ANOVA(分散分析)
ANOVA タブでは、カテゴリ変数で分けたグループ間で応答変数の平均に差があるかを分析します。一元配置と二元配置に対応しています。各観測が独立した群間比較を前提とします。同じ対象を繰り返し測定した反復測定・対応のあるデータには対応していません。その場合は被験者をランダム効果のグループとする GLMM を使います。
基本的な使い方
タブを開く
メニューバーから Analysis > ANOVA... を選択します。
分析の実行
設定パネルで以下を順に設定します。
- Dataset から分析対象のデータセットを選択
- Analysis Type で One-Way または Two-Way を選択
- Factor A (Categorical) にカテゴリ変数を選択
- Response Variable (Numeric) に数値変数を選択
- Run Analysis をクリック
データ形式
データはロング形式で、1行が1つの観測に対応する必要があります。各行に因子の値と応答変数の値が含まれます。ワイド形式のデータは Reshape で変換できます。
一元配置 ANOVA
1つのカテゴリ変数(因子)でグループを分け、グループ間で応答変数の平均に差があるかを分析します。因子が1つの場合に使用します。
統計モデル
は群 の 番目の観測値、 は全体平均、 は群 の効果、 は誤差項です。
群間差の評価
ANOVA は応答変数の全変動を、群間の変動と残差に分解します。分解の結果は SS・df・MS として ANOVA テーブルに表示されます。効果量のうち η² は標本において全変動のうち因子に帰属する割合を示し、ω² は母集団におけるその割合の推定値です。群間差の大きさと推定精度は、Tukey HSD の差の同時信頼区間で読み取れます。Group Statistics の群平均の信頼区間は、各群平均の推定精度を示します。
変数の選択
Factor A (Categorical): グループを分けるカテゴリ変数を選択します。測定尺度が nominal または ordinal の列が候補になります。
Response Variable (Numeric): 分析対象の数値変数を選択します。測定尺度が interval、ratio、または boolean の列が候補になります。
使用例
Iris サンプルデータで、3種の花 Iris-setosa, Iris-versicolor, Iris-virginica の間で sepal_length に差があるかを分析する場合:
- Dataset: Iris
- Analysis Type: One-Way
- Factor A:
species - Response Variable:
sepal_length - Run Analysis をクリック
Confidence Level
Group Statistics の信頼区間と Tukey HSD 事後比較の信頼水準を設定します。90%、95%(デフォルト)、99% から選択します。Tukey HSD の信頼区間の幅は信頼水準に連動します。この設定は二元配置でも表示され、Group Statistics の信頼区間に適用されます。
二元配置 ANOVA
2つのカテゴリ変数(因子)の効果と、その交互作用を分析します。因子が2つの場合に使用します。
統計モデル
交互作用ありの場合:
は因子 A の効果、 は因子 B の効果、 は交互作用です。
追加の設定
Factor B (Categorical): 2つ目のカテゴリ変数を選択します。Factor A とは異なる変数を選びます。
