Tutorial: Assembly Line Dimension Error Analysis
This tutorial walks through finding patterns with graphs and quantifying them with ANOVA and linear regression, using inspection data from a manufacturing plant.
An automotive parts assembly plant has three lines — A, B, and C — and inspects the dimensions of finished parts. The shop floor reports that Line B may be producing larger dimension errors, but environmental conditions such as temperature and humidity also change from day to day, so it is unclear whether the line itself or the environment is driving the difference. Using 300 inspection records, we separate the line differences from the contribution of environmental factors.
Load the Data
Click Assembly Line in the Sample Data section of the launcher screen to load a dataset with 300 rows and 7 columns.
| Column | Description |
|---|---|
line | Assembly line (A / B / C) |
shift | Shift (Day / Night) |
operator | Operator ID (Op1 -- Op5) |
temperature | Ambient temperature (°C) |
humidity | Humidity (%) |
cycle_time | Cycle time (seconds) |
dimension_error | Magnitude of deviation from the target dimension (mm, non-negative) |
dimension_error is the response variable. It is non-negative; smaller values mean the part is closer to the target dimension.
Explore with Graphs
Click the dimension_error column in the Data Table tab. The Statistics tab shows a histogram and summary statistics. The overall mean is approximately 0.116 mm and the standard deviation is approximately 0.042 mm.
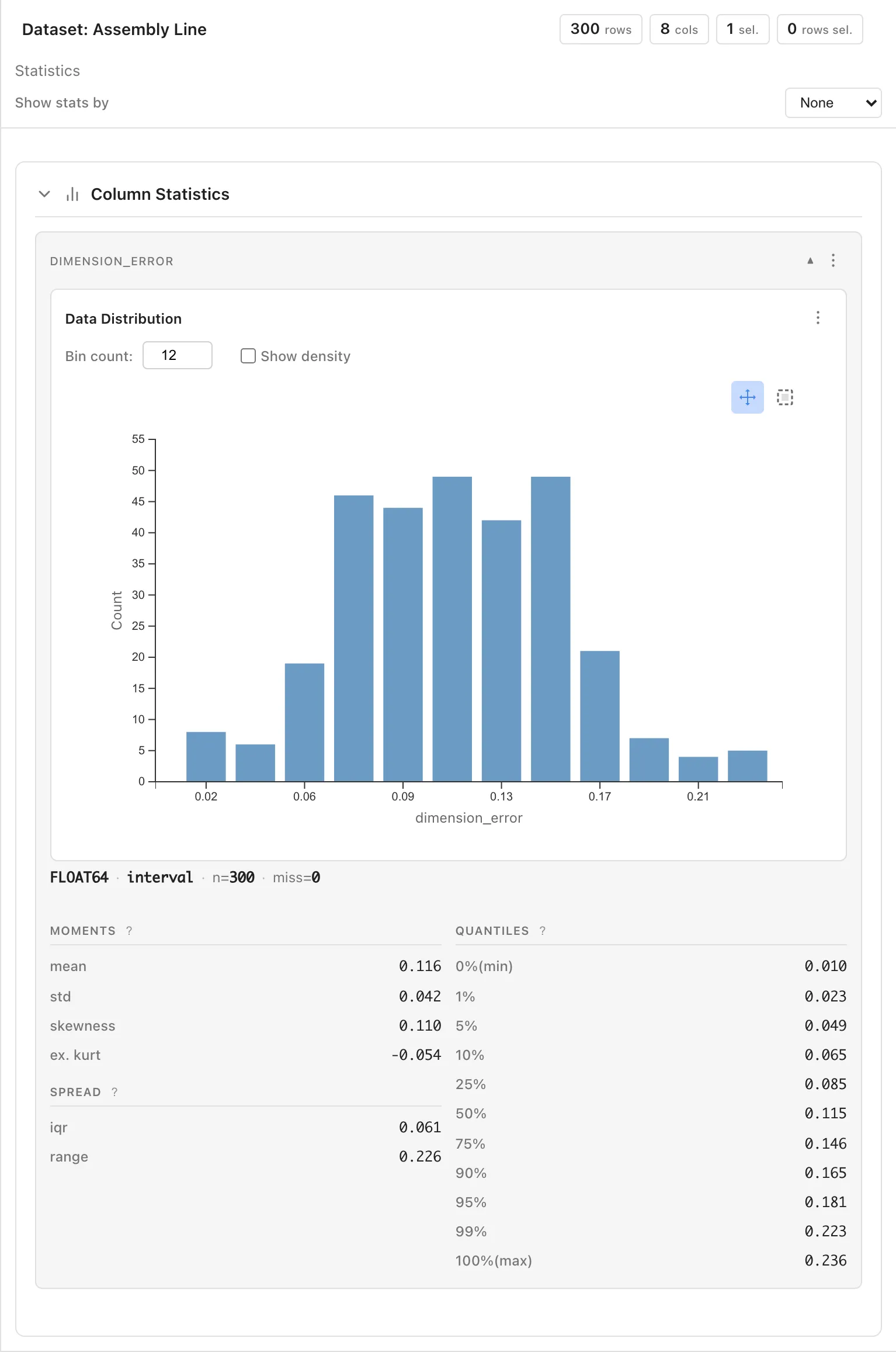
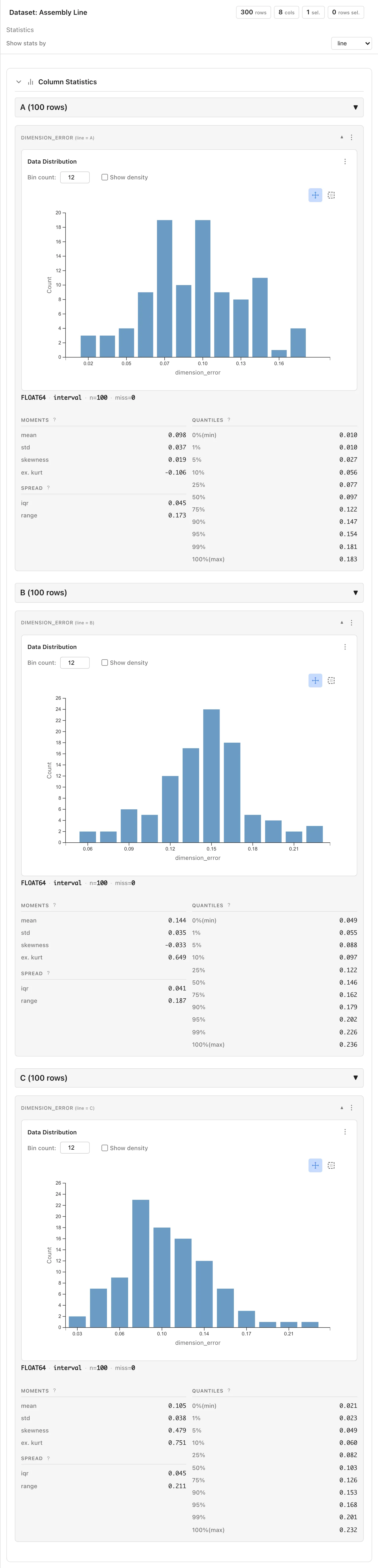
Select line from the Show stats by dropdown to switch to per-line statistics. Line B's mean is higher than A's or C's.
