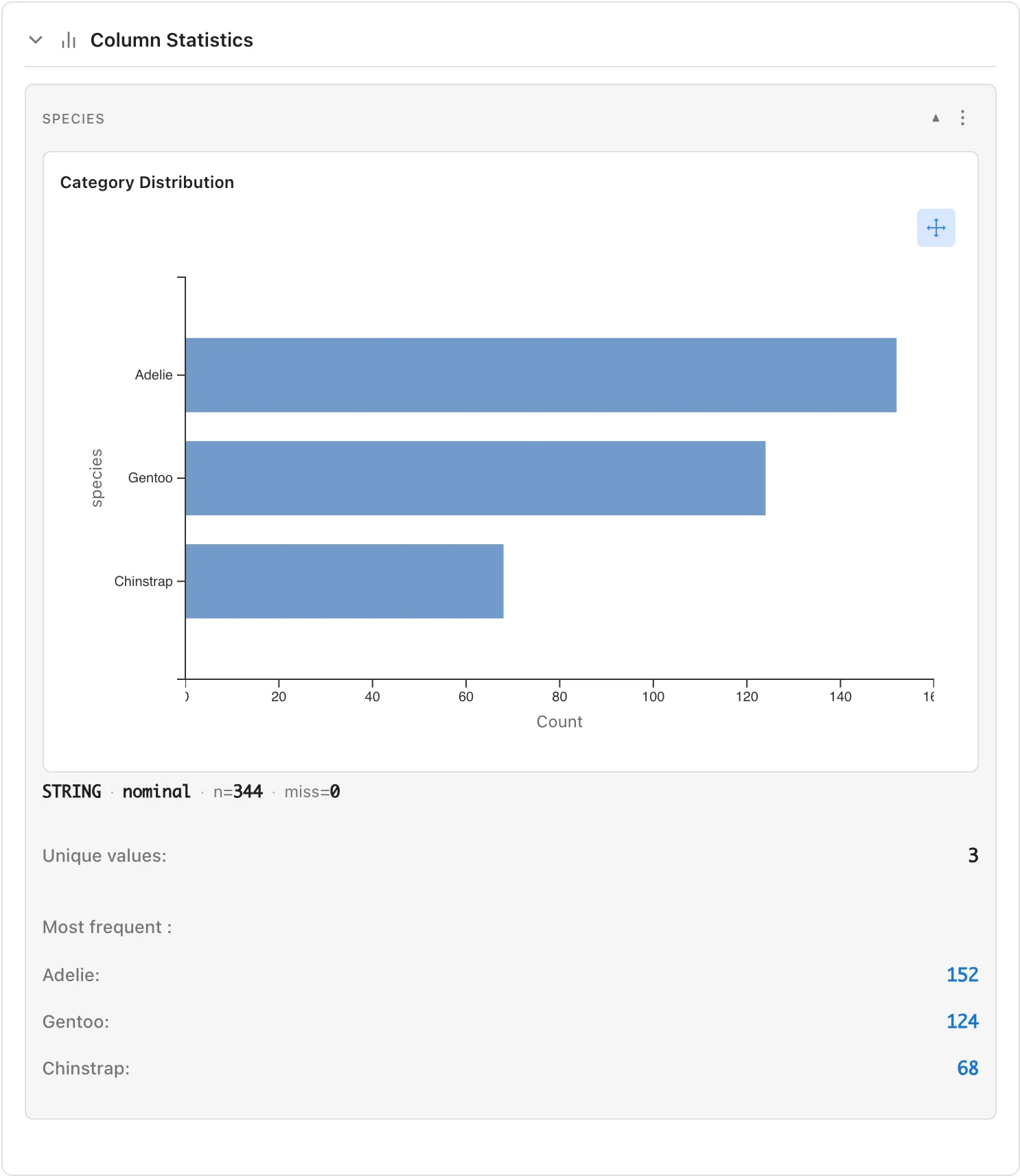
- Category Distribution: Bar chart showing count for each category
- Unique values: Number of unique values
- Most frequent: Most frequent values and their counts (click to select corresponding rows)
When an Enum column's measurement scale is changed to ordinal, min / max / median / Q1 / Q3 are also computed based on the position order of the Enum definition, in addition to the frequency counts above. mean / std / skewness / ex. kurt are not computed because ordinal categories do not have a defined distance. IQR (= Q3 − Q1) is also not computed because subtraction between category values is not defined. See Enum Definitions for details.
