Random Forest(ランダムフォレスト)
Random Forest タブでは、ランダムフォレストによる分類と回帰ができます。複数の説明変数のうちどれが応答に効いているかを調べたいときや、説明変数から応答を予測したいときに使えます。ランダムフォレストはブートストラップ標本から複数の決定木を構築し、予測を集約するアンサンブル手法です(Breiman, 2001)。分類では各木の葉のクラス比率を全木で平均し、確率が最大のクラスを予測します。回帰では各木の予測値を平均します。応答変数の分布を仮定しないため、GLM のような分布ファミリーやリンク関数の選択は不要です。
基本的な使い方
Random Forest を開く
メニューバーから Analysis > Random Forest... を選択します。タブ上部の Fit / Predict ボタンで適合モードと予測モードを切り替えます。
変数の設定
以下の例では Iris データセットを使用しています。
Dataset で分析対象のデータセットを選択します。
Task Type でタスクの種類を選択します。
- Classification: 応答変数の値をクラスラベルとして扱います。全ての列型が選択できます
- Regression: 応答変数を連続値として扱います。間隔・比率尺度の数値列と boolean 型の列を選択できます
Response Variable (Y) で応答変数を選択します。Regression モードで選択できない列は "(requires conversion)" と表示されます。判定は 測定尺度 に基づくため、尺度を名義・順序に設定した列はデータ型が数値でも選択できません。
Predictor Variables (X) で説明変数を選択します。間隔・比率尺度の数値列と boolean 列を複数選択できます。boolean 列は尺度に関係なく選択でき、0/1 として扱われます。boolean 以外の名義・順序尺度の列と日付・日時型の列は選択できないため、事前に Dummy Coding タブで数値のダミー変数に変換してください。応答変数に選択した列は候補から自動的に除外されます。
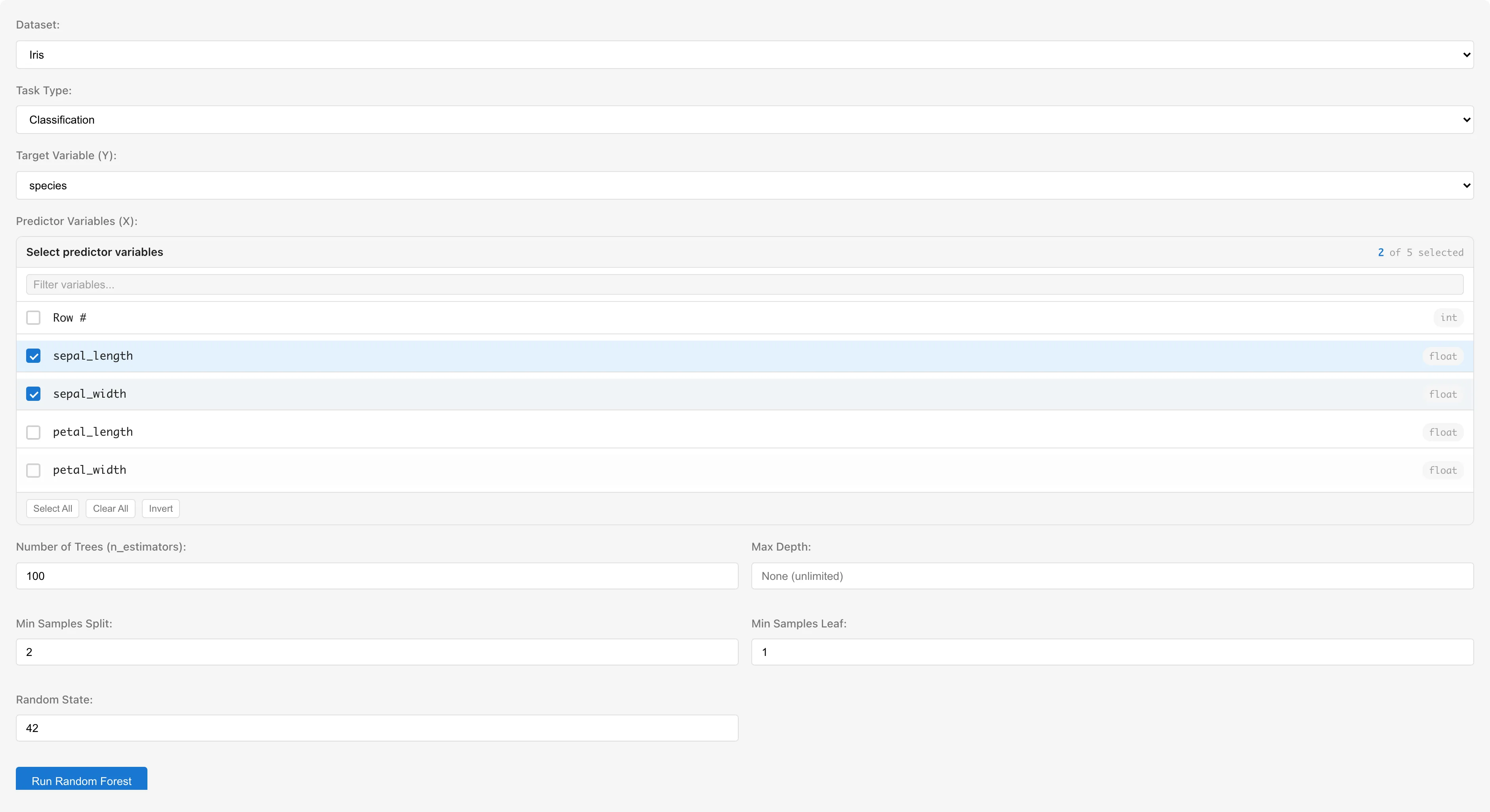
チューニングパラメータ
| パラメータ | UI 表記 | デフォルト | 説明 |
|---|---|---|---|