The Statistics tab shows per-line statistics one group at a time. Arranging the lines on a shared axis with Graph Builder's Faceted display makes the relative positions of the distributions visible at a glance. Open Analysis > Graph Builder..., create a Histogram, set Column to dimension_error, set Group By to line, choose Faceted, and set Columns to 1.
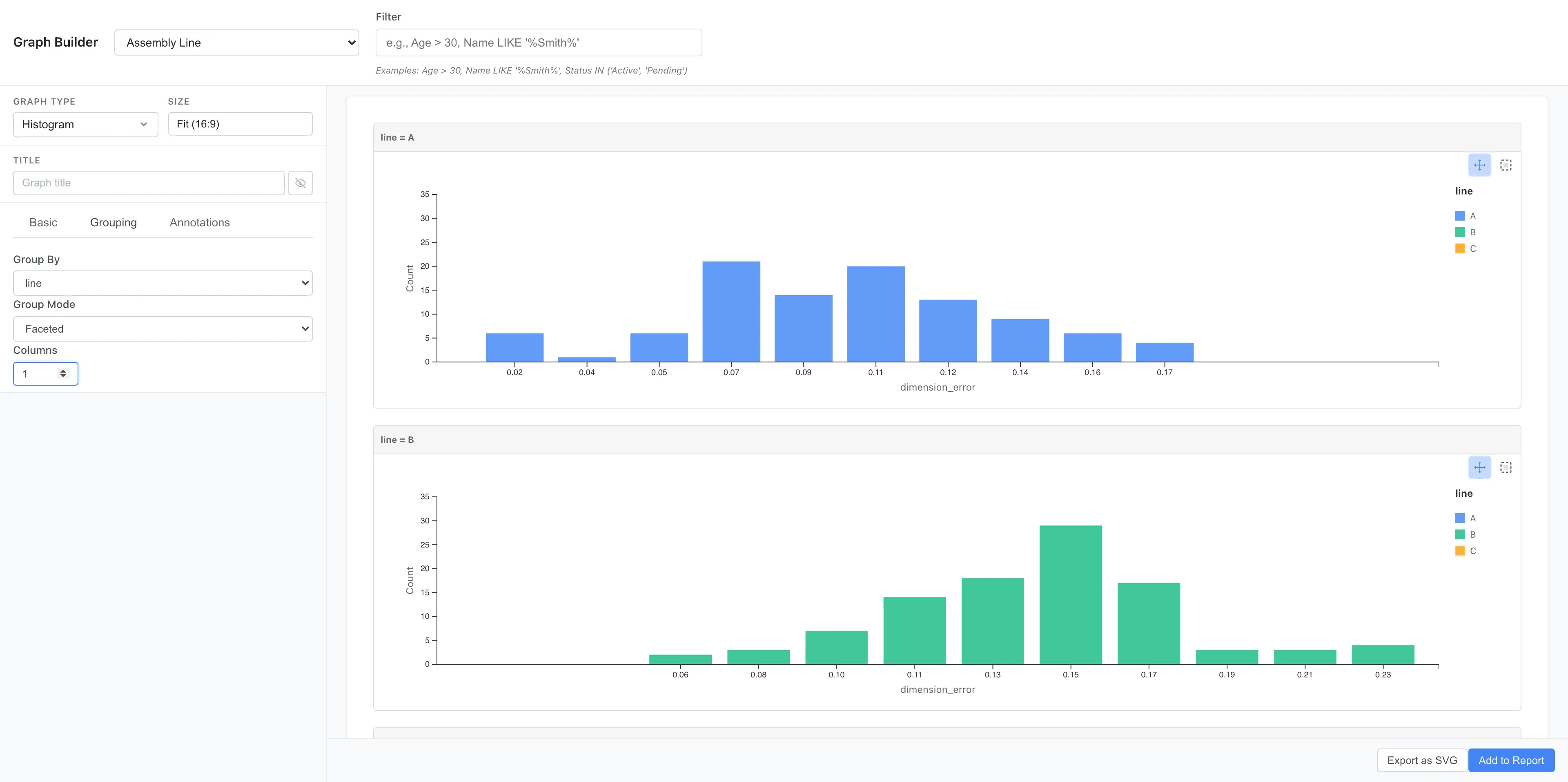
Scroll down to see the histograms for lines A, B, and C stacked vertically.
