ANOVA (Analysis of Variance)
The ANOVA tab analyzes whether the means of a response variable differ across groups defined by categorical variables. Both one-way and two-way designs are supported. It assumes independent, between-subjects observations and does not support repeated measures or paired data (the same subject measured more than once). For those designs, use a GLMM with the subject as the random-effect group.
Basic Usage
Open the Tab
Select Analysis > ANOVA... from the menu bar.
Run an Analysis
Configure the following in the settings panel:
- Select a dataset from Dataset
- Choose One-Way or Two-Way under Analysis Type
- Select a categorical variable for Factor A (Categorical)
- Select a numeric variable for Response Variable (Numeric)
- Click Run Analysis
Data Format
Data must be in long format with one row per observation. Each row contains the factor value and the response variable value. Use Reshape to convert wide-format data.
One-Way ANOVA
Analyzes differences in the response variable means across groups defined by a single categorical factor. Use this when you have one grouping factor.
Statistical Model
is the -th observation in group , is the overall mean, is the effect of group , and is the error term.
Assessing Group Differences
ANOVA decomposes the total variation in the response variable into between-group variation and residual variation. The decomposition appears as SS, df, and MS in the ANOVA table. Of the effect sizes, η² shows the proportion of the total variation attributable to the factor in the sample, and ω² is an estimate of that proportion in the population. The magnitude and precision of group differences can be read from the simultaneous confidence intervals for pairwise differences from Tukey HSD. The group mean confidence intervals in Group Statistics show the precision of each group mean estimate.
Variable Selection
Factor A (Categorical): Select a categorical variable that defines the groups. Columns with nominal or ordinal measurement scale appear as options.
Response Variable (Numeric): Select the numeric variable to analyze. Columns with interval, ratio, or boolean measurement scale appear as options.
Example
To analyze whether sepal length differs among the three species Iris-setosa, Iris-versicolor, and Iris-virginica in the Iris sample data:
- Dataset: Iris
- Analysis Type: One-Way
- Factor A:
species - Response Variable:
sepal_length - Click Run Analysis
Confidence Level
Set the confidence level for Group Statistics confidence intervals and Tukey HSD post-hoc comparisons. Choose from 90%, 95% (default), or 99%. The Tukey HSD confidence interval width matches the confidence level. This setting also appears in two-way ANOVA, where it applies to the Group Statistics confidence intervals.
Two-Way ANOVA
Analyzes the effects of two categorical factors and their interaction on the response variable. Use this when you have two grouping factors.
Statistical Model
With interaction:
is the effect of factor A, is the effect of factor B, and is the interaction effect.
Additional Settings
Factor B (Categorical): Select a second categorical variable, different from Factor A.
Include interaction term (A x B): Whether to include the interaction term in the model. Enabled by default. Include the interaction when the effect of one factor may depend on the level of the other. If the interaction is known to be absent, excluding it increases the residual degrees of freedom, providing a more precise estimate of the error variance.
Sum of Squares Type: Choose the method for computing sums of squares.
Sum of Squares Types
Type I computes sums of squares sequentially based on the order factors enter the model. Each factor's contribution depends on which factors are already in the model. MIDAS enters Factor A first, then Factor B, then the interaction term. The SS for Factor A is the reduction in residual sum of squares when Factor A is added to the intercept-only model, and the SS for Factor B is the further reduction when Factor B is added. Swapping the Factor A and Factor B assignments changes the results.
Type III computes sums of squares for each factor as if it were the last one entered. Each factor's contribution is adjusted for all other factors.
For balanced designs (equal sample sizes in all cells), Type I and Type III produce identical results. For unbalanced designs, Type III is generally preferred because results do not depend on factor ordering.
Type III Interpretation with Interaction
MIDAS uses treatment coding. Treatment coding designates one level of each factor as the reference category (baseline level) and expresses the effects of all other levels as differences from it. The reference category is the first level in alphabetical order. When the interaction term is included, the Type III main effect for each factor depends on the treatment coding reference category. For example, if Factor A has levels A, B, C and Factor B has levels X, Y, the reference categories are A and X (the first level in alphabetical order). The Type III sum of squares for Factor A represents the additional explanatory power of Factor A's levels compared to a model without them, evaluated when Factor B is at reference level X. With balanced data, this coincides with the effect averaged across all levels of Factor B. With unbalanced data, the two may differ.
Reading the Results
Observations
The total number of observations used in the analysis appears at the top. If rows were excluded due to missing values, the count of excluded rows is also shown.
