Two-Sample Test / Paired Test(独立2群検定 / 対応のある検定)
Two-Sample Test タブでは独立した2群の比較、Paired Test タブでは対応のある2群の比較を行います。それぞれパラメトリック検定(t 検定)とノンパラメトリック検定(順位検定)を選択できます。
基本的な使い方
タブを開く
メニューバーから Analysis > Two-Sample Test... または Analysis > Paired Test... を選択します。
検定の実行
左側の設定パネルで以下を順に設定します。
- Dataset から分析対象のデータセットを選択
- Test Method で検定手法を選択
- 変数を選択
- 必要に応じてオプションを設定
- Run Test をクリック
Two-Sample Test タブ
2つの独立したグループを比較します。Test Method で以下の2つから選択します。
Independent t-test(Welch の t 検定)
2つの独立したグループの母平均を比較します。
- 帰無仮説 : (2群の母平均は等しい)
- 対立仮説 : (両側検定の場合)
MIDAS では等分散を仮定しない Welch の t 検定を採用しています(Welch の t 検定と Student の t 検定の違い)。自由度は Welch-Satterthwaite 近似で算出するため、非整数になる場合があります。
Mann-Whitney U test(Mann-Whitney U 検定)
2群の分布を順位に基づいて比較するノンパラメトリック検定です。正規性を仮定しません。
- 帰無仮説 : 2群の分布が同一である
- 対立仮説 : 2群の分布が同一でない(両側検定の場合)
データの値を順位に変換して検定を行います。順序尺度のデータや、分布が正規分布から大きく逸脱しているデータに適しています。理論的な背景は順位検定(ノンパラメトリック検定)を参照してください。
変数の選択