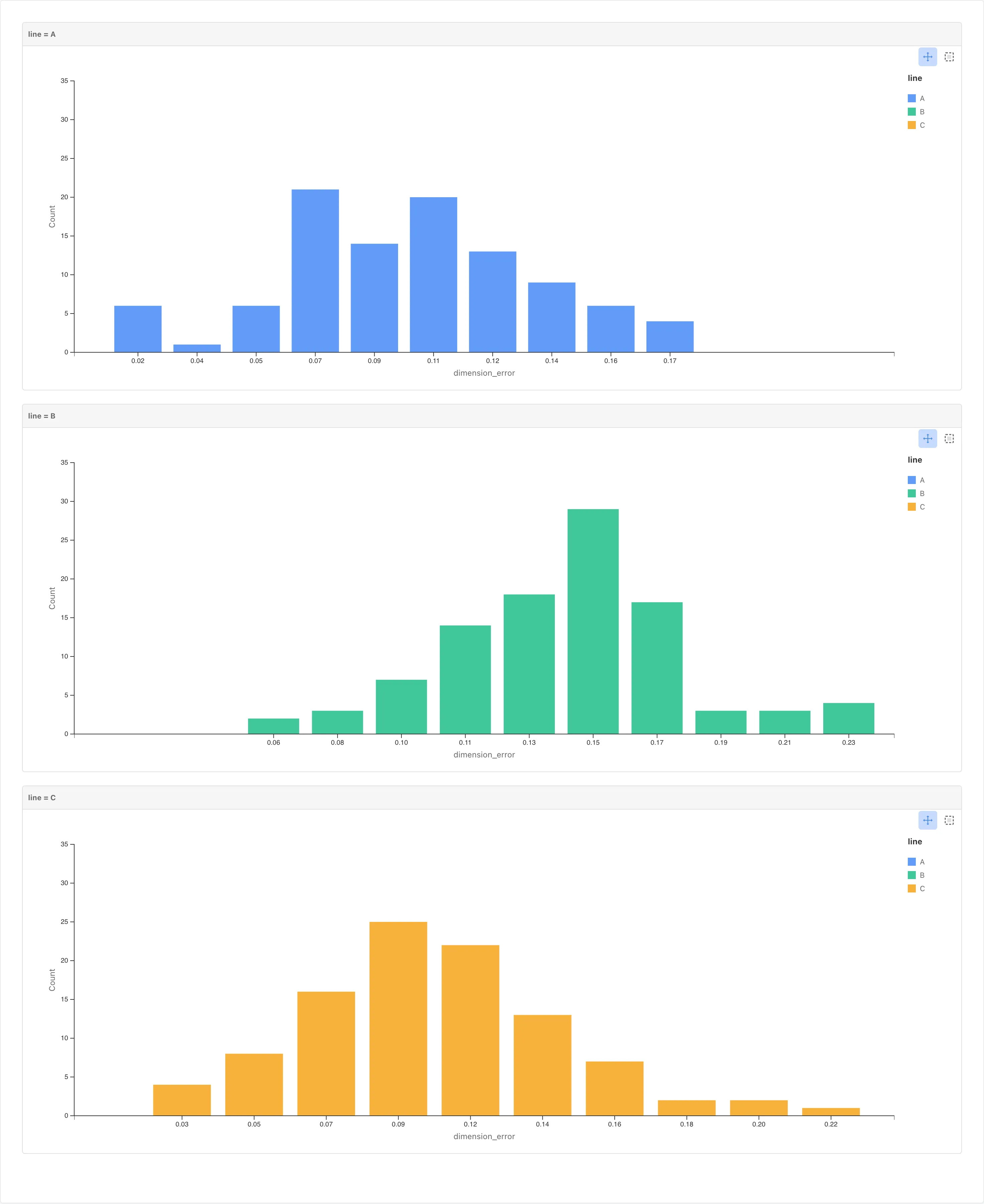
Line B's histogram is shifted to the right. A and C sit in similar positions.
Next, explore the relationship with environmental conditions. Create a Scatter Plot in Graph Builder with X set to temperature, Y to dimension_error, and Color to line.
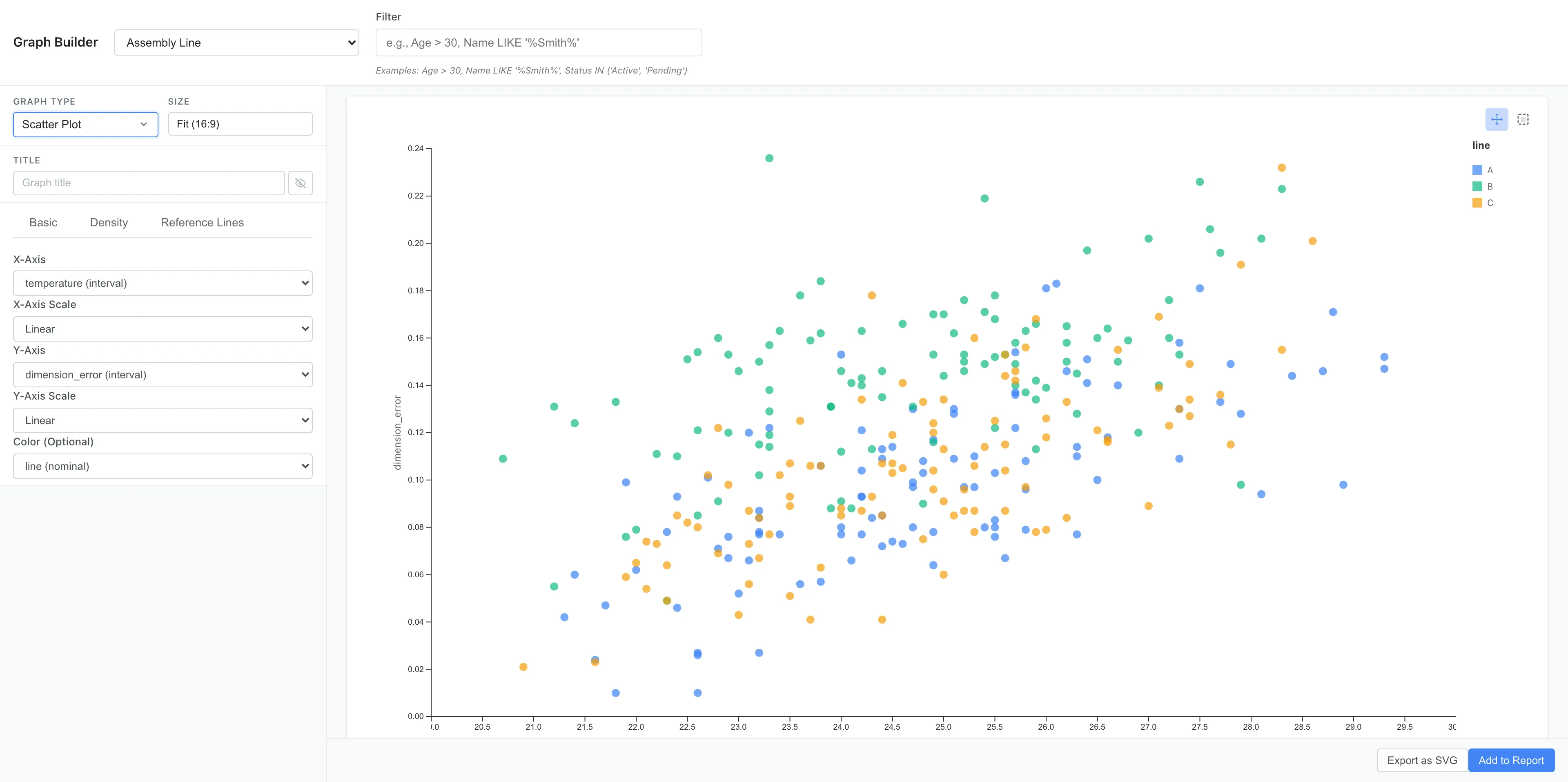
Dimension errors tend to be larger at higher temperatures. Within the same temperature range, Line B's points sit higher than the others.