| nEstimators | Number of Trees | 100 | アンサンブルに含める決定木の数 |
| maxDepth | Max Depth | 空欄(無制限) | 各決定木の最大深さ。浅くすると過適合を抑制できます |
| minSamplesSplit | Min Samples Split | 2 | 内部ノードを分割するのに必要な最小サンプル数 |
| minSamplesLeaf | Min Samples Leaf | 1 | 葉ノードに必要な最小サンプル数 |
| randomState | Random State | 42 | 乱数シード。同じ値を指定すると同じ結果が再現されます |
各分割で考慮する説明変数の数は、分類・回帰とも ( は説明変数の総数)に固定されています。回帰では を使う実装もありますが、MIDAS では を採用しています。
分析の実行
設定が完了したら、Run Random Forest ボタンをクリックします。適合中は進捗メッセージが表示されます。
結果の見方
分類の指標
Task Type が Classification の場合に表示されます。
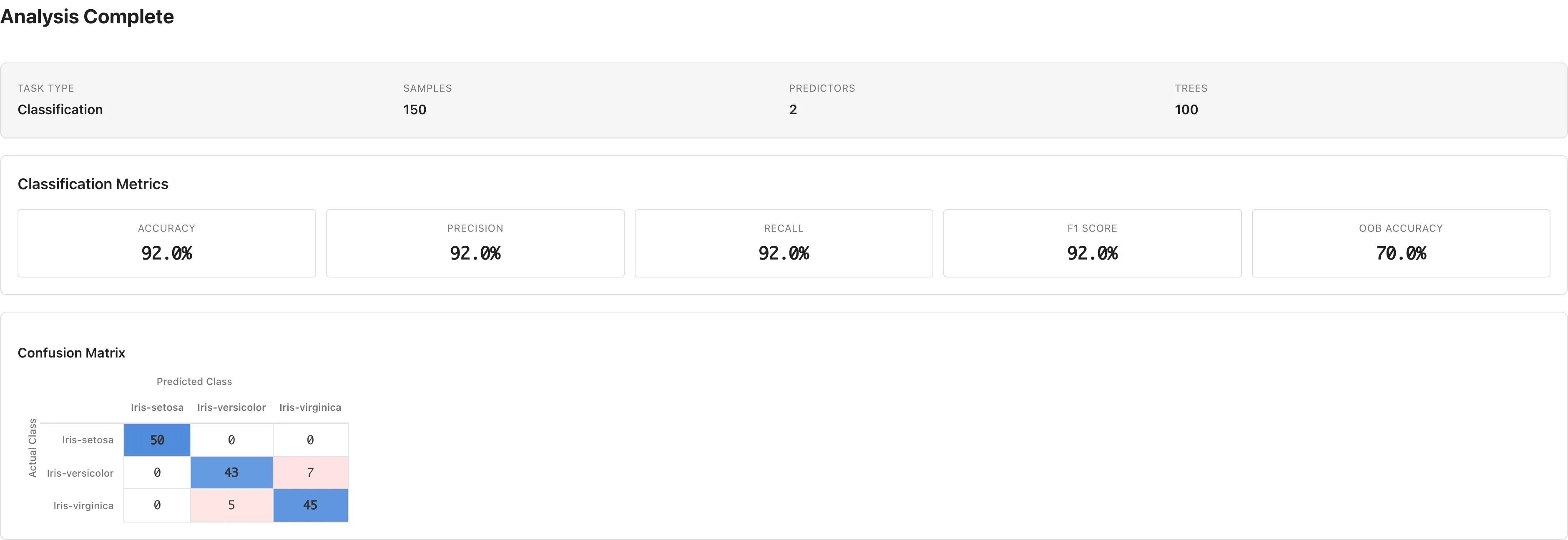
| 指標 | 説明 |
|---|---|
| Accuracy | 正しく分類されたサンプルの割合 |
| Precision | 各クラスの適合率(予測が陽性のうち実際に陽性の割合) |
| Recall | 各クラスの再現率(実際に陽性のうち正しく予測された割合) |
| F1 Score | Precision と Recall の調和平均 |
| OOB Accuracy | Out-of-Bag 正解率(OOB スコアを参照) |
2クラスの場合、Precision・Recall・F1 Score は混同行列の列順で2番目のクラスに対する値です。3クラス以上の場合はサンプル数による重み付き平均です。
Accuracy 等は適合データに対して計算されるため、過適合したモデルでも高い値が出ます。モデルの汎化性能は OOB Accuracy で判断してください。2クラス分類で Precision・Recall・F1 Score が意図したクラスに対する値かどうかは、混同行列の列順で確認できます。
混同行列
分類結果のすぐ下に混同行列が表示されます。行が実測クラス、列が予測クラスを表します。対角要素が正しい分類の数です。