Group Variable: グループを分けるカテゴリ変数(測定尺度が nominal または ordinal の列)を選択します。ちょうど2つのユニークな値を持つ必要があります。3つ以上のグループがある場合はエラーになります。一元配置分散分析には対応していません。
Outcome Variable: 比較したい数値変数(測定尺度が interval または ratio の列)を選択します。
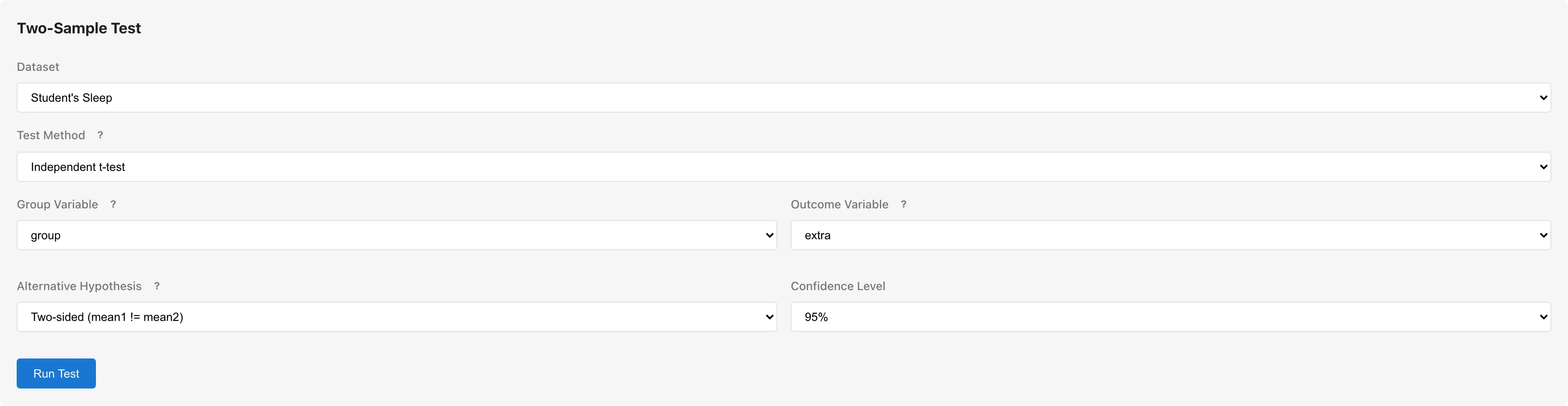
使用例
Student's Sleep サンプルデータで、2種類の催眠薬(Drug 1、Drug 2)の睡眠時間増分に差があるかを検定する場合:
- Dataset: Student's Sleep
- Test Method: Independent t-test
- Group Variable:
group - Outcome Variable:
extra - Run Test をクリック
Paired Test タブ
同一対象から得られた2つの測定値を比較します。Test Method で以下の2つから選択します。
Paired t-test(対応のある t 検定)
同一対象から得られた2つの測定値の差を検定します。治療前後の測定値、同一サンプルの異なる特性の比較などに使用します。
- 帰無仮説 : (差の母平均はゼロ)
- 対立仮説 : (両側検定の場合)
内部的には各ペアの差 を計算し、 に対する1標本 t 検定を実施しています。
Wilcoxon signed-rank test(Wilcoxon 符号順位検定)
対応のある2群の差を順位に基づいて検定するノンパラメトリック検定です。正規性を仮定しません。
- 帰無仮説 : 差の分布がゼロに対して対称である
- 対立仮説 : 差の分布がゼロに対して対称でない(両側検定の場合)
各ペアの差 を計算し、差がゼロのペアを除外した上で、差の絶対値の順位に符号を付けて検定を行います。理論的な背景は順位検定(ノンパラメトリック検定)を参照してください。
変数の選択
Variable 1 と Variable 2 にそれぞれ比較したい数値変数を選択します。
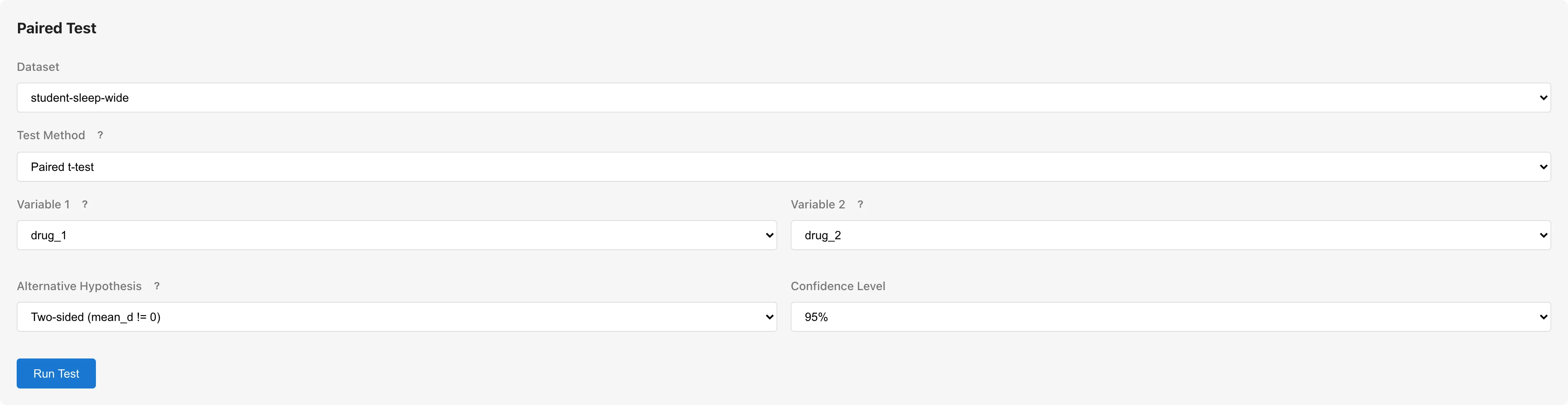