Boolean Type
When selecting a True/False column, the following are displayed:
- True: Count and percentage of True values
- False: Count and percentage of False values
Datetime Type
When selecting a datetime column, the following are displayed:
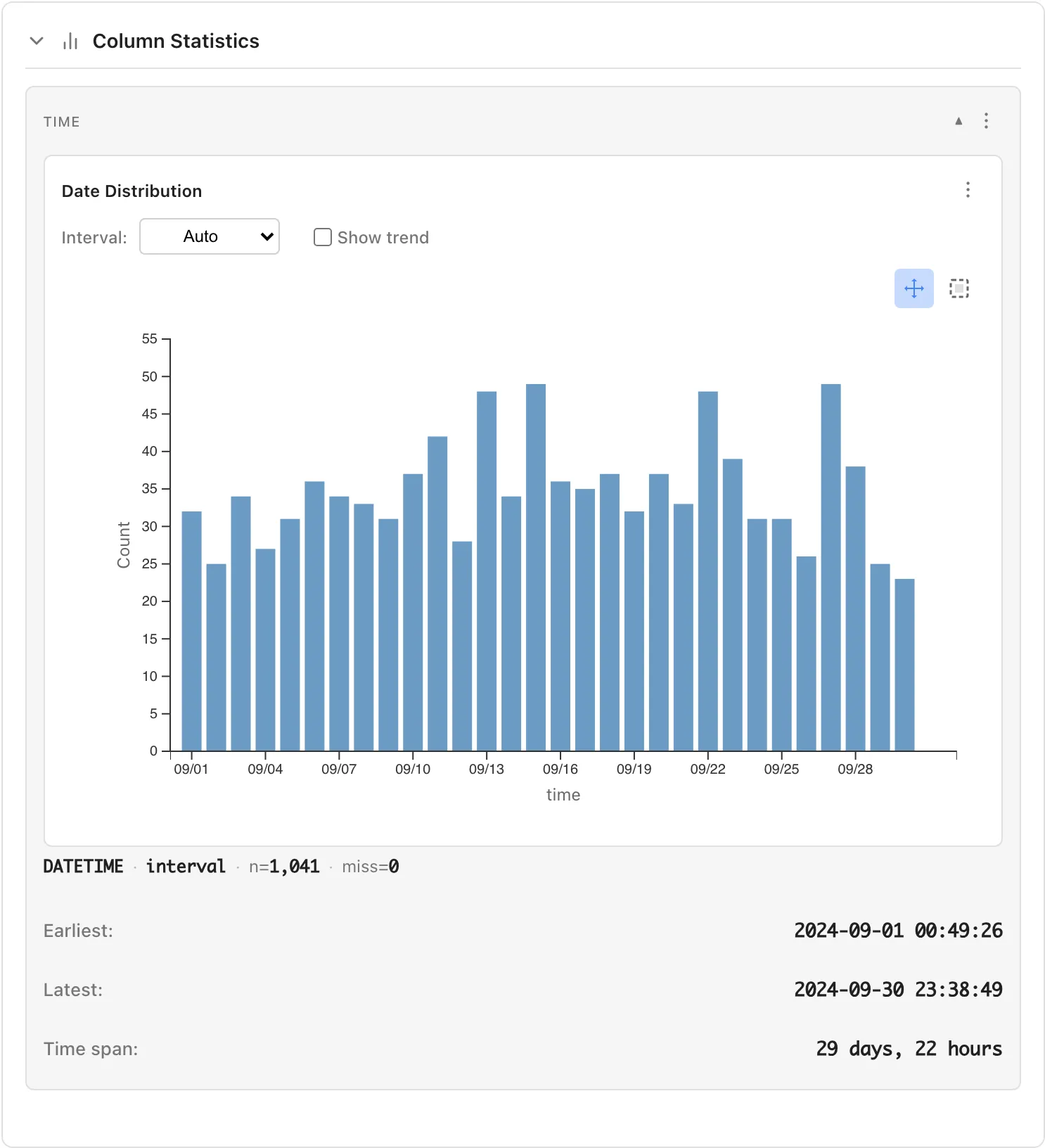
- Date Distribution: Chart showing data distribution over time
- Interval: Select aggregation interval (Auto, 1 minute, 1 hour, 1 day, 1 week, 1 month, etc.)