回帰の指標
Task Type が Regression の場合に表示されます。
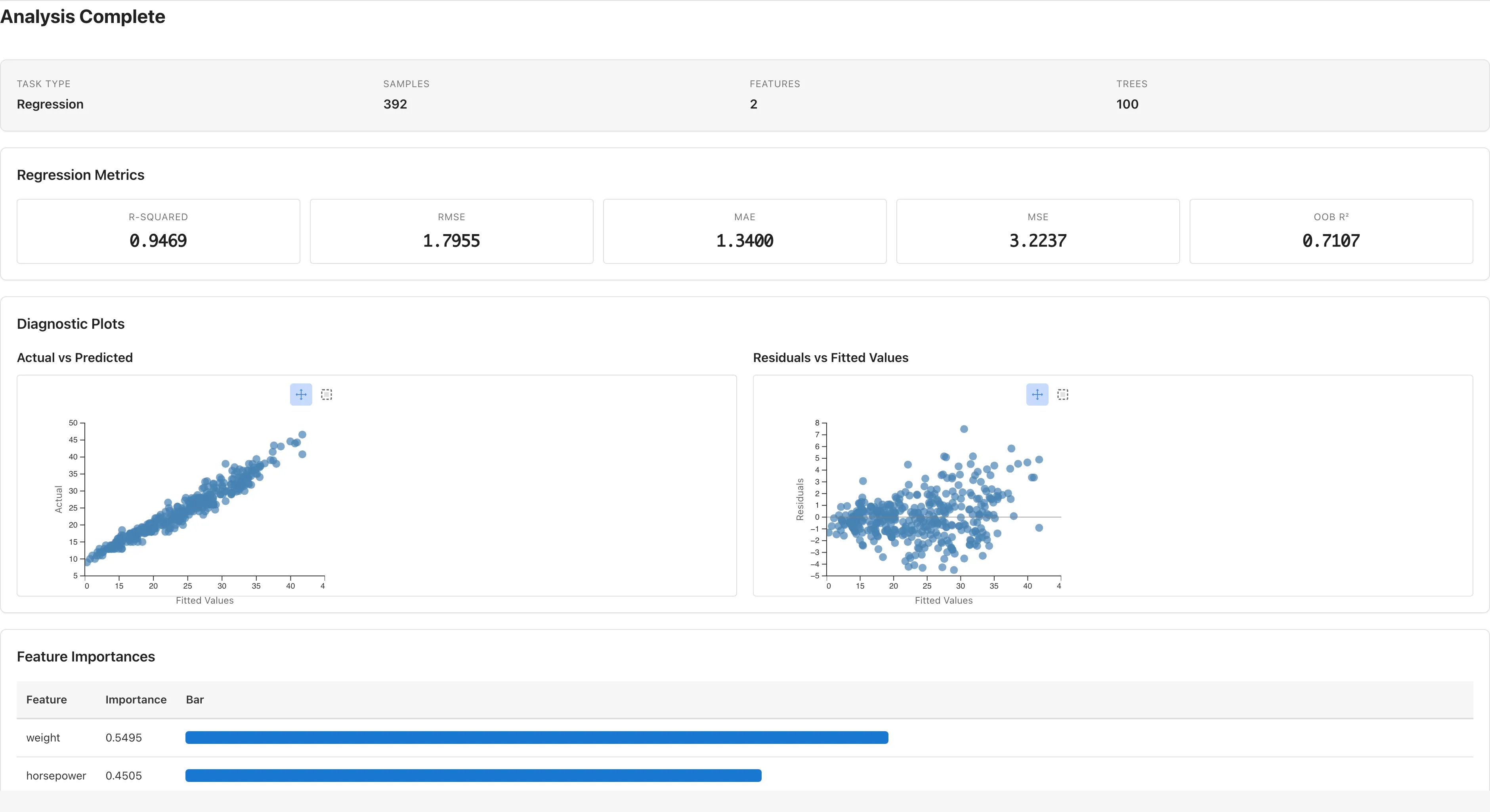
| 指標 | 数式 | 説明 |
|---|---|---|
| R-squared () | モデルが説明する応答変数の分散の割合 | |
| RMSE | 二乗平均平方根誤差 | |
| MAE | 平均絶対誤差 | |
| MSE | 平均二乗誤差 | |
| OOB | — | Out-of-Bag (OOB スコアを参照)。モデルの予測が平均値より悪い場合は負になります |
R² や RMSE などの指標は適合データに対して計算されるため、過適合したモデルでも高い値が出ます。モデルの汎化性能は OOB で判断してください。
診断プロット(回帰)
Regression モードでは2つの散布図が表示されます。これらは適合データに対する予測値と残差をプロットしたものです。
Actual vs Predicted: 横軸に予測値 、縦軸に実測値 をプロットします。データ点が対角線付近に集まっていれば、予測が実測に近いことを示します。
Residuals vs Fitted Values: 横軸に予測値、縦軸に残差 をプロットします。ゼロの水平線が表示されます。ランダムフォレストはデータに対して強くフィットするため、残差が小さくなりやすく、このプロットだけでは過適合を検出できません。モデルの汎化性能は OOB で判断してください。
プロット上でデータポイントをクリックまたは矩形選択すると、選択されたポイントの詳細(Row, Actual, Predicted, Residual)がプロット下部のテーブルに表示されます。
特徴量重要度
分類・回帰の両方で表示されます。各説明変数がモデルの予測にどれだけ寄与しているかを数値化した指標で、値が大きいほどその変数の寄与が大きいことを示します。重要度は予測への寄与の大きさを表す値であって、その変数が応答を変化させる因果効果を表すものではありません。また影響の方向(正の影響か負の影響か)も示しません。テーブルには MDI と Permutation の 2 種類の重要度が並び、棒グラフが付きます。連続変数を含む場合は、後述する MDI のバイアスを受けにくい Permutation を主に参照してください。テーブルは Permutation 降順でソートされます。