使用例
同じ Student's Sleep サンプルデータで、同一被験者に投与した2種類の催眠薬の効果を比較する場合。各被験者が両方の薬を服用しているため、対応のある検定が適切です。
対応のある検定では Variable 1 と Variable 2 に別々の列が必要です。Student's Sleep サンプルデータはロング形式のため、Reshape でワイド形式に変換するか、ワイド形式の CSV を読み込んでください。
- Dataset: Student's Sleep(ワイド形式)
- Test Method: Paired t-test
- Variable 1:
drug_1 - Variable 2:
drug_2 - Run Test をクリック
オプション設定
以下のオプションはすべての検定手法で共通です。
Alternative Hypothesis(対立仮説)
t 検定では , は2群の母平均、 は差の母平均を表します。ノンパラメトリック検定では仮説は分布の位置や対称性に関するものですが、対立仮説の方向は同じ意味で適用されます。
| 選択肢 | Two-Sample Test | Paired Test | 説明 |
|---|---|---|---|
| Two-sided | 差の方向を問わない。デフォルト | ||
| Less | 片側検定。Variable 1 の方が小さいと仮定 | ||
| Greater | 片側検定。Variable 1 の方が大きいと仮定 |
片側検定は検出力が高くなる一方、反対方向の差を検出できません。事前に方向性の仮説がある場合にのみ使用してください。
Confidence Level(信頼水準)
平均差の信頼区間の幅を決定します。90%、95%(デフォルト)、99% から選択できます。t 検定の結果に適用されます。
結果の読み方
結果パネルの上部に と が表示されます。その下に、設定した有意水準での結論が文章で示されます。主要統計量、信頼区間、効果量、グループ統計量がカードで表示されます。
結果ヘッダー右側のメニューボタン(...)から Copy APA format を選択すると、APA スタイルの結果文をクリップボードにコピーできます。