Include interaction term (A x B): 交互作用項をモデルに含めるかを指定します。デフォルトはオンです。2つの因子の効果が互いに独立でない可能性がある場合はオンにします。理論的に交互作用がないことが明確な場合はオフにすると、残差自由度が増え、誤差分散をより精度よく推定できます。
Sum of Squares Type: 平方和の計算方法を選択します。
平方和のタイプ
Type I は因子をモデルに投入した順序に基づいて平方和を計算します。各因子の寄与はそれ以前にモデルに入っている因子に依存します。MIDAS では Factor A、Factor B、交互作用項の順に投入します。Factor A の SS は切片のみのモデルに Factor A を加えたときの残差平方和の減少分であり、Factor B の SS はさらに Factor B を加えたときの残差平方和の減少分です。Factor A と B の割り当てを入れ替えると結果が変わります。
Type III は各因子を最後に投入した場合の平方和を計算します。他の全因子で調整された各因子の寄与を評価します。
均衡データ(全てのセルのサンプルサイズが等しいデータ)では Type I と Type III は同じ結果になります。不均衡データでは Type III が一般的に使用されます。因子の投入順序に結果が依存しないためです。
交互作用項を含む場合の Type III の解釈
MIDAS は treatment coding を使用します。Treatment coding は因子の1つの水準を参照カテゴリ(基準水準)とし、他の水準の効果を参照カテゴリとの差として表現するコーディング方式です。参照カテゴリはアルファベット順で最初の水準です。交互作用項を含む場合、Type III の主効果は treatment coding の参照カテゴリに依存します。たとえば Factor A の水準が A, B, C、Factor B の水準が X, Y の場合、参照カテゴリはアルファベット順で最初の A と X になります。Type III の Factor A の主効果の平方和は、「Factor B が参照水準 X にあるときの Factor A の全水準を除いたモデルと、フルモデルの残差平方和の差」に相当します。均衡データでは全水準にわたる平均的な効果と一致しますが、不均衡データでは一致しない場合があります。
結果の読み方
観測数
結果の先頭に分析に使用した観測数が表示されます。欠損値により除外された行がある場合はその数も表示されます。
Group Statistics
群ごとの記述統計量をまとめたテーブルです。
| 列 | 説明 |
|---|---|
| Group | 群の名前。二元配置では「Factor A の水準 × Factor B の水準」の形式で表示されます |
| N | 観測数 |
| Mean | 平均値 |
| SD | 標準偏差(不偏分散の平方根、分母 n − 1) |
| 95% CI | 群平均の信頼区間([lower, upper] 形式)。ANOVA テーブルのプールされた MSE を使い、mean ± t × √(MSE / n) で計算します(残差自由度の t 分布)。等分散性の仮定に基づいているため、群間で分散が異なる場合は被覆率が名目水準から乖離します。列名の数値と信頼水準は Confidence Level の設定に連動します |
| Min | 最小値 |
| Max | 最大値 |