- Show trend: Display trend line
- Earliest: The oldest datetime
- Latest: The most recent datetime
- Time span: Duration (e.g., "29 days, 22 hours")
Comparing Multiple Columns (Relationships)
When you select two or more columns, the Relationships section appears. The display varies depending on the number and kinds of the selected columns. In this section, columns with Interval or Ratio scale are treated as numeric, and columns with Nominal or Ordinal scale are treated as categorical.
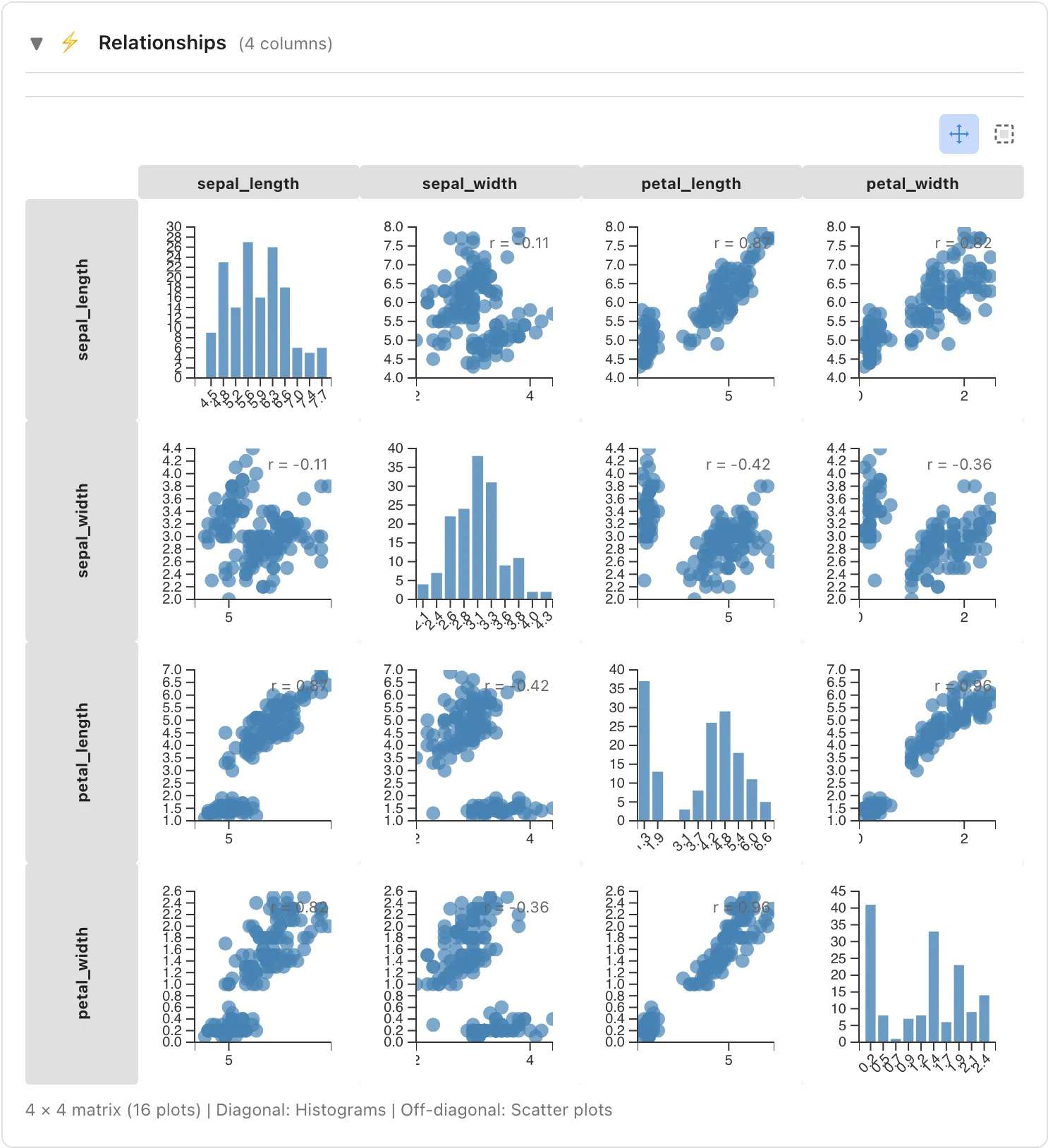
Scatter Plot Matrix (2-4 columns)
When 2-4 columns are selected, the display depends on the combination of the selected columns.
When all columns are numeric (scatter plot matrix):
- Diagonal: Histogram for each column
- Off-diagonal: Scatter plot for each column pair, with the Pearson correlation coefficient shown at the top right of each cell
When categorical columns are included: The following is displayed for each pair of columns:
- Numeric × Numeric: Scatter plot
- Categorical × Numeric: Bar chart aggregating the numeric column by category
- Categorical × Categorical: Cross tabulation (frequency table)
Correlation Matrix (5+ columns)
When 5 or more columns are selected, a Pearson correlation coefficient heatmap is displayed instead of the scatter plot matrix. Color intensity indicates correlation strength. Right-click the correlation matrix to add it to a report.
The Pearson correlation coefficient measures the strength of the linear relationship between two variables on a scale; note that it cannot capture nonlinear relationships (e.g., U-shaped relationships). It is also sensitive to outliers.
Comparison Table