A question arises here: is Line B's error larger simply because Line B runs hotter? In the scatter plot, points of every color spread across the same range of the temperature axis, and no line is concentrated in the high-temperature region. Whether the line effect and temperature can really be separated is confirmed by the regression in the next sections.
The exploration so far surfaced two independent patterns: Line B has larger errors, and temperature appears positively related to error. The next sections quantify them.
Estimate Line Differences with ANOVA
The graphs suggest Line B's dimension error is larger, but they do not show how many millimeters larger it is, or how precise that estimate is. ANOVA estimates the mean differences between lines with confidence intervals.
The data also contains shift and operator, but we focus on line differences first. Open Analysis > ANOVA..., choose One-Way, set line as the Factor and dimension_error as the Response, and run the analysis.
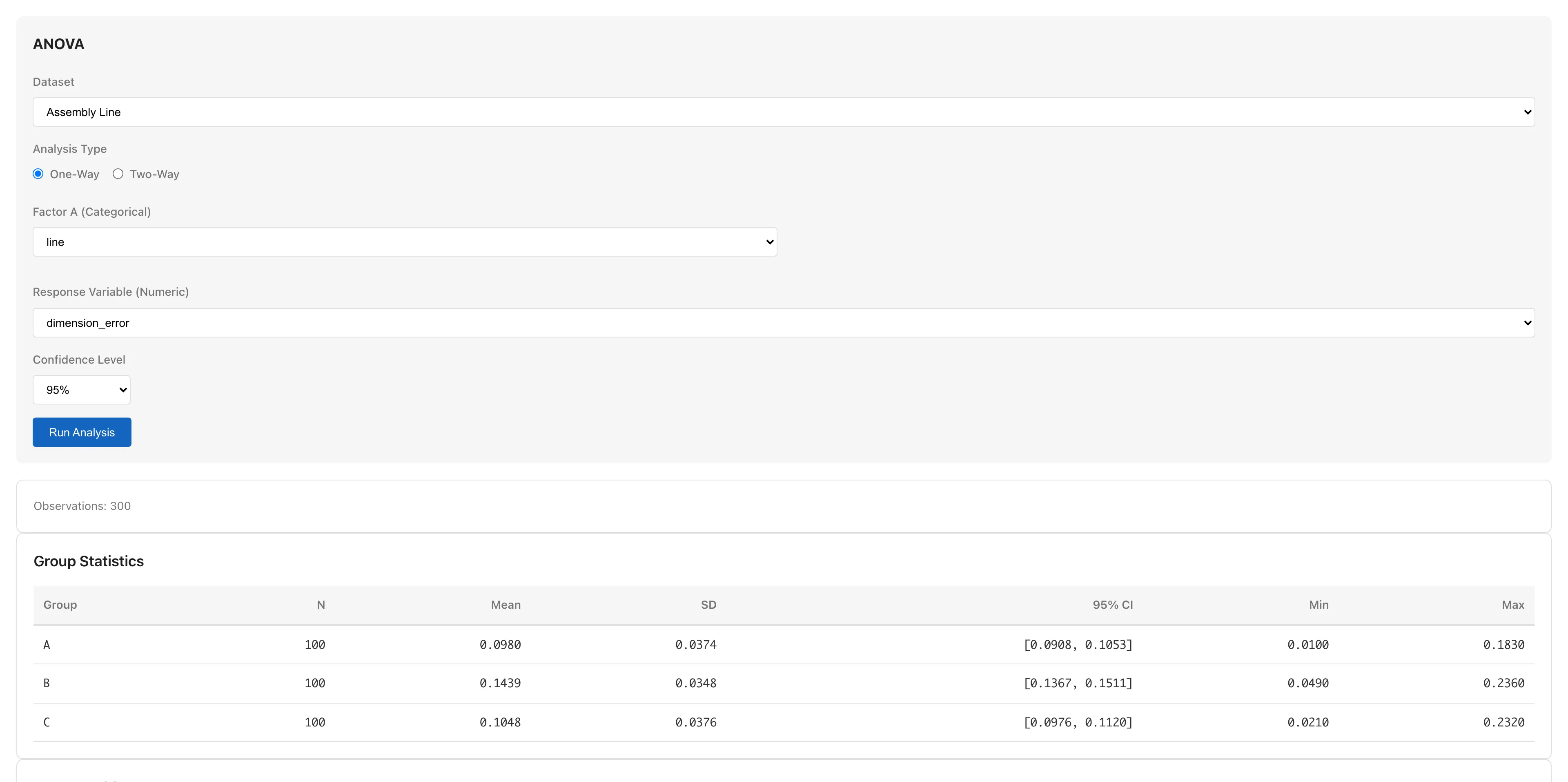
The table shows each group's mean with a 95% confidence interval. Line B's mean is approximately 0.144 mm, higher than A (approximately 0.098 mm) and C (approximately 0.105 mm).
To see the differences in millimeters, use Tukey HSD, which estimates the mean difference for every pair with simultaneous confidence intervals. Simultaneous intervals are made wider than usual so that, taken together across all pairs, they hold the stated confidence level.