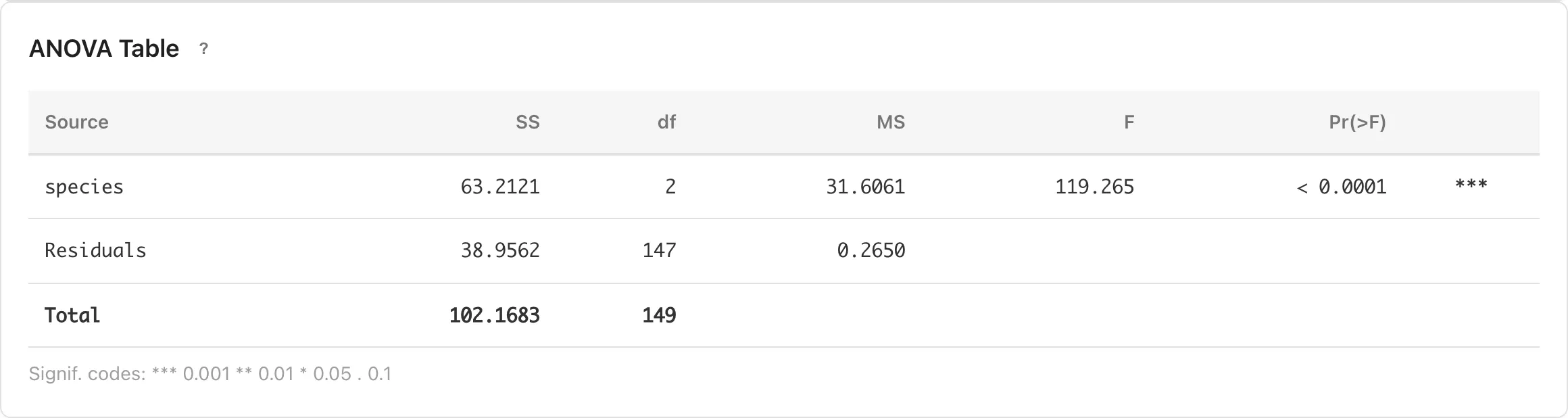
ANOVA Table
分散分析の結果をまとめたテーブルです。応答変数の全分散を、各因子の寄与と残差に分解します。
| 列 | 説明 |
|---|---|
| Source | 変動の要因 |
| SS | 平方和。各要因に帰属する変動の大きさ |
| df | 自由度 |
| MS | 平均平方。SS を df で割った値 |
| η² / partial η² | イータ二乗(一元配置)または偏イータ二乗(二元配置)。SS_effect / (SS_effect + SS_residual) で計算される効果量の指標です。二元配置では分母に他の要因の変動を含まないため、各要因の partial η² の合計が 1 を超えることがあります |
| ω² / partial ω² | オメガ二乗(一元配置)または偏オメガ二乗(二元配置)。一元配置の ω² は (SS_effect − df_effect × MS_residual) / (SS_total + MS_residual)、二元配置の partial ω² は (SS_effect − df_effect × MS_residual) / (SS_effect + (N − df_effect) × MS_residual) で計算されます。一元配置の ω² は母集団における全分散に占める因子の分散の割合 (σ²_effect / σ²_total) の推定量です。二元配置の partial ω² は分母に他の要因の分散を含まない σ²_effect / (σ²_effect + σ²_error) の推定量です。いずれも η² より母集団の値に対するバイアスが小さくなります。推定値が負になる場合は 0 と表示されます |
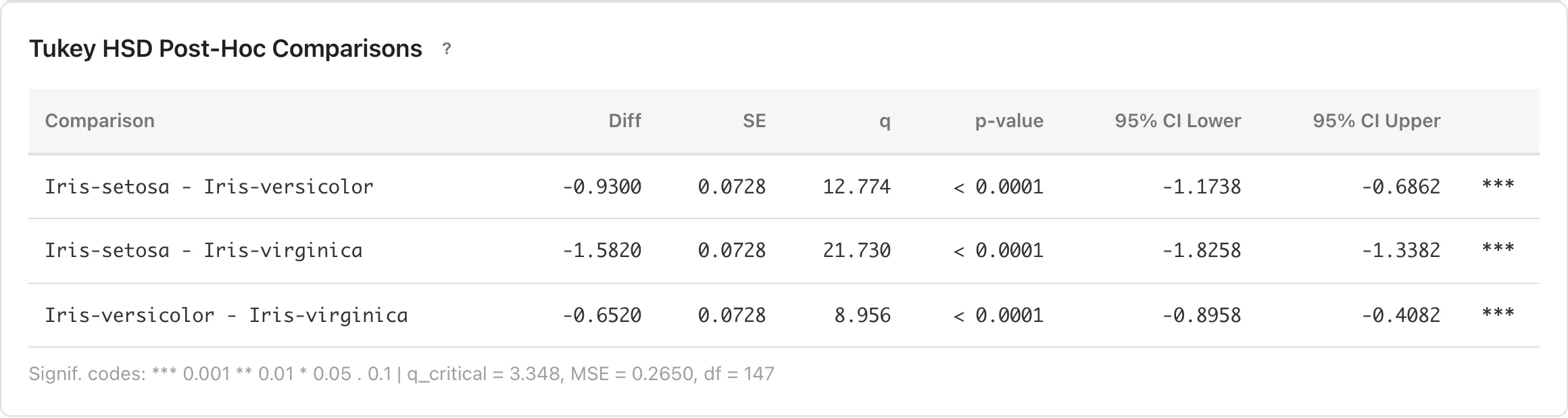
Tukey HSD 事後比較
ANOVA テーブルは群間にどれだけの変動があるかを全体として分解しますが、どの群間にどれだけの差があるかは示しません。Tukey HSD 事後比較は、全ての群のペアについて平均差とその同時信頼区間を推定し、各ペアの差の大きさと推定精度を評価します。
一元配置 ANOVA では Tukey HSD が自動的に計算されます。Tukey-Kramer 法を使用しており、群のサイズが異なる場合にも対応します。二元配置 ANOVA では Tukey HSD は表示されません。
Tukey HSD は全ペアの平均差に対する同時信頼区間を構成します。ファミリーワイズエラー率を制御しているため、個別に t 検定を繰り返す場合と比べ、多重比較による偽陽性の増加を抑えます。
| 列 | 説明 |
|---|---|
| Comparison | 比較する2群の組み合わせ |
| Diff | 平均差。Group 1 の平均 − Group 2 の平均 |
| SE | 平均差の標準誤差 |
| CI Lower / CI Upper | 平均差の同時信頼区間。全てのペアの信頼区間が同時に真の値を含む確率が信頼水準以上になるよう調整された区間 |
テーブルの下に臨界値 、MSE、残差の自由度 df が表示されます。
前提条件
ANOVA は以下を前提としています。結果を解釈する際はこれらが妥当かを確認してください。
- 独立性: 各観測が互いに独立であること
- 正規性: 各群の応答変数が正規分布に従うこと。等分散性が保たれていれば、サンプルサイズの増加に伴い ANOVA の結果は正規性からの乖離に対してロバストになる。等分散性が崩れている場合はこの限りではない
