Generalized Linear Mixed Model(一般化線形混合モデル)
GLMM タブでは、グループ構造を持つデータに対してランダム切片モデル , を実行できます。GLM に変量効果(ランダム効果)を加えた拡張です。数理的な背景はGLMM の基礎を参照してください。
たとえば、複数の学校から生徒のテスト結果を分析する場合、学校ごとの違い(ランダム切片)を考慮しつつ、勉強時間などの固定効果を推定できます。成績に学校内の相関があり、勉強時間が学校間で異なる場合、GLM で学校差を無視すると標準誤差が過小推定され、信頼区間が実際より狭くなります。
基本的な使い方
GLMM を開く
メニューバーから Analysis > Mixed Effects Model (GLMM)... を選択します。
変数の設定
Dataset で分析対象のデータセットを選択します。
Response Variable (Y) で目的変数を選択します。数値型の列のみ選択できます。
Fixed Effects (X) で固定効果の説明変数を選択します。数値型の列のみ選択可能で、カテゴリ変数を使用する場合は事前に Dummy Coding で変換してください。
Group Variable (Random Intercept) でランダム切片のグループ変数を選択します。カテゴリ変数(名義・順序尺度)または文字列型の列が選択できます。
Distribution Family で分布ファミリーを選択します:
| ファミリー | デフォルトリンク | 利用可能なリンク | 用途 |
|---|---|---|---|
| Gaussian (Normal) | Identity | Identity, Log | 連続値 |
| Binomial (Logistic) | Logit | Logit, Probit | 二値データ |
| Poisson (Count) | Log | Log, Identity | カウントデータ |
| Gamma | Inverse | Inverse, Log, Identity | 正の連続値 |
Link Function でリンク関数を選択します。ファミリーに応じたデフォルト(正準リンク)が設定されます。選択可能なリンク関数はファミリーによって異なります(上記テーブルを参照)。
| リンク関数 | 数式 | 説明 |
|---|---|---|
| Identity | 変換なし。Gaussian の正準リンク | |
| Logit | 対数オッズ変換。Binomial の正準リンク | |
| Log | 対数変換。Poisson の正準リンク。 を保証 | |
| Inverse | 逆数変換。Gamma の正準リンク | |
| Probit | 標準正規分布の逆累積分布関数。潜在正規変数モデルに対応 |
正準リンクの数理的な性質は GLM: リンク関数 を参照してください。
Include intercept で切片項の有無を設定します(デフォルト: オン)。
Confidence Level で信頼区間の信頼水準を設定します(デフォルト: 95%、範囲: 50--99.99%)。Fixed Effects テーブルの Lower N% / Upper N% 列に反映されます。保存後に Model Detail タブを開くと同じ入力が表示され、保存値を初期値としてその場で水準を変更できます(モデルに保存された値は変わりません)。
詳細オプション
- Max Iterations: 最適化の最大反復回数(デフォルト: 100)
- Convergence Tolerance: 収束判定の閾値(デフォルト: 1e-6)
分析の実行
Run GLMM をクリックします。推定アルゴリズムはファミリーによって異なります(詳細)。実行中はフォーム下部に進捗バーと推定のステージが表示されます。
結果の見方
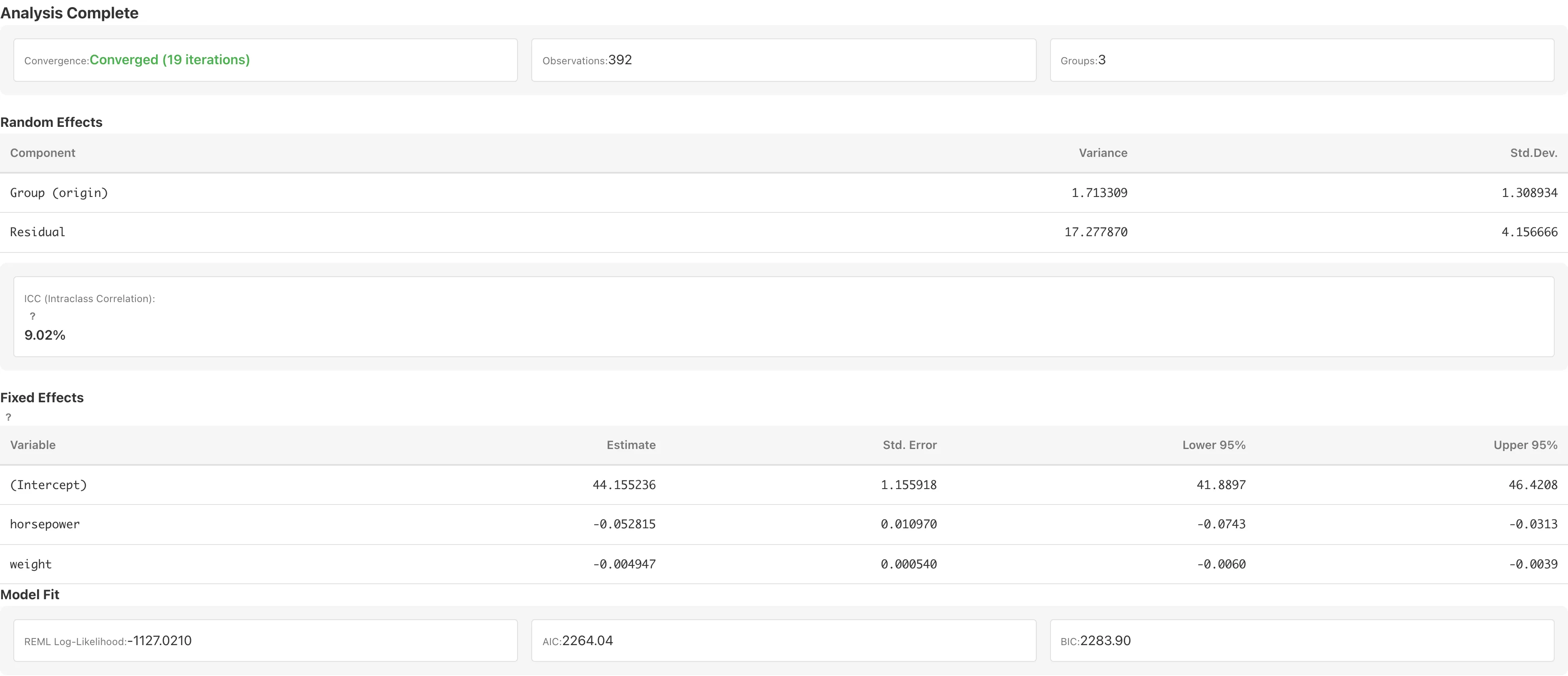
Random Effects
変量効果の分散成分を表示します。
| 列 | 説明 |
|---|---|
| Component | 分散成分の名前。Group (変数名) はグループ変数の分散、Residual は残差分散を表します |
| Variance | 分散の推定値。グループ変数では 、残差では です |
| Std.Dev. | 分散の平方根 |
Poisson と Binomial ファミリーでは分散パラメータが 固定のため、Residual 行は表示されません。
