Data Table
Data Table タブはデータセットの内容を表形式で表示し、フィルタやソートでデータを調べられます。
基本的な使い方 もご覧ください。
フィルタ機能
フィルタ式を入力して、条件に合う行だけを表示できます。フィルタは Statistics タブにも反映され、フィルタ後のデータのみで統計量を計算します。Graph Builder には独自のフィルタ設定があり、Data Table のフィルタは反映されません。その他の分析タブもフィルタ前の全データを使用します。
基本的な使い方
- Data Table タブ上部のフィルタ入力欄に式を入力する
- 入力内容が有効なフィルタ式であれば、入力と同時に自動的に適用される
- 条件に合う行だけが表示される。行が絞り込まれた場合は、フィルタ入力欄の下に該当行数(Showing N of M rows)が表示される
構文エラーや存在しない列名など式に誤りがある場合は、入力欄が赤く表示されます。エラー内容は入力欄にマウスカーソルを重ねると確認できます。誤った式は適用されず、直前の有効なフィルタが維持されます。
フィルタ式の書き方
フィルタ式は SQL ライクな構文で、比較演算子、LIKE、IN、BETWEEN などが使えます。SQL の知識がなくても、以下の説明と例を参考にそのまま入力できます。キーワード(AND、OR、LIKE、IN など)は大文字・小文字を区別しません。文字列はシングルクォートで囲みます。文字列中にシングルクォートを含める場合は name = 'O''Brien' のように 2 つ重ねて書きます。列名にスペースや特殊文字が含まれる場合はダブルクォートで囲みます。
比較演算子
| 演算子 | 意味 | 例 |
|---|---|---|
= | 等しい | species = 'Adelie' |
!= | 等しくない | species != 'Adelie' |
> | より大きい | age > 30 |
>= | 以上 | age >= 30 |
< | より小さい | age < 30 |
<= | 以下 | age <= 30 |
数値リテラルには負の数も書けます(例: temperature > -5)。
パターンマッチ演算子
| 演算子 | 意味 | 例 |
|---|---|---|
LIKE | パターンに一致(大文字小文字区別) | name LIKE '%田%' |
ILIKE | パターンに一致(大文字小文字無視) | name ILIKE '%Smith%' |
NOT LIKE | パターンに一致しない(大文字小文字区別) | name NOT LIKE '%test%' |
NOT ILIKE | パターンに一致しない(大文字小文字無視) | name NOT ILIKE '%test%' |
大文字・小文字の区別は半角と全角の英字に適用されます。ひらがなとカタカナ、全角と半角の文字は、LIKE と ILIKE のどちらでも区別されます。
パターンの書き方:
%は任意の文字列(0文字以上)を表します_は任意の1文字を表します
% や _ をエスケープして文字そのものとして検索する構文はありません。これらの文字を含む値を正確に絞り込むには、= 演算子で完全一致を指定してください。