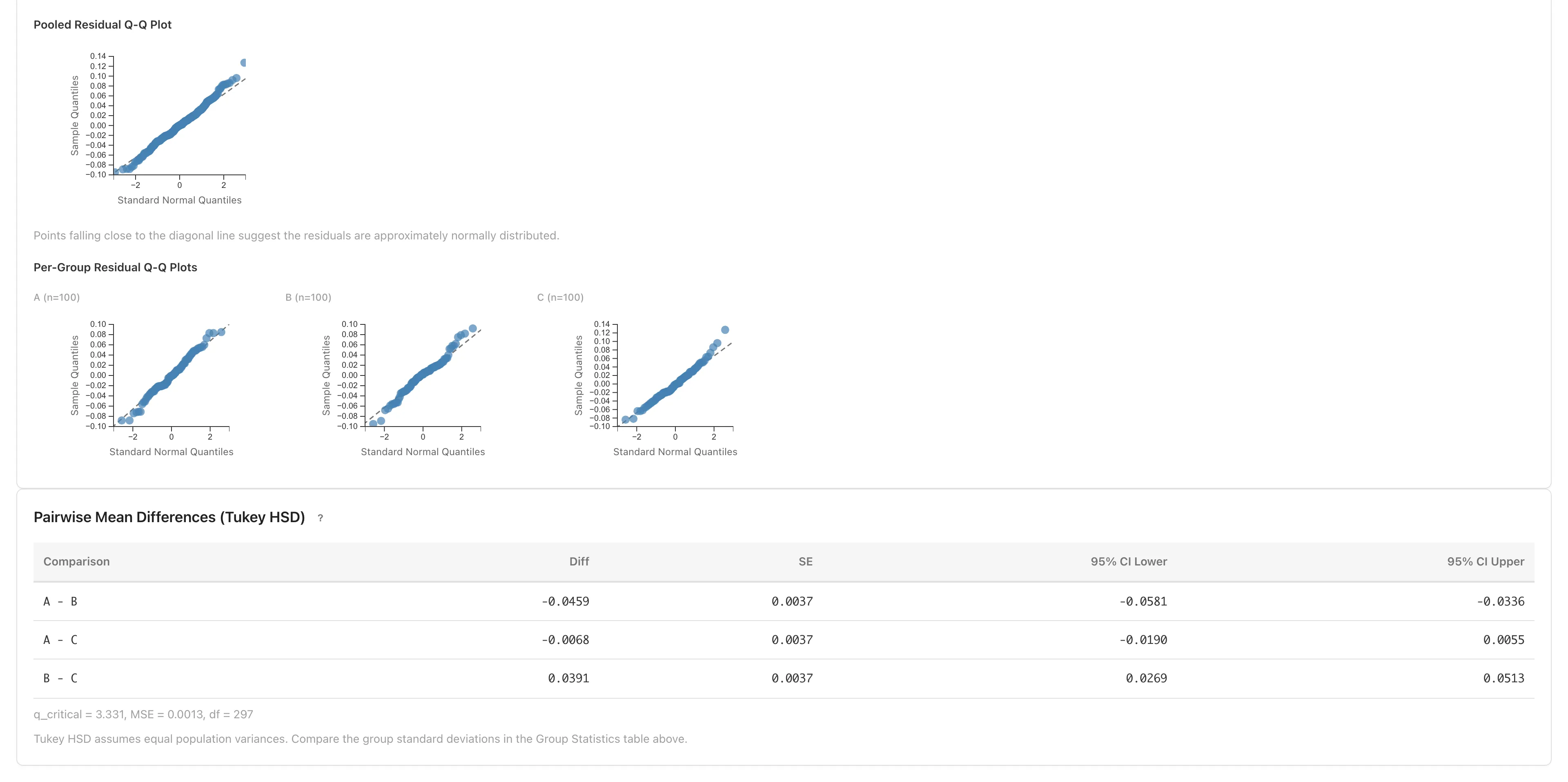
| Pair | Difference (mm) | Direction |
|---|---|---|
| A -- B | approx. −0.046 | B is larger |
| A -- C | approx. −0.007 | nearly equal |
| B -- C | approx. +0.039 | B is larger |
Each difference is computed as "left line − right line" in the pair heading; a negative value means the right line is larger.
The confidence intervals for A -- B and B -- C do not include zero: the difference between Line B and the other lines is stable within the estimation precision. The A -- C interval straddles zero, so even the direction of that difference is not settled.
Line differences are not the whole story, though. In the ANOVA Table, η² is approximately 0.24, meaning that in this dataset about 24% of the total variance in dimension error is explained by differences between lines. The remaining 76% or so is within-line variation — differences in environmental conditions, measurement variability, and other factors. η² is a descriptive statistic for this sample. If you care about the proportion of variance in the population, see the ANOVA table, which covers ω², its estimator.
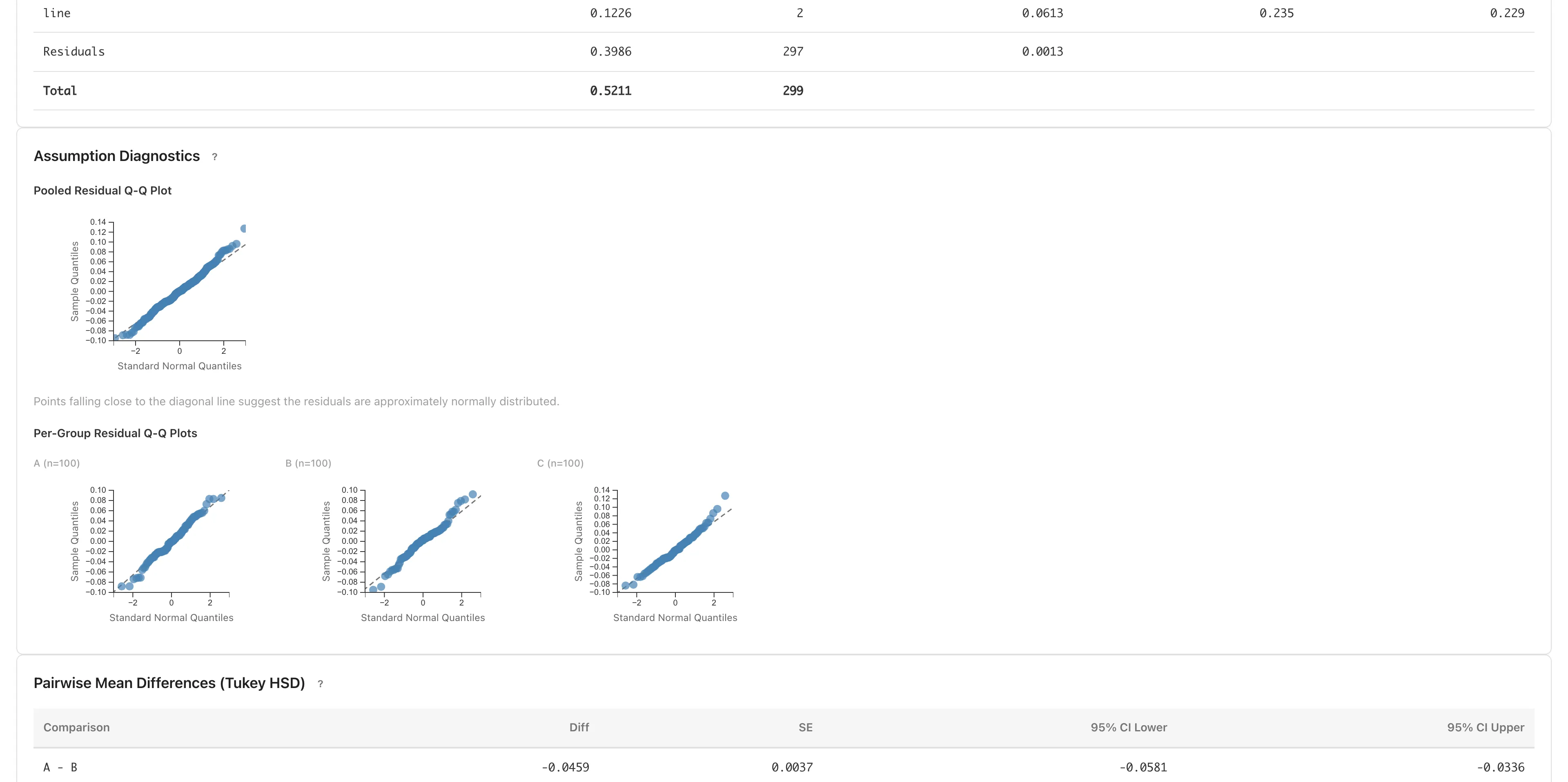
That remaining 76% may include environmental conditions such as temperature and humidity, so the next section evaluates line effects and environmental factors together with regression. Before that, check that the data do not depart strongly from the ANOVA assumptions. The Assumption Diagnostics section shows both a Q-Q plot of all residuals and per-group Q-Q plots. Because ANOVA assumes normality within each group, if each line's residuals in the per-group Q-Q plots roughly follow the diagonal, there is no obvious departure from normality. The per-line SDs are also similar (0.035 -- 0.038, a max-to-min ratio of about 1.1), with no large departure from equal variance. MIDAS checks equal variance by comparing the per-group SDs. For the assumptions in detail, see ANOVA assumptions.