MDI(Mean Decrease in Impurity) は各説明変数がアンサンブル全体でもたらした不純度の減少量を集計し、合計が 1 になるよう正規化した値です。分類では Gini 不純度、回帰では分散を不純度の指標として使います。MDI は適合データ上の分割寄与度なので、ユニーク値が多い説明変数(連続変数など)ほど分割候補が増え、重要度が高く出やすくなります。逆に、カテゴリ変数を Dummy Coding で展開すると、元の 1 変数の重要度が複数のダミー列に分散して低く見えます。この場合は元の変数単位で重要度を解釈し、ダミー列ごとの値だけで重要・不要を判断しないでください。
Permutation は OOB Permutation Importance です。各説明変数について、OOB サンプル 上でその変数の値をサンプル間でランダムに並べ替え、変数と応答の関連を破壊したうえで予測精度の低下量を測定します。分類では accuracy の低下量、回帰では の低下量がツリーごとに計算され、全ツリーの平均が表示されます。MDI のように合計が 1 になるよう正規化せず、accuracy または の低下量そのものを表示します。MDI(不純度減少の相対寄与、合計 1)とは尺度が異なるため、同じ棒グラフ上で MDI と Permutation の値を直接比較しないでください。MDI と異なり OOB サンプルでの予測精度の変化を測定するため、ユニーク値の多い変数に対する MDI のバイアスが軽減されます。値が負になることもあり、その変数が予測に寄与していない可能性を示します。ただしツリー数が少ない場合は標本変動で負になることもあります。負の値は実質的に寄与なし(ゼロ近傍)とみなしてください。重要度がゼロと有意に異なるかを判定する検定は提供していません。負値が気になる場合は Number of Trees を増やすと標本変動が小さくなります。
ダミー変数展開による重要度の分散は MDI と同様に Permutation でも生じます。また説明変数間に強い相関がある場合、一方をシャッフルしてももう一方が代理変数として機能するため、相関した変数の Permutation Importance はいずれも過小評価される傾向があります。相関のある説明変数群では MDI も Permutation も個別変数の寄与を正しく分離できないため、重要度ランキングを変数選択や説明の根拠とするときは注意してください。