例:
name LIKE '%田%'- 「田」を含むname LIKE '山%'- 「山」で始まるname LIKE '%郎'- 「郎」で終わるemail LIKE '%@example.com'- @example.com で終わる
論理演算子
| 演算子 | 意味 | 例 |
|---|---|---|
and | かつ | age > 30 and sex = 'male' |
or | または | species = 'Adelie' or species = 'Gentoo' |
() | グループ化 | (age > 30 or salary > 50000) and active = true |
集合・範囲演算子
| 演算子 | 意味 | 例 |
|---|---|---|
IN (...) | 値のリストに含まれる | species IN ('Adelie', 'Chinstrap') |
NOT IN (...) | 値のリストに含まれない | status NOT IN ('deleted', 'archived') |
BETWEEN ... AND ... | 範囲内(両端含む) | age BETWEEN 20 AND 30 |
NOT BETWEEN ... AND ... | 範囲外 | age NOT BETWEEN 20 AND 30 |
否定演算子
| 演算子 | 意味 | 例 |
|---|---|---|
NOT (...) | 条件の否定 | NOT (status = 'deleted') |
NULL 判定と真偽値
| 構文 | 意味 | 例 |
|---|---|---|
IS NULL | 欠損値 | bill_length_mm IS NULL |
IS NOT NULL | 欠損値でない | bill_length_mm IS NOT NULL |
true / false | 真偽値 | active = true |
列名にスペースや特殊文字が含まれる場合
列名をダブルクォートで囲みます:
"Body Mass (g)" > 4000
フィルタの例
数値の条件:
body_mass_g > 4000
文字列の条件(シングルクォートで囲む):
species = 'Chinstrap'
複数条件の組み合わせ:
species = 'Adelie' and body_mass_g > 3500
欠損値を除外:
bill_length_mm IS NOT NULL
パターンマッチ(部分一致):
island LIKE '%Dream%'
複数の値に一致:
species IN ('Adelie', 'Gentoo')
範囲指定:
body_mass_g BETWEEN 3500 AND 4500
日付の条件(YYYY-MM-DD 形式でシングルクォートで囲む):
date_col >= '2024-01-01' and date_col < '2025-01-01'
たとえば species IN ('Adelie', 'Gentoo') でフィルタすると、該当する行だけが表示されます。
フィルタ結果をデータセットとして保存する