Evaluate Line Effects and Environmental Factors with Regression
ANOVA looked only at line differences; the contribution of the environmental variables is still unknown. Linear regression puts the line effects and the environmental factors into a single model and estimates them together.
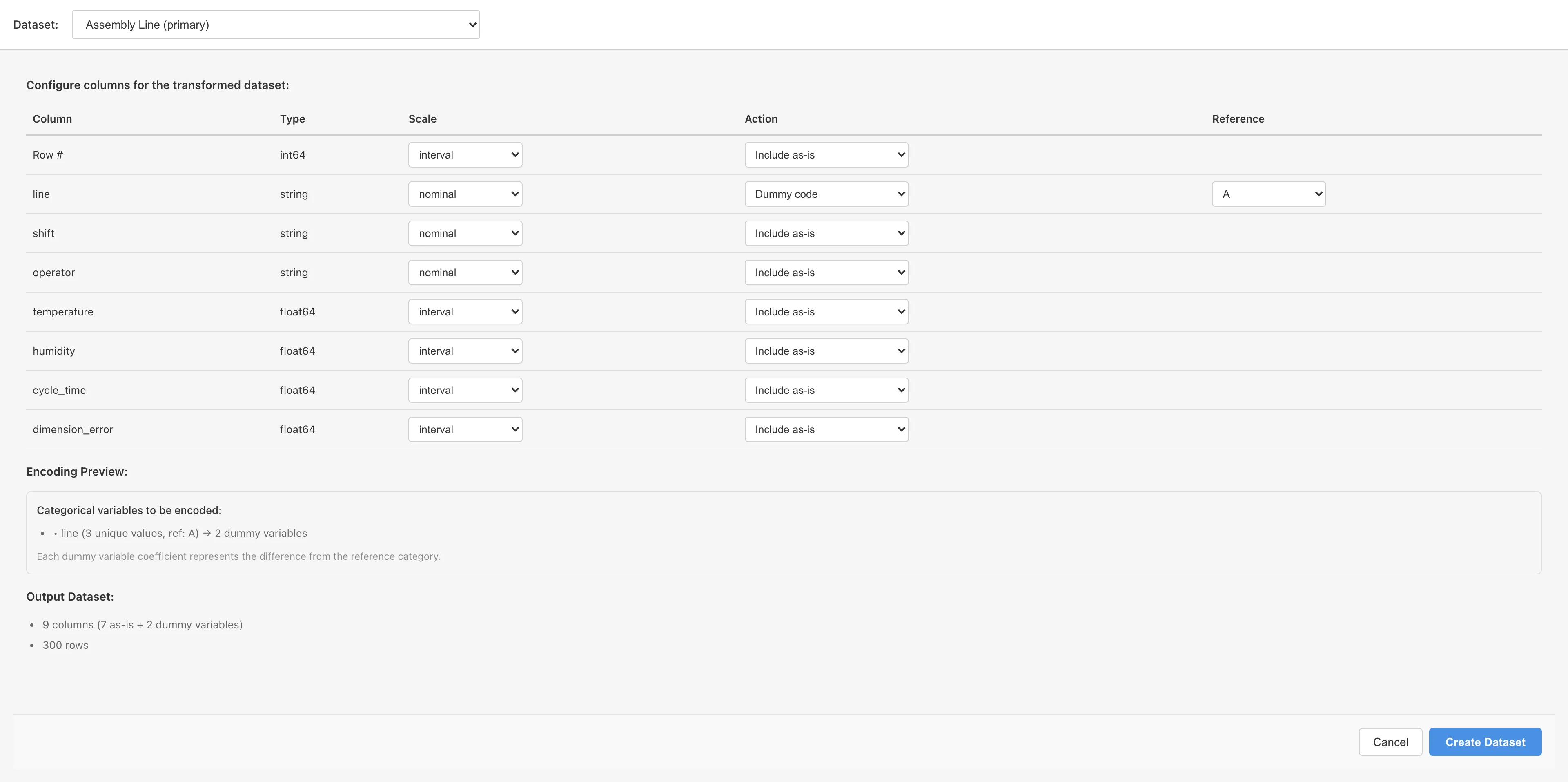
OLS predictors must be numeric, so convert line (A/B/C) into 0/1 columns. Open Data > Dummy Coding... and set the Action for line to Dummy code. Reference defaults to A, the first value alphabetically. With A as the reference, two columns are generated: line_B (is it B?) and line_C (is it C?). No column is needed for A — if both are 0, the row is A. Whichever line you pick as the reference, the pairwise differences themselves do not change; only the interpretation — which line each coefficient is a difference from — changes.