Compare statistics of the selected numeric (int64, float64) columns side by side. Displays type, scale, n, and miss as basic information, along with mean, std, skewness, ex. kurt, quantiles (min through max), iqr, and range for each column. String, Enum, boolean, and datetime columns are not included in the Comparison table; check them in the individual Column Statistics. Numeric columns with Nominal or Ordinal scale are included in the table, but statistics that are not computed for that scale are shown as "-".
Grouping Feature
Select a column from the Show stats by dropdown to group data by that column's values and view statistics for each group.
How to Use
- Select a column to use for grouping from the Show stats by dropdown in the Statistics tab (e.g.,
species) - Statistics are displayed for each value in the selected column
Usage Example
When selecting the sepal_length column in the Iris dataset and grouping by species:
- Statistics for sepal_length of Iris-setosa
- Statistics for sepal_length of Iris-versicolor
- Statistics for sepal_length of Iris-virginica
are displayed separately, enabling comparison between species.
Row Selection Integration
You can select data rows from charts in the Statistics tab. See Row Selection for an overview of how selection works across tabs.
Selection from Histogram
Use the buttons at the top right of the chart to switch operation modes:
- Pan mode: Drag to pan the chart (default)
- Select mode: Drag to select a range
Click a bar: Click a histogram bar to select rows within that bin (range).
Rectangle selection: In Select mode, drag to specify a range and select data within that area.
Selected rows can be viewed in the Selected Rows tab.
Adding to selection: Hold Ctrl (Mac: Cmd) while clicking to add to existing selection.
Selection from Scatter Plot
The scatter plot matrix displayed when multiple numeric columns are selected also supports clicking and rectangle selection for row selection.
Opening Filtered Data Tab
Double-click on a data point or bar in the chart to automatically open a Filtered Data tab displaying the selected data.
Also available as a Markdown file.