残差分散 は分布ファミリーの性質(Gaussian: 、Gamma: )であり、リンク関数には依存しません。リンク関数は線形予測子からの fitted values の計算方法を決め、その fitted values を通じてファミリー固有の計算式に基づく診断残差(deviance・Pearson)に影響します。
ICC(級内相関係数)
ICC は説明されない分散のうち、グループ間の違いが占める割合です()。MIDAS は に理論的根拠がある以下の family+link の組み合わせでのみ ICC を計算します:
| ファミリー | リンク | |
|---|---|---|
| Gaussian | identity | REML 推定値 |
| Binomial | logit | (閾値モデル) |
| Binomial | probit | (閾値モデル) |
それ以外の組み合わせ — Poisson(全リンク)、Gamma(全リンク)、Gaussian + log — では、理論的に根拠のある残差分散が存在しないため、ICC の値の代わりに N/A (ICC not defined) と表示されます。詳細は GLMM の基礎 を参照してください。
ICC の解釈はデータの性質や研究目的に依存します。グループサイズも考慮する必要があります(GLM との使い分けを参照)。Binomial モデルの ICC は確率尺度ではなく潜在(リンク)尺度で計算されます(GLMM の基礎を参照)。
Fixed Effects
固定効果の係数テーブルです。
| 列 | 説明 |
|---|---|
| Variable | 変数名 |
| Estimate | 回帰係数 |
| Std. Error | 標準誤差。Gaussian + identity では Woodbury 公式で を計算します。それ以外の組み合わせでは PIRLS 収束時の作業重み行列に基づく近似です |
| Lower N% / Upper N% | Wald に基づく信頼区間の下限・上限です。N は選択した信頼水準に応じて変わります |
リンク関数が logit または log の場合、以下の列が追加されます。
| 列 | 説明 |
|---|---|
| OR / IRR / exp(Est.) | Estimate の指数変換 です。logit リンクではオッズ比(OR)、log リンク + Poisson では発生率比(IRR)、それ以外の log リンクでは exp(Est.) と表示されます |
| exp(Lower N%) / exp(Upper N%) | 信頼区間の指数変換です |
係数の解釈は GLM と同じです(リンク関数のスケール)。詳しくは GLM の係数の解釈 を参照してください。
信頼区間は標準正規分布に基づく Wald 近似で計算されます。グループ数が少ない場合は信頼区間の幅が過小評価される傾向があります。詳細は GLMM の基礎: 固定効果の推測と正規近似 を参照してください。
Model Fit
| 指標 | 説明 |
|---|---|
| REML Log-Likelihood / Log-Likelihood (Laplace) | 対数尤度(Gaussian + identity: REML、それ以外の組み合わせ: Laplace 近似) |
Gaussian + identity では定数項 (: 観測数、: 切片を含む固定効果パラメータ数)を含む REML 対数尤度が表示されます。それ以外の組み合わせでは Laplace 近似の周辺対数尤度が表示されます。
AIC () と BIC () も表示されます。 は固定効果の数と分散成分の数の合計です。混合モデルの AIC/BIC を使う際は GLMM の基礎: AIC/BIC の制限 に記載された制約に注意してください。REML 対数尤度(Gaussian + identity)に基づく AIC は固定効果の構造が同一のモデル間でしか比較できません。Laplace 近似の対数尤度(それ以外の組み合わせ)では近似誤差が情報量規準にも伝播します。ファミリーまたはリンクが異なるモデルどうしでは、対数尤度の基準(REML / Laplace)と尺度が変わるため、AIC・BIC・対数尤度を比較できません。
BLUP(変量効果の予測値)

各グループのランダム切片の予測値(BLUP)を表示します。
| 列 | 説明 |
|---|---|
| Group | グループ変数の値 |
