SQL Editor
SQL を使ってデータのフィルタリング、集計、結合ができます。
概要
SQL Editor は MIDAS 内のデータセットに対して SQL クエリを実行し、結果を新しいデータセット(派生データセット)として保存できる機能です。複数のデータセットを結合したり、複雑な条件でフィルタリングしたりする場合に便利です。
基本的な使い方
SQL Editor を開く
メニューバーから Data > SQL Query Editor を選択すると、新しい SQL Editor タブが開きます。
クエリの実行
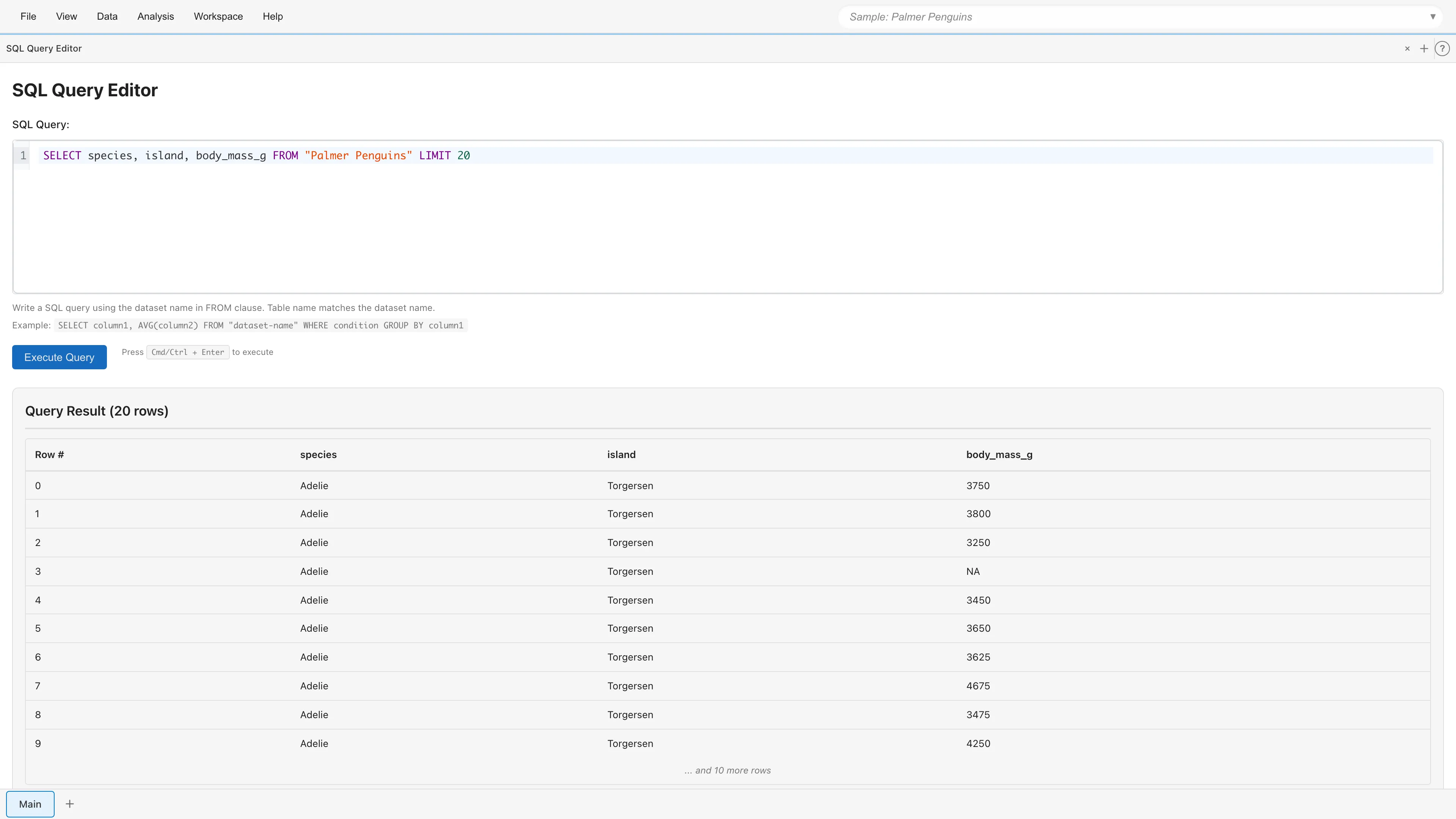
エディタに SQL クエリを入力し、Execute Query ボタンをクリックするか、Cmd/Ctrl+Enter を押すとクエリが実行されます。
実行結果は「Query Result」セクションに表示されます。最初の10行がプレビューとして表示され、結果が10行を超える場合は「... and N more rows」と表示されます。
クエリのキャンセル
クエリ実行中は Cancel Query ボタンが表示されます。このボタンをクリックするとクエリを中断できます。キャンセル後は新しいクエリを実行できます。
結果の保存
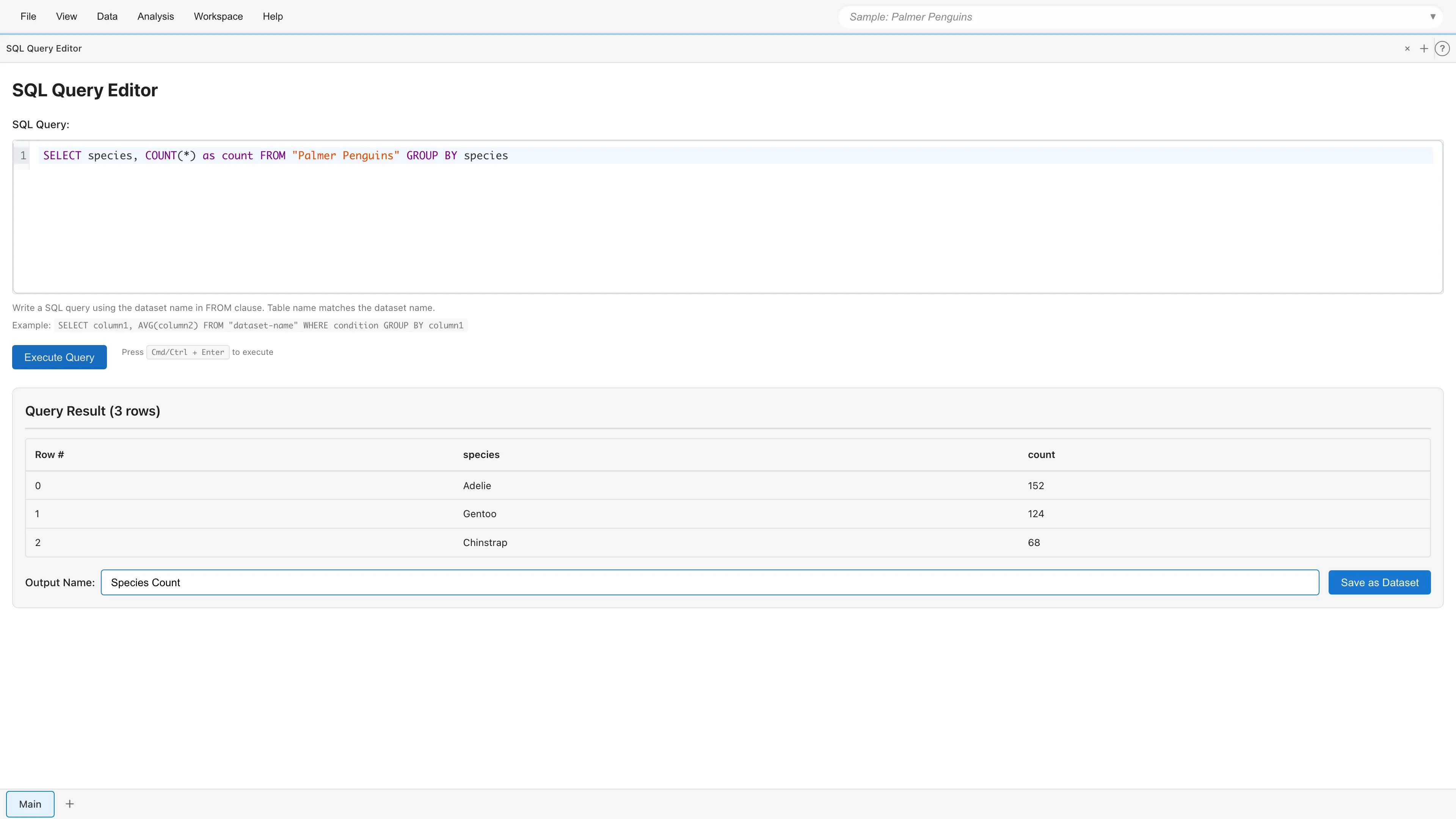
クエリ結果を新しいデータセットとして保存できます。Output Name 欄に新しいデータセット名を入力し、Save as Dataset ボタンをクリックすると、派生データセットがプロジェクトに追加されます。
クエリの書き方
基本的なクエリ例
特定の列だけを取得するには、SELECT 句で列名を指定します。
SELECT species, island, body_mass_g
FROM penguins
WHERE 句を使って条件に合う行だけを抽出できます。
SELECT *
FROM penguins
WHERE body_mass_g > 4000