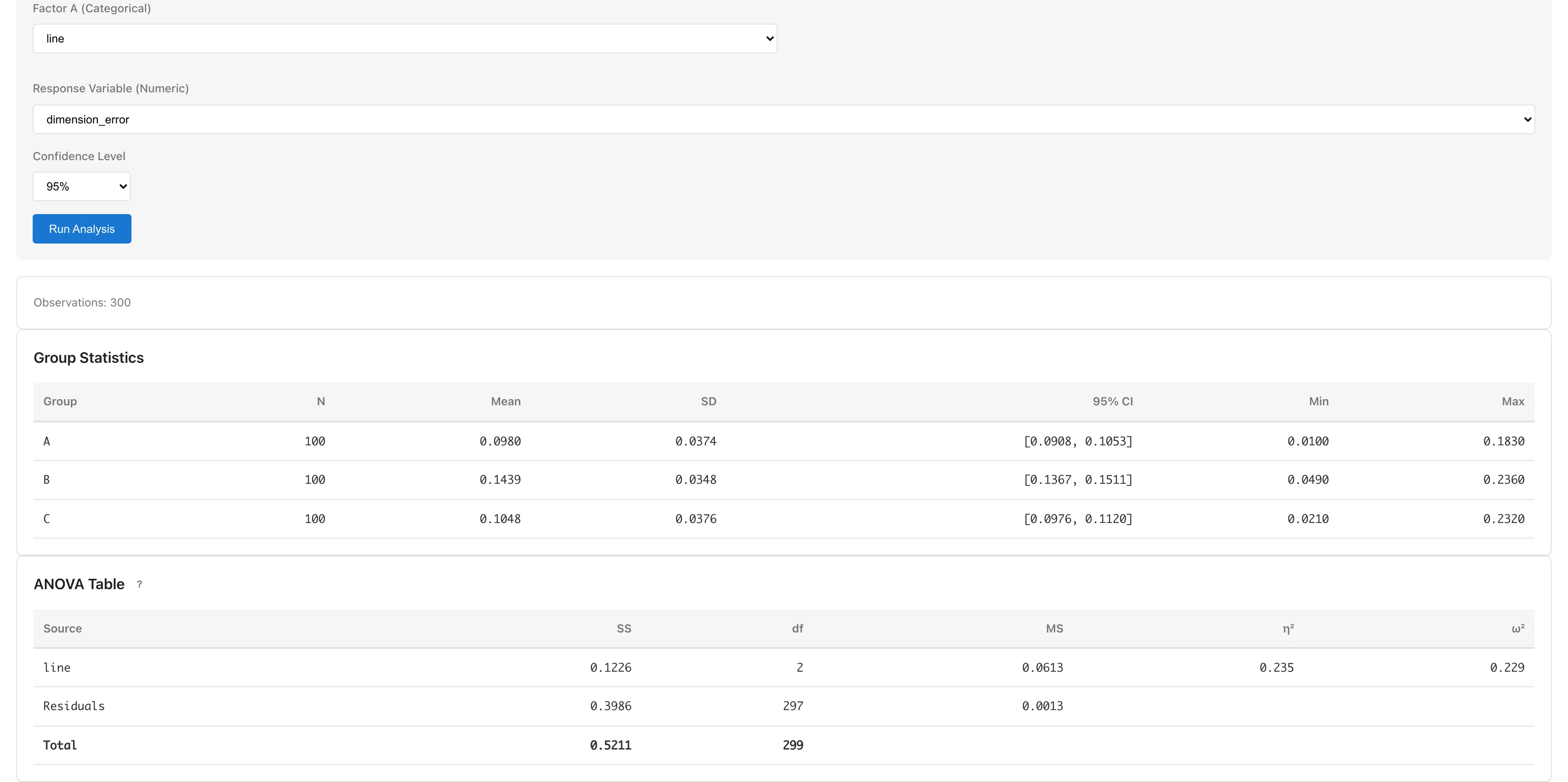
On the converted dataset, open Analysis > Linear Regression (OLS)... and set dimension_error as the Response and line_B, line_C, temperature, humidity, and cycle_time as Predictors.

Click Run Analysis.

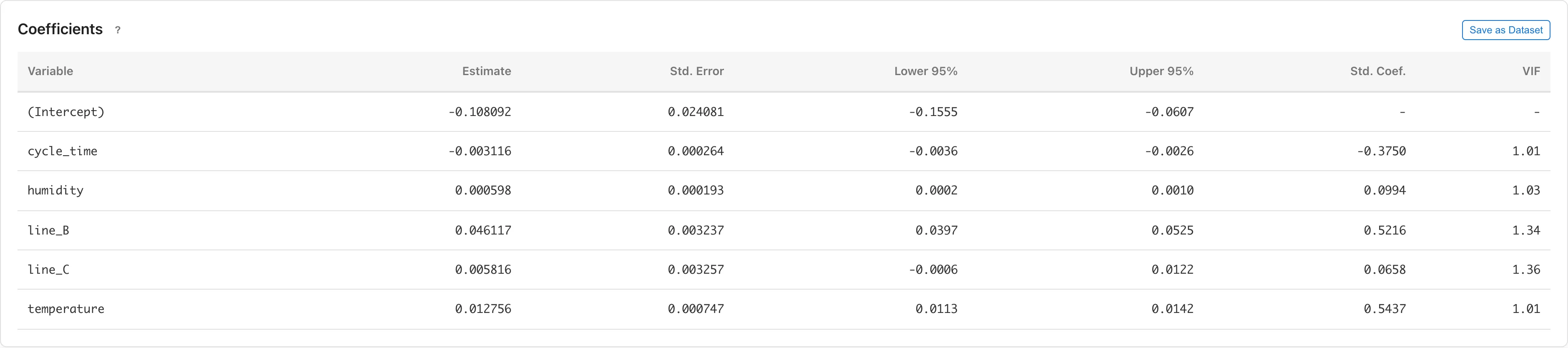
R-squared is approximately 0.71: the line effects and environmental variables together explain about 71% of the variance in dimension_error. R-squared rises from line's η² alone (about 24%) to about 71%, but this increase cannot be split uniquely into each predictor's contribution. When predictors are correlated, the decomposition depends on the order in which they enter.
Interpret the Coefficients
The coefficients read here are exploratory estimates, chosen for attention after seeing the data. They are also associations estimated from observational data, not the causal effect of changing each variable on the error.
The line_B coefficient is approximately +0.046 mm. Holding temperature, humidity, and cycle time constant in the same model, Line B's dimension error is estimated to be 0.046 mm larger on average than Line A's. Holding other variables constant this way is called "controlling" for them in regression; see Interpreting coefficients for what this means. This is nearly the same as the Tukey HSD A -- B difference. The line_C coefficient is approximately +0.006 mm with a confidence interval straddling zero, so the difference from A is estimated to be small.
The temperature coefficient is approximately +0.013 mm/°C: observations 1°C warmer have on average 0.013 mm larger dimension error. To compare the magnitudes of variables on different scales, use the standardized coefficient (Std. Coef.). Among the environmental variables, temperature has the largest Std. Coef. Still, a larger standardized coefficient does not necessarily mean a variable is more important; see Interpreting coefficients for background.
The cycle_time coefficient is approximately −0.003 mm/s; observations with longer cycle times tend to have smaller errors.
The humidity coefficient is small at 0.001, contributing little.
Strong correlation among predictors makes the coefficient estimates unstable. Here the VIF values are all small, showing no sign of that. The link also explains how large a VIF should be before you suspect multicollinearity.