| Random Intercept | ランダム切片の予測値。グループサイズが小さいほど全体平均(0)に向かって縮小されます(縮小推定の詳細) |
| Std. Error | 予測値の標準誤差。条件付き分散の平方根で、グループサイズが小さいほど大きくなります |
| Rank | Random Intercept の降順の順位 |
Gaussian + identity 以外の組み合わせでは、変量効果は事後分布の条件付きモードとして推定されます。Gaussian + identity の BLUP と同様に縮小推定の性質を持ちますが、厳密には BLUP ではありません。この場合の Std. Error は事後分布に基づく標準誤差であり、予測区間の構成にそのまま使えるとは限りません。
モデルの保存と診断
Model Name にモデル名を入力し Save Model をクリックすると、モデルがプロジェクトに保存されます。保存時に診断用の派生データセットが自動生成されます。
| 列名 | 内容 |
|---|---|
fitted_values | 予測値(固定効果 + ランダム効果) |
deviance_residuals | Deviance 残差 |
pearson_residuals | Pearson 残差 |
group_random_effect | グループのランダム切片(BLUP) |
Gaussian + identity では deviance 残差と Pearson 残差はともに生の残差 に一致し、deviance_residuals と pearson_residuals は同じ値になります。
保存後、View Model Details と View Diagnostics ボタンが使えるようになります。Model Detail には固定効果の係数テーブルと BLUP テーブル(グループごとのランダム切片推定値)が表示されます。BLUP テーブルはデフォルトで 50 行まで表示され、グループ数が多い場合は Show all N rows ボタン(N は総グループ数)で全件を展開できます。Add to Report ボタンから係数テーブル・BLUP テーブルをレポートに追加できます。
注意事項
現在の制約
GLMM の現在の実装はランダム切片モデル()のみです。ランダム傾き()や交差ランダム効果には対応していません。
GLM タブでは Negative Binomial ファミリーが利用できますが、GLMM タブでは対応していません。
GLM との使い分け
ICC が小さければ、グループ構造を無視して GLM で分析しても結果はほぼ変わりません。影響の大きさは ICC だけでなくグループサイズにも依存します。設計効果 が目安になります(GLMM の基礎を参照)。ICC が大きい場合、GLM では観測間の独立性の仮定に反するため、標準誤差が過小推定されます。GLMM はグループ内の相関を明示的にモデル化することで正しい推論を可能にします。
欠損値の自動除外
欠損値、非数値、無限大を含む行は自動的に除外されます。結果の Observations は除外後の観測数です。この除外はリストワイズ除去に該当します。妥当な推定を与える条件については 欠損データのメカニズム を参照してください。
収束の問題
収束しない場合は以下を確認してください:
- Max Iterations を増やす(100 → 500)
- Convergence Tolerance を緩める(1e-6 → 1e-4)
- グループ数が極端に少ない(2〜3)場合、分散成分の推定が不安定になることがあります
- 説明変数のスケールが大きく異なる場合は標準化を検討してください(内部的にスケーリングは行われていますが、極端なケースでは初期値の GLM 推定が失敗する可能性があります)
Singular Fit
ランダム効果の分散推定がゼロまたはゼロ付近になった場合、"Singular fit" 警告が表示されます。推定値がパラメータ空間の境界に達した状態です。考えられる原因:
- グルーピング変数が目的変数の変動をほとんど説明していない
- サンプルサイズまたはグループ数がグループレベルの変動と残差変動を分離するには不十分である
Singular fit が発生した場合、ICC や分散成分の推定値は慎重に解釈する必要があります。固定効果のみのモデル(GLM)の方が適切な場合があります。
See also
このページの Markdown 版もあります。