GROUP BY 句と集計関数を組み合わせると、グループごとの集計ができます。
SELECT species, COUNT(*) as count, AVG(body_mass_g) as avg_mass
FROM penguins
GROUP BY species
ORDER BY 句で結果を並び替え、LIMIT 句で取得行数を制限できます。
SELECT *
FROM penguins
ORDER BY body_mass_g DESC
LIMIT 10
複数テーブルの結合
JOIN を使用して複数のデータセットを結合できます。
SELECT a.*, b.category
FROM sales a
JOIN products b ON a.product_id = b.id
テーブル名について
FROM 句には、プロジェクト内のデータセット名をそのまま使用できます。データセット名は Project Overview で確認できます。
SELECT * FROM penguins
データセット名は大文字・小文字を区別します。また、ハイフンや空白などの特殊文字を含む名前はダブルクォートで囲む必要があります。
SELECT * FROM "bike-sharing"
サポートされる SQL 機能
MIDAS の SQL Editor はDuckDBをベースにしており、標準的な SQL の機能をサポートしています。
- SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT
- INNER/LEFT/RIGHT/FULL/CROSS JOIN
- サブクエリ
- UNION、INTERSECT、EXCEPT
- ウィンドウ関数(ROW_NUMBER、RANK、LAG、LEAD 等)
- WITH 句による CTE(共通テーブル式)
- CASE 式
- 集計関数(COUNT、SUM、AVG、MIN、MAX、STDDEV 等)
詳細はDuckDB の SQL 構文ドキュメントを参照してください。
オートコンプリート
SQL Editor は入力中にオートコンプリート候補を表示します。