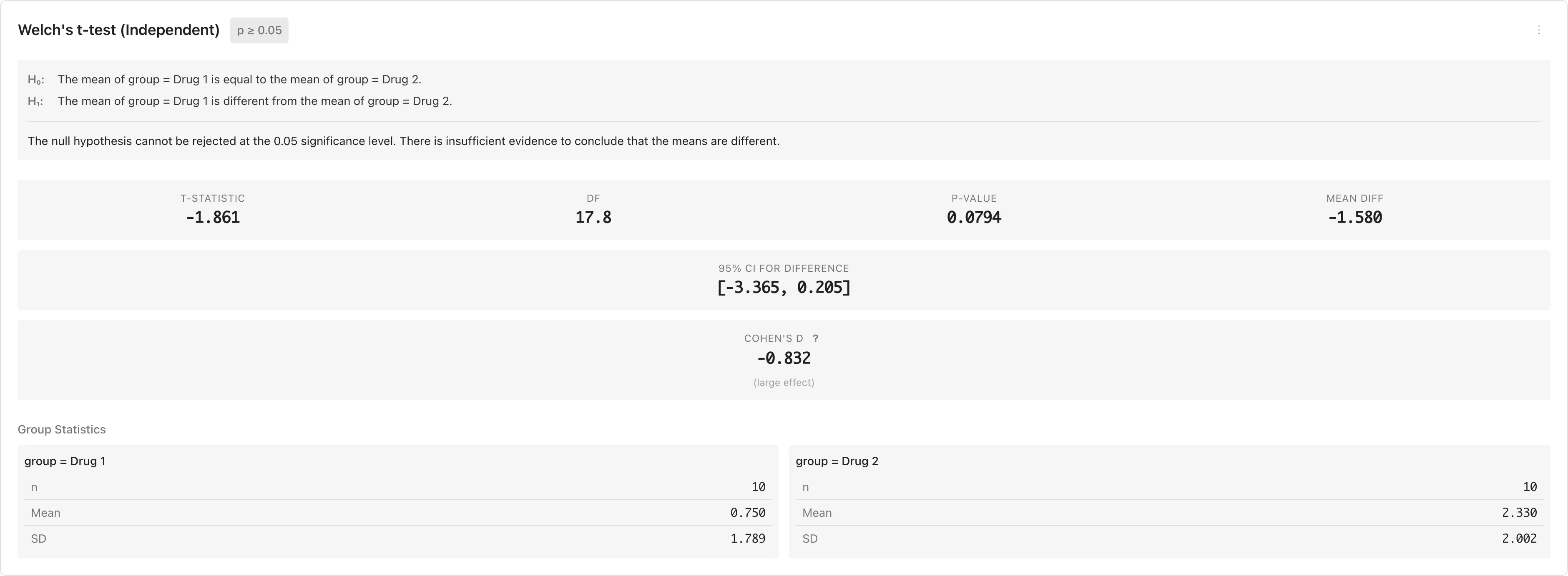
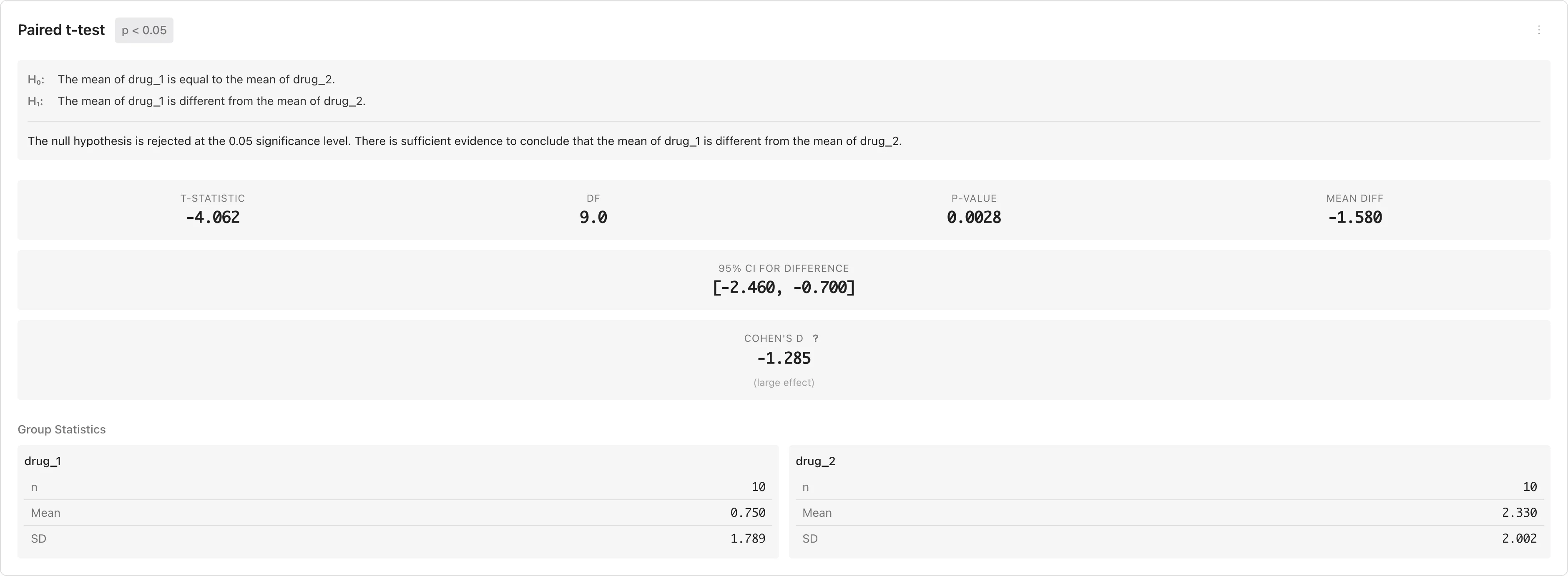
t 検定の結果
| 統計量 | 説明 |
|---|---|
| t-statistic | t 統計量 |
| df | 自由度。独立 t 検定では Welch-Satterthwaite 近似により非整数になりうる。対応 t 検定では |
| p-value | p 値。有意水準 より小さければ を棄却する |
| Mean diff | 平均差。独立 t 検定では 、対応 t 検定では |
| 95% CI | 平均差の信頼区間。区間が0を含まなければ を棄却できる(両側検定の場合) |
| Cohen's d | 平均差を標準偏差で割った標準化効果量。独立 t 検定ではプールされた標準偏差、対応 t 検定では差の標準偏差を使用。詳細は仮説検定の考え方を参照 |
ノンパラメトリック検定の結果
| 統計量 | 説明 |
|---|---|
| U statistic | Mann-Whitney U 統計量。一方の群の各観測値がもう一方の群の各観測値よりも大きい回数を表す |
| W+ / W− | Wilcoxon signed-rank 検定の正の順位和と負の順位和 |
| z-score | 正規近似による z スコア。サンプルサイズが大きい場合に検定統計量を標準正規分布で近似する |
| p-value | p 値。有意水準 より小さければ を棄却する |
| rank-biserial r | 順位に基づく効果量。値の範囲は −1 から +1 で、0 は効果なしを意味する。詳細は順位双列相関 rを参照 |
独立 t 検定の結果
対応 t 検定の結果
診断情報
検定を実行すると、結果の下に診断パネルが表示されます。t 検定の正規性の仮定と診断の考え方は仮説検定の考え方を参照してください。
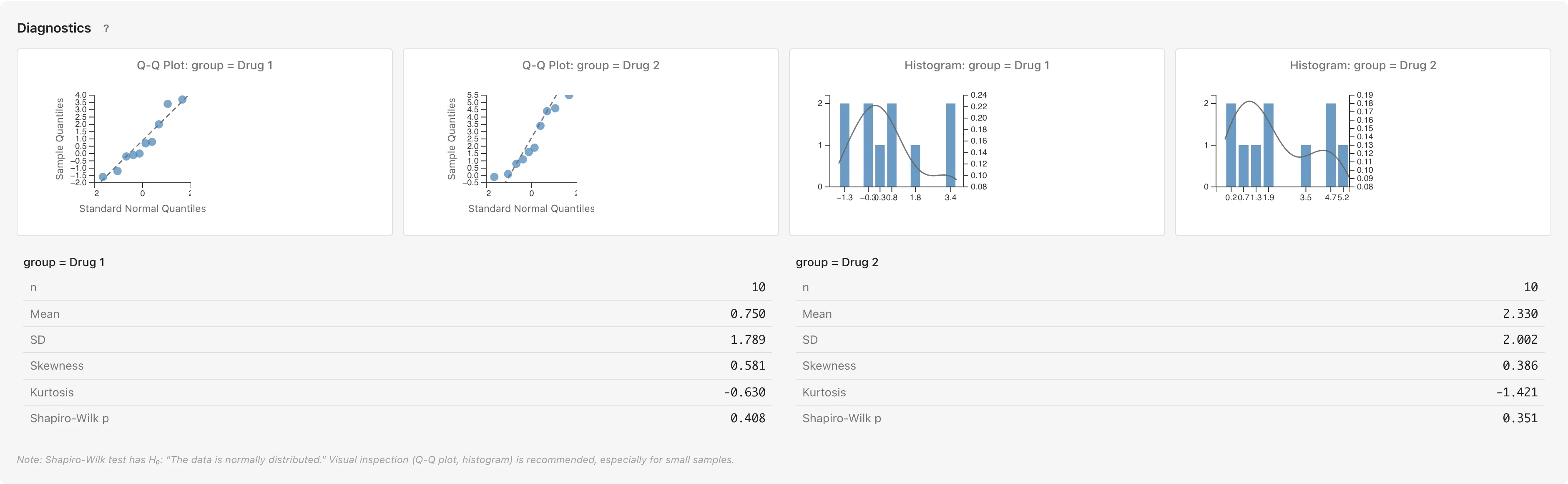