Check the Diagnostic Plots
These coefficients and confidence intervals assume normality, equal variance, and linearity of the residuals. Name the model, click Save Model, then View Diagnostics to inspect the diagnostic plots.
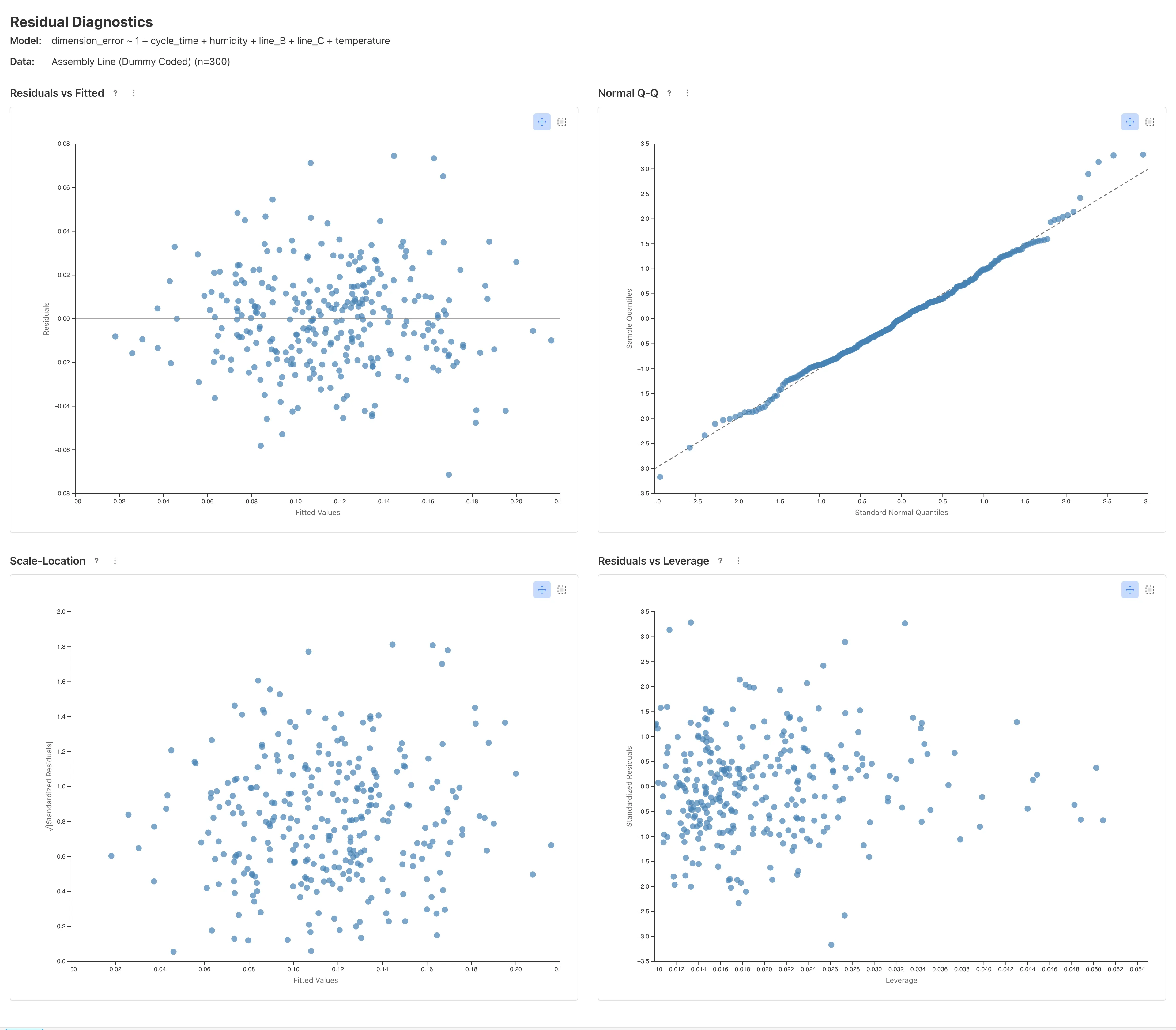
If the residuals in Residuals vs Fitted scatter randomly around zero, there is no obvious departure from linearity; a funnel pattern would suggest heteroscedasticity. If the standardized residuals in Normal Q-Q roughly follow the diagonal, there is no major departure from normality. If in Scale-Location shows no systematic trend, unequal variance is not prominent. If no points fall outside the Cook's Distance contours (0.5 and 1.0) in Residuals vs Leverage, no single observation distorts the estimates strongly. For how to read each plot and what to do when problems appear, see the diagnostic plots in Linear Regression.
Summary
Returning to the original question — is Line B's dimension error really larger? — here is what the analysis showed. All of these are exploratory estimates chosen for attention after seeing the data; see Notes on This Analysis for how to confirm them.
- Line B's dimension error is on average 0.046 mm larger than Line A's, and the estimate is stable after controlling for the environmental variables (the regression line_B coefficient and Tukey HSD nearly agree). There is no clear difference between A and C
- Line differences account for only about 24% of the total variance. Most of the variability in dimension error depends on factors other than the line
- Line B's larger error is not explained by skewed environmental conditions, such as Line B running hotter. The line_B coefficient remains after controlling for the environmental variables in the regression model, so some line-specific factor exists
- Among the environmental factors, temperature has the strongest association (approximately 0.013 mm per 1°C), and cycle time has a negative association. Whether managing temperature or revisiting cycle times would reduce errors can be confirmed with The DoE Analysis Tab, which deliberately varies factors to test their effects
Notes on This Analysis
This is an exploratory analysis in which we decided what to look at after seeing the data: we noticed in the graphs that Line B looked larger and then estimated the difference with ANOVA, and we noticed a temperature relationship in the scatter plot and then fitted a regression. Because we chased patterns that happened to stand out in this dataset, new data might instead show, say, humidity mattering. To give these findings credibility, decide in advance which effects to estimate — the line_B difference, the temperature contribution, and so on — then collect new data and check whether the estimates are reproduced.
Reports
Add to Report collects graphs and analysis results in the Report tab. Assembled into a report, the results of this analysis look like this.
View Live Demo
Click to launch the MIDAS application
Related Pages
- ANOVA -- ANOVA tab details, two-way ANOVA, sum of squares types
- Linear Regression -- coefficients table, diagnostic plots, prediction intervals
- The DoE Analysis Tab -- a test plan that deliberately varies factors to confirm effects
- The Graph Builder Tab -- graph types available in Graph Builder
- Report -- Report tab operations
Also available as a Markdown file.