Principal Component Analysis(主成分分析)
PCA タブでは、主成分分析(Principal Component Analysis)を実行できます。PCA は多数の変数を、分散が大きい方向から順に並んだ少数の合成変数(主成分)に要約する手法です。変数間の相関構造を把握したり、データの次元を削減する用途で使います。PCA は因子分析(factor analysis)とは別の手法です。PCA は観測変数の分散をできるだけ保つ合成変数を構成し、因子分析は観測変数の背後に潜在因子を仮定して推定します。MIDAS に因子分析の機能はありません。
MIDAS の PCA は共分散行列の固有値分解に基づいて主成分を算出します。
基本的な使い方
PCA タブを開く
メニューバーから Analysis > Principal Component Analysis... を選択すると、新しい PCA タブが開きます。
変数の設定
Dataset で分析対象のデータセットを選択します。
Variables for PCA で主成分分析に使用する変数を選択します。数値型の列のうち測定尺度が間隔尺度または比率尺度のものと、boolean 型の列を選択できます。boolean 列の値は 0/1 として扱われます。それ以外の列はグレーアウト表示され、変換が必要な旨のツールチップが表示されます。最低2変数が必要です。
名義尺度のカテゴリ変数は Dummy Coding で事前にダミー変数に変換してください。リッカート尺度のような順序尺度の列を、カテゴリ間の間隔が等しいとみなして連続量として扱う場合は、測定尺度を間隔尺度に変更します。数値型の列は Data Table で列ヘッダーを右クリックし、Edit Scale of Measurement から尺度を変更できます。文字列型や Enum 型の列は、先に 列の型変換 で数値型に変換してください。間隔を等しいとみなせるかは分析者の判断です。詳細は データ型と測定尺度 を参照してください。
Preprocessing で前処理方法を選択します。
| 選択肢 | 処理内容 |
|---|---|
| Standardize (z-score) | 各変数から平均を引き、標準偏差で割る(デフォルト) |
| Center only | 各変数から平均を引く |
| None | 変数の変換を行わない |
変数間でスケール(単位や値の範囲)が異なる場合は Standardize を選択してください。スケールが異なるまま PCA を実行すると、値の範囲が大きい変数が主成分を支配します。すべての変数が同じ単位・同程度のスケールであれば Center only や None でも構いません。