フィルタを適用すると、フィルタ入力欄の横に Save Filtered Data ボタンが表示されます。クリックするとダイアログが開き、名前を付けてフィルタ結果を 派生データセット として保存できます。保存したデータセットは新しいタブで開きます。
ソート機能
列ヘッダーのソートボタン(⬍)をクリックすると、その列でデータをソートできます。
単一列ソート
- 1回クリック: 昇順(▲)
- 2回クリック: 降順(▼)
- 3回クリック: ソート解除
複数列ソート
Ctrl/Cmd を押しながらクリックすると、複数列でソートできます。
- Ctrl/Cmd+クリックした順にソート条件を追加します(昇順)
- 同じ列を再度 Ctrl/Cmd+クリックすると降順に変わります
- さらに同じ列を Ctrl/Cmd+クリックするとソートを解除します
複数列ソート時は、ソートボタンに優先順位の番号が表示されます(▲1、▼2 など)。ソートを解除すると、残りの列の優先順位番号は詰め直されます。Ctrl/Cmd を押さずにいずれかの列ヘッダーをクリックすると、複数列ソートは解除され、その列の単一列ソートに切り替わります。
行の選択
Data Table で行を選択すると、他のタブ(Statistics、Graph Builder など)と選択状態が連動します。
選択方法
- 単一行: 行をクリック
- 範囲選択: Shift キーを押しながらクリック
- 追加選択: Ctrl/Cmd を押しながらクリック
- 行選択の解除: Selected Rows タブの Clear rows ボタンをクリック
選択した行は Statistics や Graph Builder のグラフ上でハイライト表示されます。行選択は統計量の計算には影響しません。統計量の計算対象を絞り込むには フィルタ を使います。タブ間の連動や選択行の保存については 行の選択 を参照してください。
データセットの操作
メタデータの確認
データセット名の横にある ⓘ ボタンをクリックすると、データセットの基本情報(データセット名、タイプ、行数、列数)を確認できます。
列のコンテキストメニュー
列ヘッダーを右クリックするとコンテキストメニューが開きます。
- Edit Column Name: 列名を変更します。
- Edit Scale of Measurement: 測定尺度を変更します。測定尺度は Statistics タブで表示される統計量や Graph Builder で選べるグラフの種類に影響します。
- Convert Column Types...: 列のデータ型を変換するタブを開きます。詳しくは 列の型変換 をご覧ください。
- Normalize Variants...: 文字列または enum 列で表示されます。大文字小文字や空白の違いなどの表記揺れをまとめて修正するタブを開きます。
- Number Format...: 数値列(float64 または int64)の表示形式を設定します。固定小数点、カンマ区切り、有効数字などのプリセットから選べます。Settings > Display で設定したデフォルトより優先されます。フォーマットは設定した Data Table タブの表示にのみ適用され、エクスポートされる CSV/TSV/JSON は元の値のまま出力されます。