- データセット名(FROM 句で補完)
- SQL キーワード(SELECT、FROM、WHERE、GROUP BY 等)
- 集計関数(COUNT、SUM、AVG、MIN、MAX)
キーボードショートカット
| ショートカット | 動作 |
|---|---|
| Cmd/Ctrl + Enter | クエリを実行する |
| Cmd/Ctrl + F | 検索する |
| Tab | インデントを挿入する |
派生データセット
SQL Editor で作成したデータセットは「派生データセット(Derived Dataset)」として保存されます。派生データセットは元のデータセットとの依存関係が記録され、Project Lineage タブで依存関係を確認できます。元データが更新された場合は、派生データセットも再計算できます。
派生データセットの編集
既存の SQL で作成した派生データセットは編集できます。Project Lineage タブでデータセットを右クリックして「Edit SQL Query」を選択すると、SQL Editor が編集モードで開きます。
編集モードでは、他のデータセットやレポートがこの派生データセットに依存している場合、警告が表示されます。クエリを変更して Update Query ボタンをクリックすると、変更が反映されます。
制限事項
MIDAS の SQL Editor は SELECT 文(データ取得)のみをサポートしています。INSERT、UPDATE、DELETE などのデータ変更や、CREATE TABLE などの DDL(テーブル定義)は使用できません。
また、ブラウザ上で動作するため、メモリ制限により非常に大きなデータセットの処理には制限があります。
See also
- データセット - Primary Dataset と Derived Dataset の違い
- Reshape - GUI でのデータ形状変換
- 列の型変換 - データ型の手動変更
- Project Lineage - 依存関係の可視化