SQL Editor
SQL を使ってデータのフィルタリング、集計、結合ができます。
概要
SQL Editor は MIDAS 内のデータセットに対して SQL クエリを実行し、結果を新しいデータセット(派生データセット)として保存できる機能です。複数のデータセットを結合したり、複雑な条件でフィルタリングしたりする場合に便利です。
基本的な使い方
SQL Editor を開く
メニューバーから Data > SQL Query Editor を選択すると、新しい SQL Editor タブが開きます。
クエリの実行
エディタに SQL クエリを入力し、Execute Query ボタンをクリックするか、Cmd/Ctrl+Enter を押すとクエリが実行されます。
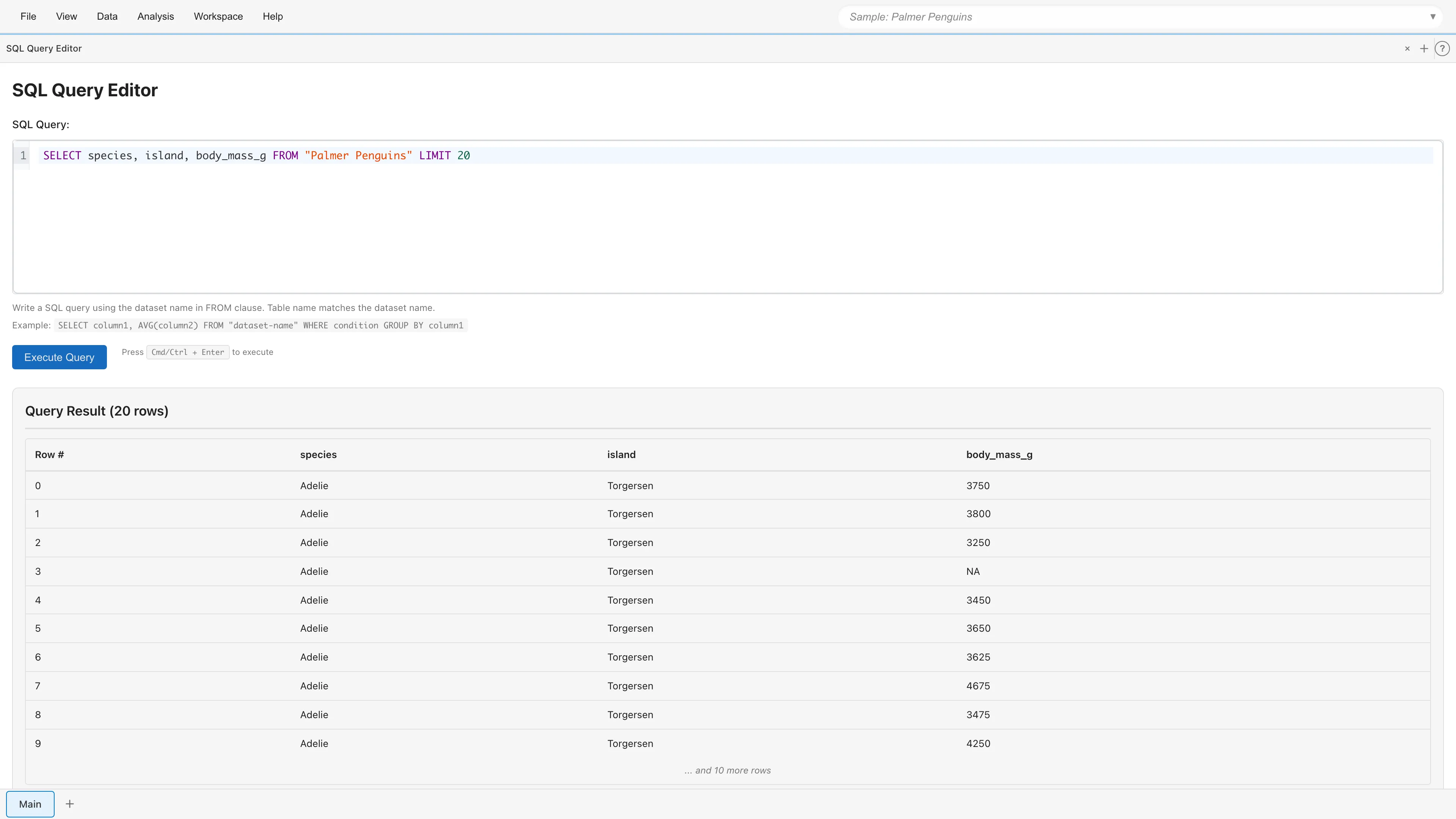
実行結果は「Query Result」セクションに表示されます。ヘッダーに全行数が表示され、最初の10行がプレビューとして表示されます。保存されるデータセットにはクエリ結果の全行が含まれます。
構文エラーや存在しないテーブル名・列名など、クエリに誤りがある場合は Execute Query ボタンの下にエラーメッセージが表示されます。クエリを修正して再実行してください。
クエリのキャンセル
クエリ実行中は Cancel Query ボタンが表示されます。このボタンをクリックするとクエリを中断できます。キャンセル後は新しいクエリを実行できます。
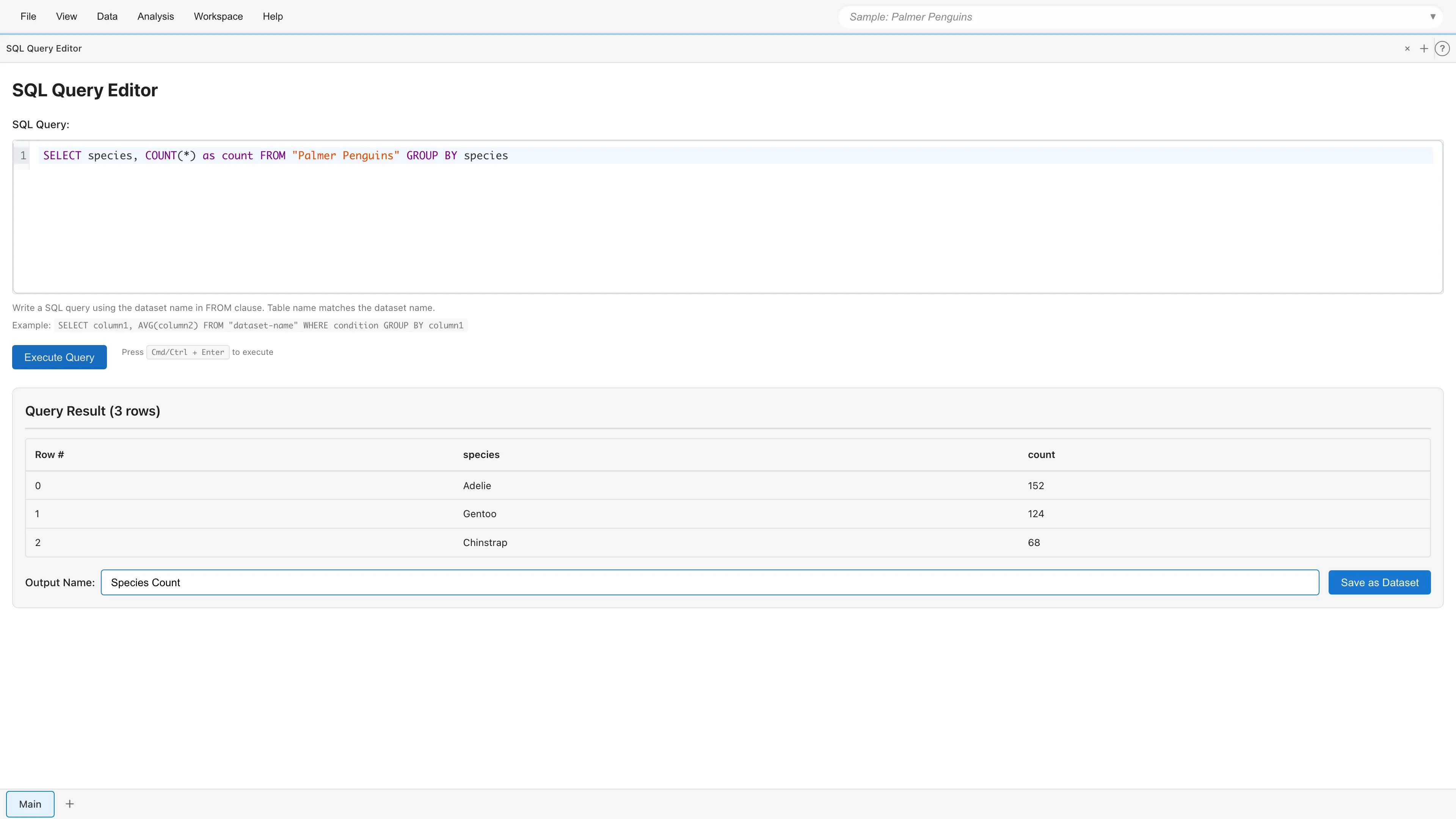
結果の保存
クエリ結果を新しいデータセットとして保存できます。Output Name 欄に新しいデータセット名を入力し、Save as Dataset ボタンをクリックすると、派生データセットがプロジェクトに追加されます。
既存のデータセットと同じ名前を入力した場合はダイアログが表示され、連番を付けた別名で保存する、名前を入力し直す、既存のデータセットを置き換える、のいずれかを選択できます。
クエリの書き方
基本的なクエリ例
特定の列だけを取得するには、SELECT 句で列名を指定します。
SELECT species, island, body_mass_g
FROM penguins
WHERE 句を使って条件に合う行だけを抽出できます。
SELECT *
FROM penguins
WHERE body_mass_g > 4000
GROUP BY 句と集計関数を組み合わせると、グループごとの集計ができます。