- Display as Link...: 列の値を URL テンプレートに埋め込み、リンクとして表示します。リンクが描画されるのは、データの出所が信頼済みの場合だけです。URL から読み込んだデータでは、取得元 URL を Settings の Trusted URLs に登録すると有効になります。リンク表示を設定した列では、この項目は Remove Link Display に変わります。
デフォルトの数値フォーマットは Settings > Display で設定でき、データテーブルと SQL Editor プレビューの表示に適用されます。プリセットから選択するか、Python 互換の format spec 構文(例: ,.2f でカンマ区切り + 小数点以下 2 桁、.4g で有効数字 4 桁)を直接入力できます。
テーブルメニュー
テーブル右上のメニューボタン(⋮)からデータセットを操作できます。
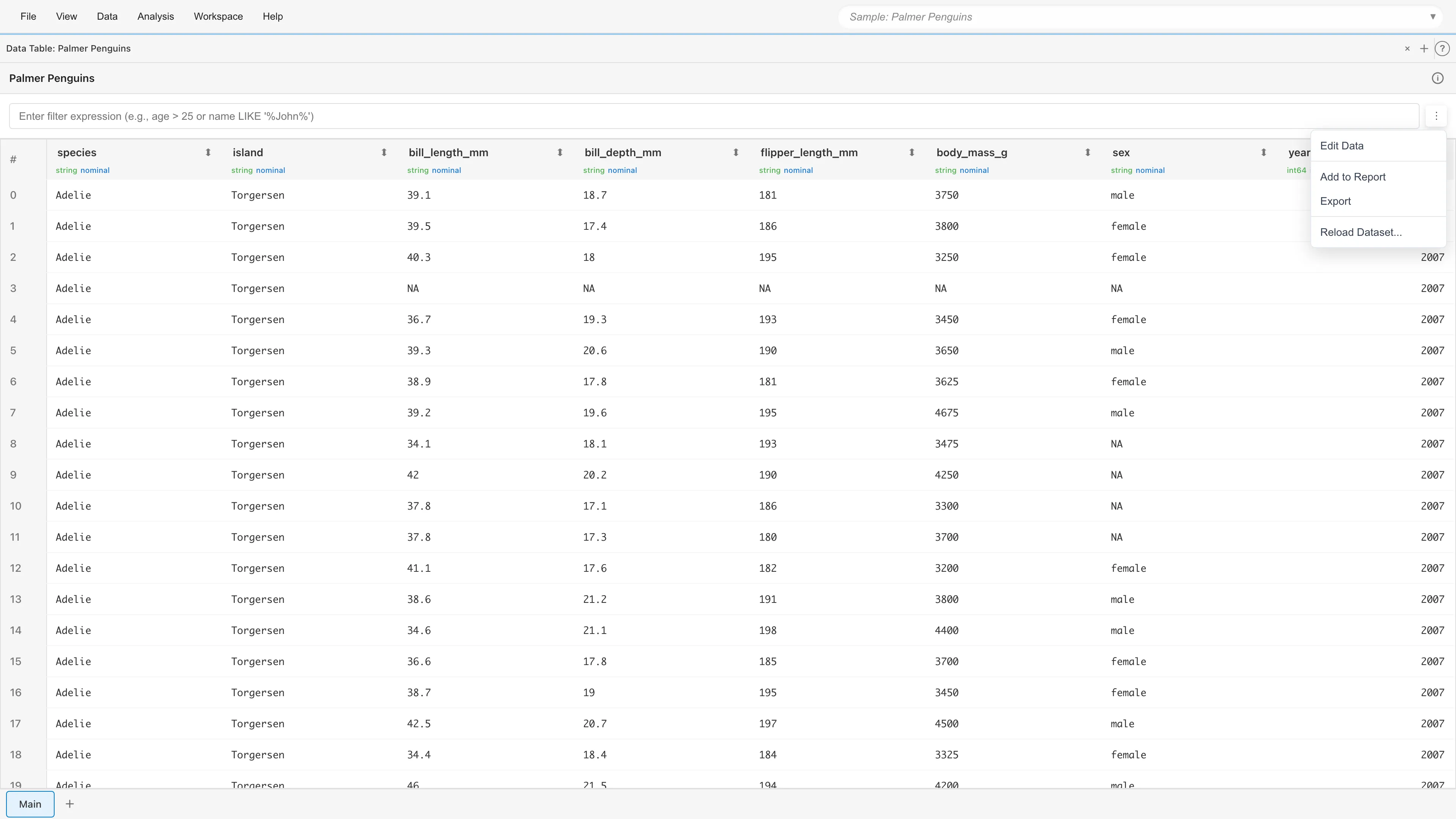
- Edit Data: セルの値の修正、行の追加・削除ができます(Primary データセットのみ)
- Add to Report: テーブルをレポートに追加します
- Export: データをエクスポートします。詳細はデータのエクスポートを参照
- View SQL Query: 元の SQL クエリを確認します(派生データセットのみ)
- Materialize: クエリ結果をプロジェクトファイル(MDS)に保存します(派生データセットのみ)。デフォルトではプロジェクトを開くたびにクエリが再実行されますが、Materialize を有効にすると結果を MDS ファイルに含めます。MDS ファイルのサイズが増えるため、行数の少ない集計結果などに向いています。
- Reload Dataset...: 元のファイルまたは URL からデータを再読み込みします。ダイアログが開き、CSV、TSV、テキストファイルを選択して読み込みます。URL から読み込んだデータセットでは、ダイアログの Reload from URL ボタンで元の URL から再取得できます。行数の変更は問題ありませんが、列構造が元のデータセットと一致する必要があります。具体的には、列数、列名、列の順番、データ型がすべて一致していなければなりません。一致しない場合はエラーメッセージに差分の詳細(どの列名や型が異なるか)が表示され、データセットは更新されません。列の追加・削除などで列構造が変わった場合は、新しいデータセットとして インポート してください。リロードすると除外行と行コメントはすべて消去されます。リロードに成功すると、依存する派生データセットも自動的に再計算されます。派生データセット ではこの項目は Reload Source Dataset... と表示され、元になっている Primary データセットをリロードします。ソースの Primary データセットが複数ある場合は、リロード対象を選択するダイアログが先に開きます
行番号列
左端の列は行番号を表示します。この行番号は元データの順序を示し、フィルタやソートを適用しても変わりません。
データのエクスポート