- 等分散性: 各群の分散が等しいこと
Assumption Diagnostics
ANOVA は各群内での正規性を仮定しています。この仮定を評価するために 2 種類の Q-Q プロットを表示します。
プール残差の Q-Q プロット は全残差をまとめて理論的な正規分布と比較します。点が対角線に近いほど正規性の仮定が妥当であることを示します。裾の重さや歪みの方向も視覚的に読み取れます。全群の残差を混合しているため、一部の群だけに存在する分布の偏りを検出しにくいことがあります。
群ごとの Q-Q プロット は各群の残差を個別に表示します。ANOVA は群ごとの正規性を仮定しているため、こちらの方が仮定のより直接的な視覚チェックになります。群数が 12 を超える場合は Group Statistics テーブルと同じ順序で先頭の 12 群のみ表示されます。
等分散性は Group Statistics テーブルの各群の SD を比較して確認できます。群間で SD が大きく異なる場合は注意が必要です。分散が群間で体系的に異なる場合は、分散構造を明示的にモデル化できる GLM の使用を検討してください。
二元配置 ANOVA では、選択したモデルの fitted values から残差を計算します。交互作用項を含む場合、モデルはセルごとに平均を推定するため、残差はセル平均からの偏差と一致します。交互作用項を含まない場合、主効果のみのモデルは異なる fitted values を生成するため、残差はその予測値からの偏差になります。モデルの選択はプール・群ごと両方の Q-Q プロットに影響します。
レポートへの追加
結果の各セクション(Group Statistics、ANOVA Table、Assumption Diagnostics、Pairwise Mean Differences)のヘッダーにある Add to Report ボタンで、そのセクションをレポートに追加できます。セクション単位で独立して追加できるため、分析結果と診断プロットを別々のレポートに振り分けることもできます。
レポートに追加した要素は元のデータセットと分析設定を保持しており、データが更新されると結果も再計算されます。
エラーメッセージ
二元配置 ANOVA で交互作用項を含む場合、因子の水準の全組み合わせに1つ以上の観測が必要です。データがないセルがあると "Empty cell detected" で始まるエラーが表示され、どの水準の組み合わせが空かが示されます。交互作用項をオフにするか、データに空のセルがないか確認してください。
因子の水準間に完全な共線性がある場合などは "The design matrix is rank deficient. This may occur when factor levels have perfect collinearity or insufficient observations." というエラーが表示されます。
欠損値の処理
欠損値を含む行は自動的に除外されます。除外された行数は結果パネルに表示されます。二元配置では、いずれかの因子または応答変数に欠損値を含む行が除外されます。この除外はリストワイズ除去(完全ケース分析)に該当します。妥当な推定を与える条件については欠損データのメカニズムを参照してください。
関連ページ
- Linear Regression -- 回帰分析の ANOVA テーブルとは異なり、このタブでは因子がカテゴリ変数です
このページの Markdown 版もあります。