SELECT species, COUNT(*) as count, AVG(body_mass_g) as avg_mass
FROM penguins
GROUP BY species
ORDER BY 句で結果を並び替え、LIMIT 句で取得行数を制限できます。
SELECT *
FROM penguins
ORDER BY body_mass_g DESC
LIMIT 10
複数テーブルの結合
JOIN を使用して複数のデータセットを結合できます。
SELECT a.*, b.category
FROM sales a
JOIN products b ON a.product_id = b.id
同じ列構成のデータセットを縦に連結するには UNION ALL を使います。列の数と型が一致している必要があります。
SELECT * FROM sales_2024
UNION ALL
SELECT * FROM sales_2025
テーブル名について
プロジェクト内のデータセットを SQL のテーブルとして参照できます。テーブル名はデータセット名と一致するため、FROM 句にはデータセット名をそのまま書きます。データセット名は Project Overview で確認できます。データセットがまだない場合は、先に データの準備と読み込み に従ってデータをインポートしてください。
SELECT * FROM penguins
データセット名は大文字・小文字を区別しません。FROM penguins と FROM Penguins は同じデータセットに解決されます。ハイフンや空白などの特殊文字を含む名前はダブルクォートで囲む必要があります。
SELECT * FROM "bike-sharing"
サポートされる SQL 機能
MIDAS の SQL Editor は DuckDB(分析処理向けの SQL データベースエンジン)をベースにしており、標準的な SQL の機能が使えます。
- SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT
- INNER/LEFT/RIGHT/FULL/CROSS JOIN
- サブクエリ
- UNION、INTERSECT、EXCEPT
- ウィンドウ関数(ROW_NUMBER、RANK、LAG、LEAD 等)
- WITH 句による CTE(共通テーブル式)
- CASE 式
- 集計関数(COUNT、SUM、AVG、MIN、MAX、STDDEV 等)