モデルの保存
結果の下部にある Model Name フィールドにモデル名を入力します。デフォルトでは "RF Classification - {データセット名} ({日付})" または "RF Regression - {データセット名} ({日付})" の形式で生成されます。
Save Model をクリックするとモデルがプロジェクトに保存されます。保存したモデルは Predict モードで使用できます。
予測
予測の実行
- タブ上部の Predict ボタンをクリックして予測モードに切り替えます
- Model ドロップダウンから保存済みモデルを選択します。モデルの情報(Task Type、説明変数の数、必要な説明変数名、分類の場合はクラス数)が表示されます
- Dataset for Prediction で予測対象のデータセットを選択します。モデルの説明変数名と同名の列を含むデータセットを選んでください
- Run Prediction をクリックします

予測結果
予測が完了すると、以下が表示されます。
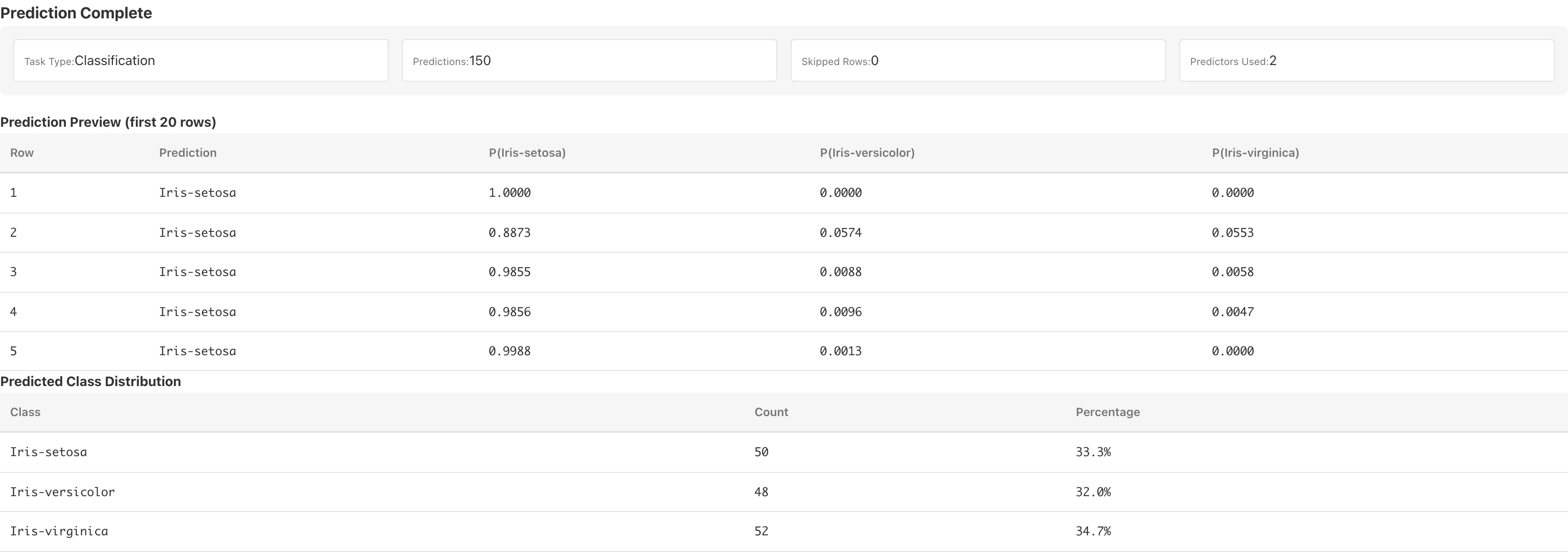
プレビューテーブル: 先頭20行の予測結果です。分類の場合は各クラスの予測確率 P(クラス名) も表示されます。この確率は各木の葉のクラス比率を全木で平均した値です。
Predicted Class Distribution(分類のみ): 予測されたクラスごとの件数と割合のテーブルです。
Prediction Statistics(回帰のみ): 予測値の要約統計量(Mean, Median, Std Dev, Min, Max)のテーブルです。
データセットとして保存
Save as Dataset をクリックすると、予測結果が派生データセットとして保存されます。
| 列 | 内容 |
|---|---|
| 説明変数列 | 元データセットからモデルの説明変数に一致する列 |
Prediction | 予測値。分類ではクラスラベル(string 型)、回帰では数値(float64 型) |
P(クラス名) | 各クラスの予測確率(分類のみ、float64 型) |
説明変数に欠損値がある行では、予測列は null になります。
注意事項
カテゴリ変数の使用