どの前処理を選んでも、共分散行列の計算と主成分得点の算出では内部でデータの平均が引かれます。このため None を選んだ場合も変数のスケールは変わりませんが、固有値・負荷量・主成分得点は Center only と同一になります。Standardize を選ぶと、負荷量と寄与率は相関行列に基づく PCA と一致します。標準化では で割る標準偏差を、共分散行列の計算では で割る不偏推定を使うため、固有値は相関行列の固有値の 倍になります。Center only と None は元のスケールでの共分散行列を使います。
設定が完了したら Run PCA ボタンをクリックします。
結果の見方
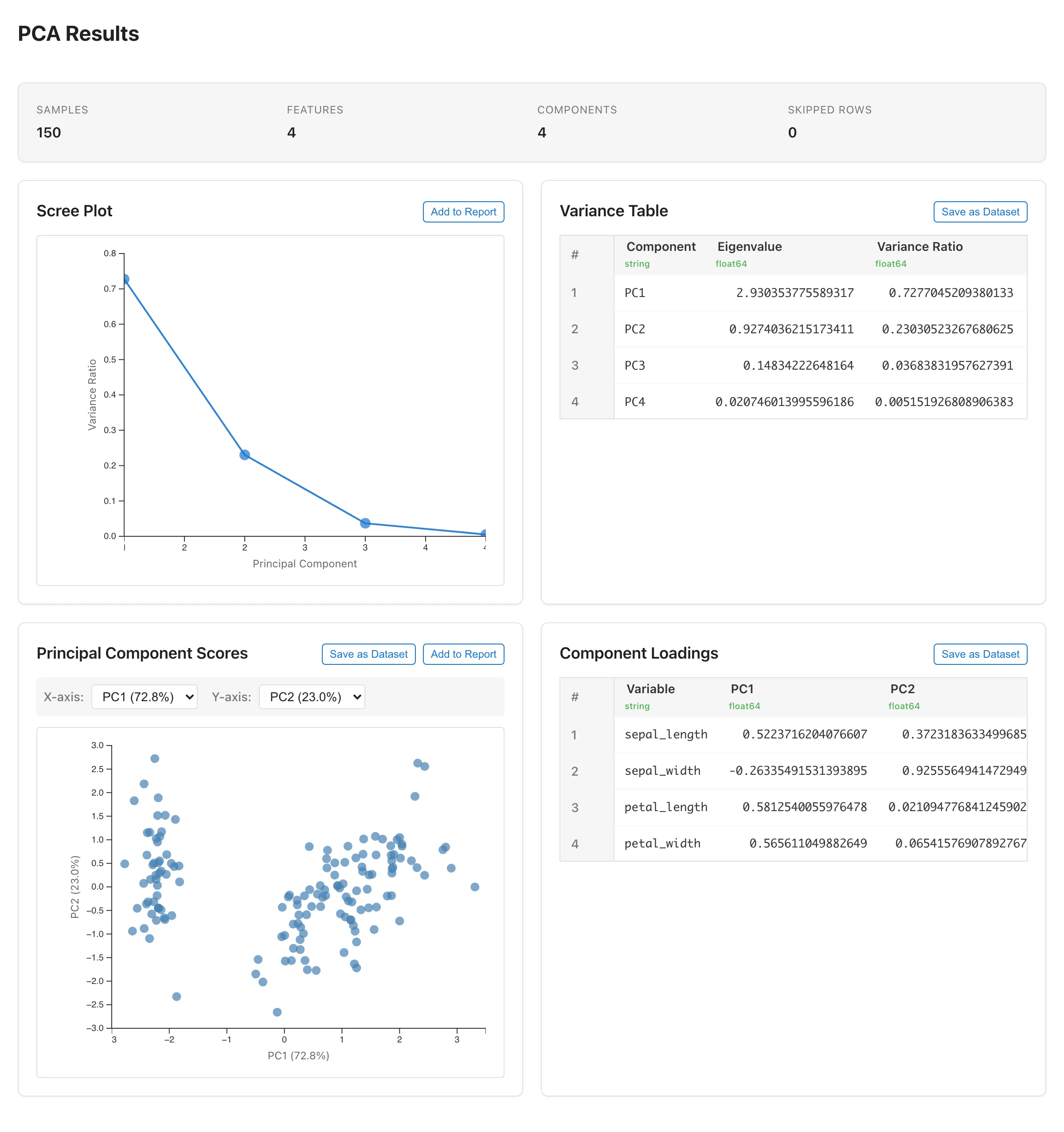
Summary(基本情報)
分析の概要を表示します。
| 項目 | 説明 |
|---|---|
| Samples | 分析に使用した行数 |
| Variables | 選択した変数の数 |
| Components | 抽出された主成分の数(変数の数と同じ) |
| Skipped Rows | 欠損値や無効な値で除外された行数 |
Scree Plot(スクリープロット)
各主成分の寄与率(Variance Ratio)を折れ線グラフで表示します。横軸が主成分番号、縦軸が寄与率(%)です。
寄与率の減り方が緩やかになる「肘」の位置が、成分数を決める目安の一つです。肘より前の、寄与率が急に減っている範囲の成分を残すという読み方が一般的です。Variance Table の累積寄与率(Cumulative)と合わせて判断してください。肘の位置は目視判断であり、明確な肘が現れない場合もあります。
Add to Report ボタンでレポートに追加できます。
Variance Table(寄与率テーブル)
各主成分の固有値と寄与率を表形式で表示します。
| 列 | 説明 |
|---|---|
| Component | 主成分番号(PC1, PC2, ...) |
| Eigenvalue | 固有値(その主成分が説明する分散の量) |
| Variance Ratio | 寄与率(全固有値の和に対する割合) |
| Cumulative | 累積寄与率 |
Save as Dataset ボタンでデータセットとして保存できます。保存後は Data Table タブで開きます。
Principal Component Scores(主成分得点の散布図)
主成分が2つ以上ある場合に表示されます。各観測値の主成分得点を2次元の散布図にプロットします。
X 軸と Y 軸のドロップダウンで表示する主成分を切り替えられます。各選択肢には寄与率が併記されます(例: "PC1 (45.2%)")。デフォルトは X = PC1、Y = PC2 です。
Save as Dataset で全主成分の得点をデータセットとして保存できます。保存した得点は他の分析タブ(散布図、回帰分析など)の入力データとして使用できます。Add to Report でレポートに追加できます。
Component Loadings(成分負荷量)
主成分が2つ以上ある場合に表示されます。各変数が各主成分にどれだけ寄与しているかを表形式で表示します。