診断パネルには Q-Q プロット、ヒストグラム、記述統計量(n、Mean、SD、Skewness、Kurtosis)、Shapiro-Wilk 正規性検定が含まれます。Q-Q プロットではデータ点が対角線の近くに並んでいれば正規分布に近いと判断でき、裾の系統的な逸脱は歪みや重い裾を示唆します。ヒストグラムはデータ分布の形状を視覚的に確認できます。記述統計量の Skewness と Kurtosis は正規分布で0になり、0から離れるほど逸脱が大きいことを示します。Shapiro-Wilk 検定は 「母集団は正規分布に従う」を検定しますが、大標本では微小な偏差でも有意になるため、Q-Q プロットと併せて判断してください。
ノンパラメトリック検定では正規性は検定の前提条件ではありませんが、データの分布を理解するための参考情報として診断パネルは同様に表示されます。
独立2群検定の診断
各群(Group Variable の値ごと)について Q-Q プロット、ヒストグラム、記述統計量、Shapiro-Wilk 検定が表示されます。
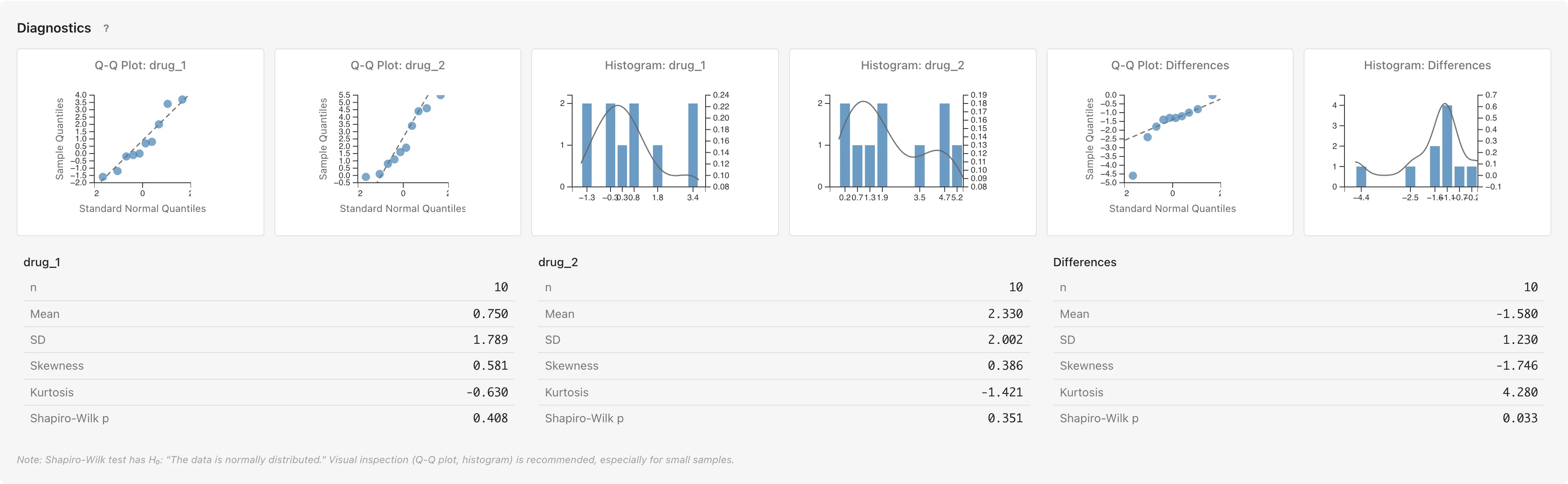
対応のある検定の診断
各変数(Variable 1、Variable 2)の診断に加えて、差(Differences) の診断が表示されます。差は Variable 1 − Variable 2 で計算されます。
対応のある t 検定は内部的に差 に対する1標本 t 検定を行うため、検定の妥当性に直接関わるのは各変数の正規性ではなく差の正規性です(正規性の仮定)。Wilcoxon signed-rank 検定では差の正規性は前提条件ではありませんが、差の分布の対称性を確認する参考情報として表示されます。
行選択との連携
診断パネルのグラフから、データの行を選択できます。
Q-Q プロットから選択
Q-Q プロットの点をクリックすると、対応するデータの行が選択されます。Ctrl(Mac: Cmd)キーを押しながらクリックすると、既存の選択に追加できます。
ヒストグラムから選択
ヒストグラムのバーをクリックすると、そのビンに該当するデータの行が選択されます。Ctrl(Mac: Cmd)キーを押しながらクリックすると、既存の選択に追加できます。
Filtered Data タブを開く
ヒストグラムのバーをダブルクリックすると、選択されたデータを表示する Filtered Data タブが開きます。
欠損値の処理
欠損値(NaN、Infinity)を含む行は自動的に除外されます。除外された行数は結果パネルに表示されます。対応のある検定では、いずれかの変数に欠損値を含むペアが除外されます。
他の検定手法
カイ二乗独立性検定は Crosstab(クロス集計)で実行できます。一元配置分散分析(ANOVA)には対応していません。
参考文献
- Welch, B. L. (1947). The generalization of "Student's" problem when several different population variances are involved. Biometrika, 34(1-2), 28-35.
- Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2nd ed., pp. 25-27). Lawrence Erlbaum Associates.
- Shapiro, S. S., & Wilk, M. B. (1965). An analysis of variance test for normality (complete samples). Biometrika, 52(3-4), 591-611.
- Mann, H. B., & Whitney, D. R. (1947). On a test of whether one of two random variables is stochastically larger than the other. Annals of Mathematical Statistics, 18(1), 50-60.
- Wilcoxon, F. (1945). Individual comparisons by ranking methods. Biometrics Bulletin, 1(6), 80-83.