説明変数には間隔・比率尺度の数値列と boolean 列を使用できます。boolean は 0/1 として扱われます。名義・順序尺度のカテゴリ変数を使用するには、Dummy Coding タブで数値のダミー変数に変換してから分析します。
欠損値の自動除外
適合時には、選択した変数に欠損値(null)、非数値、無限大を含む行が自動的に除外されます。除外が発生した場合、結果の Samples に除外行数が表示されます。除外が多くても自動の警告は出ないため、Samples の除外行数を確認してください。この除外はリストワイズ除去に該当します。妥当な推定を与える条件については欠損データのメカニズムを参照してください。
予測時には、説明変数に欠損値がある行はスキップされ、予測列に null が設定されます。スキップされた行数は結果に表示されます。
Out-of-Bag (OOB) スコア
各決定木はブートストラップ標本(復元抽出、元データと同サイズ)で適合されます。OOB スコアは、各サンプルに対してそのサンプルを含まない木だけで予測を行い、集計した性能指標です。分類では正解率、回帰では を表示します。
各ブートストラップ標本には約 63.2% のサンプルが含まれ、残り約 36.8%(、 が大きいとき約 )が OOB として検証に回ります。別途の検証セットを用意せずに汎化性能を推定できます。OOB スコアが汎化性能の推定として妥当なのは、観測が独立に抽出されている場合です。小標本では推定が不安定になり、時系列・クラスタ・空間相関のあるデータでは汎化性能を過大に見積もりやすい点に注意してください。
制限事項
- ランダムフォレストの適合はブラウザ内の JavaScript で実行されます。データセットが大きい場合や木の数が多い場合、処理に時間がかかることがあります
- 交差検証やデータ分割検証は未提供です。汎化性能は OOB スコアで推定できます
- 各分割で考慮する説明変数の数(maxFeatures)は に固定されており、UI から変更できません
参考文献
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324
関連ページ
- 線形回帰分析 — パラメトリックな線形モデル
- 一般化線形モデル(GLM) — 分布の仮定を伴う回帰分析
- Dummy Coding — カテゴリ変数の数値変換
このページの Markdown 版もあります。