詳細は DuckDB の SQL 構文ドキュメント を参照してください。
オートコンプリート
SQL Editor は入力中にオートコンプリート候補を表示します。表示される候補は入力位置によって切り替わります。
- データセット名: FROM または JOIN の直後で表示されます。
- 列名: FROM/JOIN で参照しているデータセットの列が、WHERE や SELECT などデータセット名を書く位置以外で表示されます。列名に加えて SQL キーワード(SELECT、FROM、WHERE、GROUP BY など)と集計関数(COUNT、SUM、AVG、MIN、MAX)も候補に含まれます。
テーブルエイリアスと修飾名
FROM "dataset" AS t または AS を省略した FROM "dataset" t の形式でテーブルエイリアスを指定できます。エイリアスに続けて t. と入力すると、そのデータセットの列名のみが候補として表示されます(SQL キーワードは混入しません)。
エイリアスを省略した場合は、データセット名をそのまま修飾名として使用できます。引用符付きの "dataset-name". と引用符なしの dataset. のどちらでも列名補完が表示されます。
補完を明示的にトリガーする
入力中に候補が自動表示されなかった場合は、Ctrl + Space で補完候補を明示的に呼び出せます。macOS では Cmd + Space が Spotlight で予約されているため、macOS でも Control + Space を使用します。
キーボードショートカット
| ショートカット | 動作 |
|---|---|
| Cmd/Ctrl + Enter | クエリを実行する |
| Ctrl + Space | 補完候補を明示的に表示する |
| Cmd/Ctrl + F | 検索する |
| Tab | インデントを挿入する |
Ctrl + Space は macOS でも同じキー組み合わせで動作します。Cmd + Space は macOS の Spotlight と競合するため割り当てていません。
派生データセット
SQL Editor で作成したデータセットは「派生データセット(Derived Dataset)」として保存されます。派生データセットは元のデータセットとの依存関係が記録され、Project Lineage タブで依存関係を確認できます。元データが更新されると、派生データセットのキャッシュは破棄され、次にデータが必要になったとき自動的に再計算されます(遅延評価とキャッシュ)。結果の列の測定尺度やデータ型は親データセットから引き継がれます。詳細は データセット を参照してください。