Group Statistics
A summary table of descriptive statistics for each group.
| Column | Description |
|---|---|
| Group | Group name. In two-way ANOVA, displayed as "Factor A level × Factor B level" |
| N | Number of observations |
| Mean | Group mean |
| SD | Standard deviation (square root of unbiased variance, denominator n − 1) |
| 95% CI | Confidence interval for the group mean in [lower, upper] format. Computed as mean ± t × √(MSE / n) using the pooled MSE from the ANOVA table (t-distribution with residual degrees of freedom). This interval assumes equal variances across groups; when group variances differ, the actual coverage may deviate from the nominal level. The column heading and confidence level match the Confidence Level setting |
| Min | Minimum value |
| Max | Maximum value |
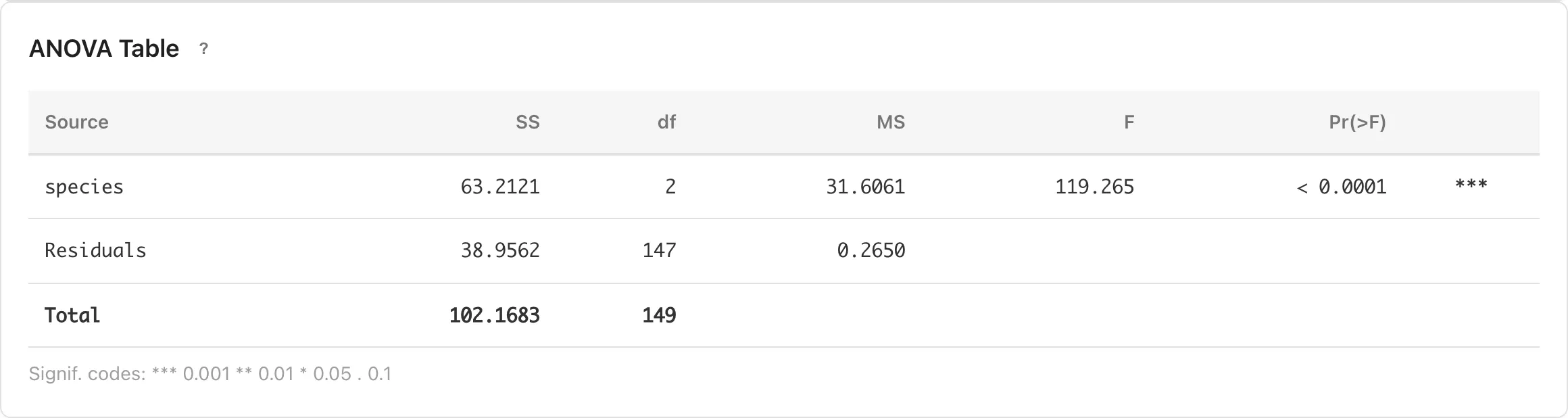
ANOVA Table
The main results table. Decomposes the total variance of the response variable into contributions from each factor and residual error.
| Column | Description |
|---|---|
| Source | Source of variation |
| SS | Sum of squares -- the amount of variation attributable to each source |
| df | Degrees of freedom |
| MS | Mean square (SS / df) |
| η² / partial η² | Eta-squared (one-way) or partial eta-squared (two-way). Computed as SS_effect / (SS_effect + SS_residual). The ratio of the source's variation to the sum of the source and residual variation. Because the denominator excludes variation from other sources, the partial η² values across sources can sum to more than 1 in two-way designs |
| ω² / partial ω² | Omega-squared (one-way) or partial omega-squared (two-way). One-way ω² is computed as (SS_effect − df_effect × MS_residual) / (SS_total + MS_residual), and two-way partial ω² as (SS_effect − df_effect × MS_residual) / (SS_effect + (N − df_effect) × MS_residual). In one-way ANOVA, ω² estimates the proportion of total population variance attributable to the factor (σ²_effect / σ²_total). In two-way ANOVA, partial ω² estimates σ²_effect / (σ²_effect + σ²_error), excluding the variance of other sources from the denominator. Both have less upward bias than η² as estimators of their population values. Displayed as 0 when the estimate is negative |
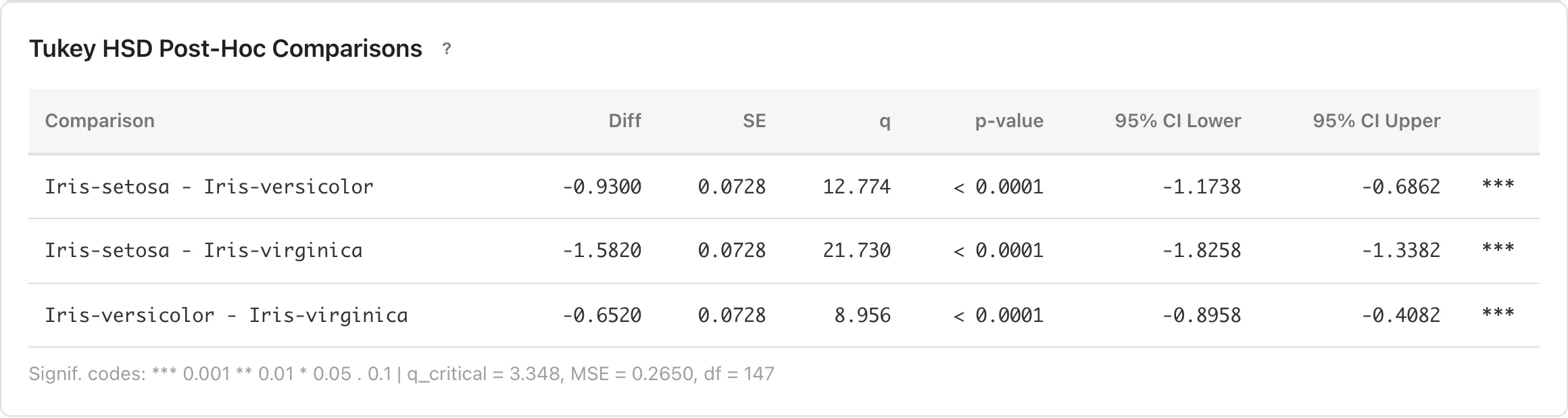
Tukey HSD Post-Hoc Comparisons
The ANOVA table decomposes overall variation among groups, but does not show how large the difference is for each pair. Tukey HSD post-hoc comparisons estimate the mean difference and its simultaneous confidence interval for every pair of groups, allowing you to assess the magnitude and precision of each pairwise difference.