テーブルメニューの Export から、データセットを CSV、TSV、JSON 形式でエクスポートできます。フィルタ条件に合致する行のみが、現在のソート順でエクスポートされます。全データをエクスポートするには、フィルタを解除してください。行番号列はエクスポートに含まれません。
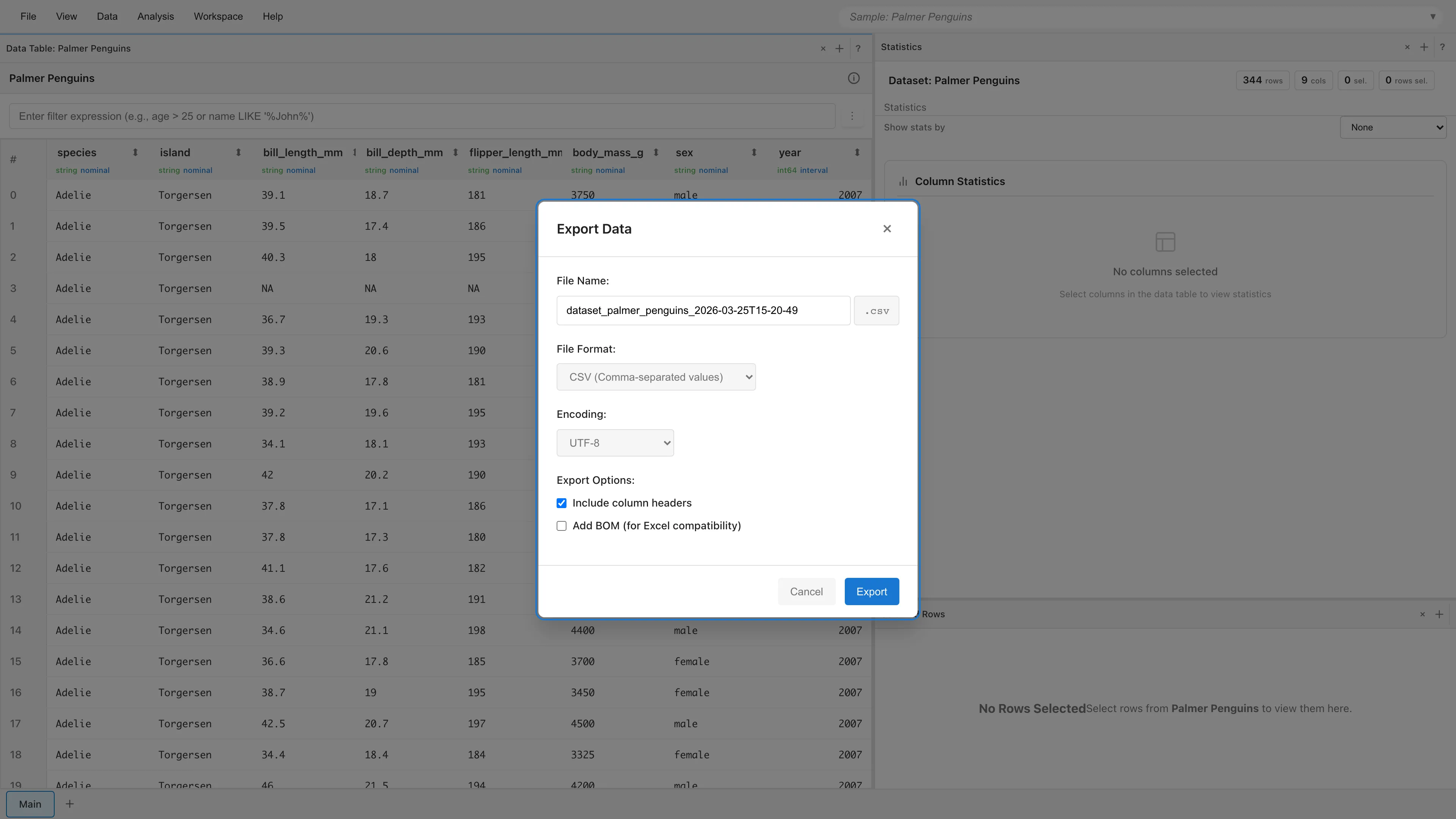
File Name - 出力ファイル名を指定します。入力した名前に、選択した形式の拡張子を付けたファイルがダウンロードされます。拡張子は入力欄の右に表示されます。初期値が入っていますが、自由に書き換えられます。
File Format - 出力形式を選択します。
| 形式 | 説明 |
|---|---|
| CSV | カンマ区切り。表計算ソフトや他のツールで広く使える形式です |
| TSV | タブ区切り。データにカンマが含まれる場合に便利です |
| JSON | オブジェクトの配列形式。プログラムから直接読み込めます |
Encoding - 文字エンコーディングを選択します。CSV と TSV で有効です。JSON は常に UTF-8 です。
| エンコーディング | 用途 |
|---|---|
| UTF-8 | 標準的なエンコーディング。多くのツールで対応しています |
| Shift-JIS (CP932) | 日本語環境の Excel で文字化けなく開けます |
| EUC-JP | 一部の Unix 系ツールで使用されるエンコーディングです |
Shift-JIS や EUC-JP を選択してエクスポートするとき、データ中にそのエンコーディングで表現できない文字(絵文字、一部のアクセント付き文字など)が含まれていると、警告ダイアログが表示されます。Export anyway でそのまま続行するか、Cancel でエクスポートを中止できます。UTF-8 でエクスポートし直すには、中止してから Encoding を変更します。続行した場合、表現できない文字は HTML 文字参照(é のような形式)に置き換わります。
Add BOM - UTF-8 選択時に BOM を付加します。Excel で UTF-8 の CSV を開くときに文字化けを防ぎます。
Include column headers - 先頭行に列名を出力します。CSV と TSV で有効です。
Export selected rows only - 行を選択 している場合に表示されます。チェックすると、選択した行のみをエクスポートします。選択した行は現在のソート順ではなく、元データの行番号順でエクスポートされます。
欠損値の扱い
欠損値は CSV と TSV では空フィールドとして出力されます。JSON では null リテラルとして出力されます。
プロジェクト保存時の状態
フィルタ式とソート順はプロジェクトファイル(MDS)に保存されます。プロジェクトを再度開くと、前回のフィルタとソートが復元されます。行の選択状態は保存されません。
Next steps
- 基本統計量 - 選択した列の統計量を確認
- グラフの作成 - データをグラフで可視化
- SQL Editor によるデータ加工 - SQL でデータを加工
See also
- データの準備と読み込み - データ型と測定尺度について
このページの Markdown 版もあります。