| 列 | 説明 |
|---|---|
| Variable | 元の変数名 |
| PC1, PC2, ... | 各主成分に対する負荷量 |
MIDAS が表示する負荷量は固有ベクトルの成分(主成分を構成する各変数の重み)です。変数と主成分の相関係数ではありません。各固有ベクトルのノルムは 1 に正規化されているため、個々の成分は -1 から 1 の範囲に収まります。負荷量の絶対値が大きい変数ほど、その主成分を強く特徴づけています。目安として、すべての変数が均等に寄与する場合、各負荷量の絶対値は ( は変数の数)になります。これを明確に上回る変数がその主成分を特徴づけていると読み取れます。符号は主成分との正負の関係を表します。主成分の意味は、その主成分への負荷量の絶対値が大きい変数を確認し、それらの変数に共通する内容から読み取ります。
Save as Dataset でデータセットとして保存できます。
注意事項
欠損値・無効値の自動除外
欠損値(null)、非数値、無限大を含む行は自動的に除外します。除外した行数は Summary に表示します。この除外はリストワイズ除去に該当します。変数が多い場合、1変数でも欠損があると行全体が除外されるため、使用される行数が大きく減る場合があります。除外後に残った行が元のデータを代表しない場合、共分散行列の推定に偏りが生じ、そこから計算される主成分の向きや寄与率も影響を受けます。除外が結果に与える影響については 欠損データのメカニズム を参照してください。
サンプル数と推定の安定性
サンプル数を 、変数の数を とすると、中心化したデータから計算する共分散行列のランクは最大で です。 の場合、超えた分の主成分の固有値は 0 になります。サンプル数が変数の数に対して少ないほど、固有値と負荷量の標本変動が大きくなります。欠損値の除外で使用される行数が減ることがあるため、Summary の Samples で分析に使われた行数を確認してください。
固有ベクトルの符号
固有ベクトルの符号には不定性があります( が固有ベクトルなら も固有ベクトル)。MIDAS では各主成分の負荷量のうち絶対値が最大の要素が正になるように符号を統一しています。主成分得点は符号統一後の固有ベクトルから計算されるため、得点の符号も負荷量と連動します。
成分数
MIDAS は変数の数と同じ数の主成分を抽出します。成分数の自動選択は行いません。Scree Plot と Variance Table を参考に、分析の目的に応じて必要な成分数を判断してください。
See also
- 基本統計量 - 変数ごとの分布を確認する
- 線形回帰分析 - 特定の応答変数に対する説明変数の効果を分析する
- ダミーコーディング - カテゴリ変数を数値に変換する
- 欠損データのメカニズム - リストワイズ除去が妥当な条件
- レポート - グラフや統計結果をまとめる
このページの Markdown 版もあります。