派生データセットの編集
既存の SQL で作成した派生データセットは編集できます。Project Lineage タブでデータセットを右クリックするか、Project Overview のデータセットのメニューボタン(⋮)から Edit Operation... を選択すると、SQL Editor が編集モードで開きます。
編集モードでは、他のデータセットやモデル、レポートがこの派生データセットに依存している場合、影響を受ける項目の種類と件数が警告として表示されます。クエリを変更して Execute Query で実行すると、結果プレビューに Update Query ボタンが表示されます。クリックすると変更が反映されます。このデータセットに依存する派生データセットは次にデータが必要になったとき再計算され、依存するモデルは自動的に再推定されます。
制限事項
MIDAS の SQL Editor は SELECT 文(データ取得)のみをサポートしています。INSERT、UPDATE、DELETE などのデータ変更や、CREATE TABLE などの DDL(テーブル定義)は使用できません。クエリは1つのステートメントのみ実行できます。セミコロンで区切った複数のクエリは使用できません。
ICU(タイムゾーン付き日時処理)と JSON の拡張は組み込み済みです。それ以外の DuckDB 拡張はロードされないため、httpfs 拡張に依存する read_csv('https://...') などで SQL クエリから外部 URL のデータを読み込むことはできません。外向きの通信はブラウザのセキュリティ機構でも遮断されています。詳細は プライバシーとセキュリティ を参照してください。ファイルや URL からデータを読み込む場合は Data > Import Data... メニューを使ってください。
また、ブラウザ上で動作するため、メモリ制限により非常に大きなデータセットの処理には制限があります。
See also
- データセット - Primary Dataset と Derived Dataset の違い
- データの準備と読み込み - CSV/TSV のインポート手順
- Reshape - GUI でのデータ形状変換
- 列の型変換 - データ型の手動変更
- Project Lineage - 依存関係の可視化
このページの Markdown 版もあります。