For one-way ANOVA, Tukey HSD is computed automatically. The Tukey-Kramer method is used, which handles unequal group sizes. Tukey HSD is not available for two-way ANOVA.
Tukey HSD constructs simultaneous confidence intervals for all pairwise mean differences. It controls the family-wise error rate, reducing the inflation of false positives compared to running individual t-tests for each pair.
| Column | Description |
|---|---|
| Comparison | The two groups being compared |
| Diff | Difference in means (Group 1 mean − Group 2 mean) |
| SE | Standard error of the difference |
| CI Lower / CI Upper | Simultaneous confidence interval for the mean difference. Adjusted so that all pairwise intervals simultaneously contain the true values with at least the specified confidence level |
The critical value , MSE, and residual degrees of freedom are displayed below the table.
Assumptions
ANOVA assumes the following. Verify that these are reasonable when interpreting results.
- Independence: Observations are independent of each other
- Normality: The response variable follows a normal distribution within each group. When homogeneity of variance holds, ANOVA results become robust to departures from normality as sample sizes increase. This robustness does not extend to cases where variances are unequal
- Homogeneity of variance: The variance is equal across all groups
Assumption Diagnostics
ANOVA assumes normality within each group. Two types of Q-Q plots help assess this assumption.
The pooled residual Q-Q plot compares all residuals against a theoretical normal distribution. Points falling close to the diagonal line suggest approximate normality. Departures such as heavy tails or skewness are visible in the shape of the deviation from the line. Because this plot combines residuals from all groups, it can mask departures that affect only some groups.
The per-group Q-Q plots show the residual distribution within each group separately. These provide a visual check of the normality assumption, since ANOVA assumes normality within each group. When there are more than 12 groups, only the first 12 (in the same order as the Group Statistics table) are displayed.
Homogeneity of variance can be assessed by comparing the SD values in the Group Statistics table. If the standard deviations differ substantially across groups, interpret the ANOVA results with caution. When variances differ systematically across groups, consider using GLM, which can explicitly model the variance structure.
In two-way ANOVA, residuals are computed from the fitted values of the selected model. When the interaction term is included, the model fits a separate mean for each cell, so residuals equal deviations from cell means. When the interaction term is excluded, the main-effects-only model produces different fitted values, and the residuals reflect deviations from those predictions. The choice of model affects both the pooled and per-group Q-Q plots.
Add to Report
Each result section (Group Statistics, ANOVA Table, Assumption Diagnostics, and Pairwise Mean Differences) has an Add to Report button in its header. Click it to add that section to a report. Sections are added independently, so you can send analysis results and diagnostic plots to separate reports.
Elements added to a report retain the original dataset and analysis settings. When the data changes, the results are recomputed.
Error Messages
In two-way ANOVA with the interaction term, every combination of factor levels must have at least one observation. If any cell is empty, an error beginning with "Empty cell detected" is displayed, indicating which combination is missing. Turn off the interaction term or check whether your data has empty cells.
If factor levels have perfect collinearity, the error "The design matrix is rank deficient. This may occur when factor levels have perfect collinearity or insufficient observations." is displayed.
Missing Values
Rows containing missing values are automatically excluded. The number of excluded rows is displayed in the results panel. For two-way ANOVA, rows with missing values in either factor or the response variable are excluded. This is listwise deletion (complete-case analysis). See Missing Data Mechanisms for conditions under which it yields valid estimates.
Related Pages
- Linear Regression -- the ANOVA table in the regression tab tests the overall model fit, while this tab uses categorical factors
Also available as a Markdown file.